
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- kt디지털인재
- ResNet
- sparse coding
- 논문 리뷰
- Data Augmentation
- Deep Learning
- VGG16
- data analysis
- SRCNN
- Tableau
- kt희망나눔재단
- 장학프로그램
- Computer Vision
- 태블로 실습
- Attention
- 데이터 시각화
- 개 vs 고양이
- cnn
- 데이터 증강
- super resolution
- k-fold cross validation
- 태블로
- 논문리뷰
- tcga
- 데이터 분석
- 딥러닝
- 데이터과학
- 머신러닝
- 파이썬 구현
- Semantic Segmentation
- Today
- Total
기억의 기록(나의 기기)
[Computer Vision] Deep learning for classification and localization of early gastric cancer in endoscopic images 논문 리뷰 + 이해를 돕기 위한 추가 자료 본문
[Computer Vision] Deep learning for classification and localization of early gastric cancer in endoscopic images 논문 리뷰 + 이해를 돕기 위한 추가 자료
황경하 2024. 11. 15. 12:48[Segmantic Segmentation] Deep learning for classification and localization of early gastric cancer in endoscopic images
안녕하세요, 데이터 과학 전공하고 있는 황경하입니다.
오늘은 컴퓨터 비전 영역에서 많은 연구가 이루어지고 있는 의미론적 분할 (Semantic Segmentation) 논문에 대해 리뷰해보려 합니다. 최근에 위암 조기 진단에 관한 논문들을 찾아보고 있는데, 그중에 Attention 모듈을 도입한 논문들이 많더라고요. 그래서, 오늘은 Attention 모듈을 이용하며, 성능 또한 SOTA보다 높게 달성한 두 가지 모델을 제안하는 논문을 리뷰해 볼까 합니다.
* 리뷰할 논문: https://www.sciencedirect.com/science/article/pii/S1746809422006541
Deep learning for classification and localization of early gastric cancer in endoscopic images
Gastric cancer, as a malignant tumor, is one of the most common cancer-related deaths worldwide with high mortality and incidence rates. Therefore, th…
www.sciencedirect.com
* 해당 글에 첨부된 사진들은 모두 위 논문에서 발췌한 것임을 미리 밝힙니다.
* 해당 글에 설명은 논문을 기반으로 한 주관적 해석이므로 틀린 부분이 있다면, 댓글로 지적 부탁드립니다!
#Abstract
위암은 높은 발병률과 사망률을 가지는 병입니다. 따라서, 조기 발견을 위한 내시경 검사가 필수적으로 요구됩니다. 이에 본 논문에서는 딥러닝 기반 Early gastric cancer (EGC) 자동 진단 방법을 제안한합니다. ResNet-50에서 파생된 guided-attention deep network를 도입하여 예측 성능과 특징 정보를 잘 추출하게 설계되었으며 경량화된 어텐션 모듈과 다중 스케일 특성 추출기를 U-Net과 결합하여 EGC 병변 영역의 픽셀 레벨 분할을 추정합니다. (말이 어려울 수 있는데 아래에 설명이 있으니 끝까지 읽어주시면 이해하실 수 있을 겁니다.) 결과는 정확도 98.48%, IOU 0.64로 분류 및 분할 작업에서 탁월함을 보여줌으로써 EGC 진단에 딥러닝의 응용 가능성을 보여줍니다.
#Introduction
위암은 사망률이 높지만, 조기 발견 시 5년 생존율이 90%가 넘습니다. 그러나, 조기 발견을 위해 내시경을 사용할 시 국소적 점막 변화만 보이기에 의사의 경험에 많이 의존하게 됩니다. 중국에서 보고된 바에 따르면, 내시경으로 검사 시 평균 검출률은 2~5%에 불과하며 오진율이 약 10%라고 합니다. 이에 AI를 이용한 위암 진단으로 의사의 판단을 지원하여 검출률을 높이고자 합니다. CNN은 인간과 달리 픽셀 단위로 보기 때문에 인간이 인식하기 어려운 미세 구조까지 추론할 수 있는 이점을 가지고 있기에 AI를 이용하는 것이 도움이 될 것이라 기대하고 있습니다.
관련 연구는 많이 제안이 됐지만, 요약하면 아래와 같습니다. (제안된 논문과 큰 연관성이 없어 간단히 짚고 넘어가겠습니다.)
- 딥러닝 기반 진단 시스템 개발 → 실시간, 정적 이미지 모두 sensitivity 92.2%
- Weakly supervised CNN → AUC 96%
- Pretrained CNN 모델 → Accuracy 87.6%, specificity 94.8 %, sensitivity 80%
- GRAIDS → Accuracy 95%
EGC CAD(컴퓨터를 이용한 위암 조기 검출) 관련 연구
- Inception-v3 모델: sensitivity 90.64%와 accuracy 90.91%
- VGG-19: accuracy 77%
- GoogLeNet: accuracy 85.1% *이는 전문의와 동등하거나 높은 수준으로 매우 잘 예측한 것입니다.
그러나, 위 연구는 ME-NBI로 관찰된 위 점막 병변 데이터셋을 사용하여 수행되었습니다. 이는 적용 범위가 제한적이고 일반적인 내시경 검사에 적합하지 않습니다. 즉, 위 연구는 실생활에 적용하기 어렵다. 이에 본 연구는 다양한 내시경 이미지의 검출 및 인식을 위한 CNN 시스템을 구축했습니다.
# Proposed Architecture
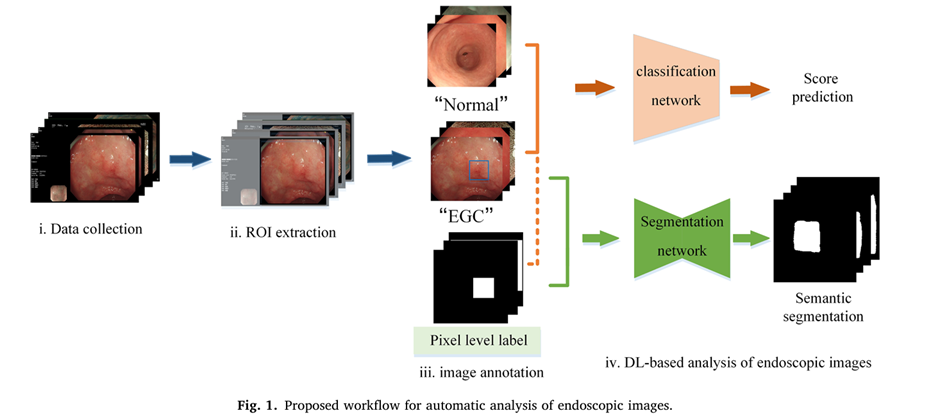
Fig 1은 논문에서 제안한 WorkFlow입니다. 각 단계를 상세히 살펴보겠습니다. (Fig 1과 비교하며 따라오시면 더 이해가 쉬우실 겁니다.)
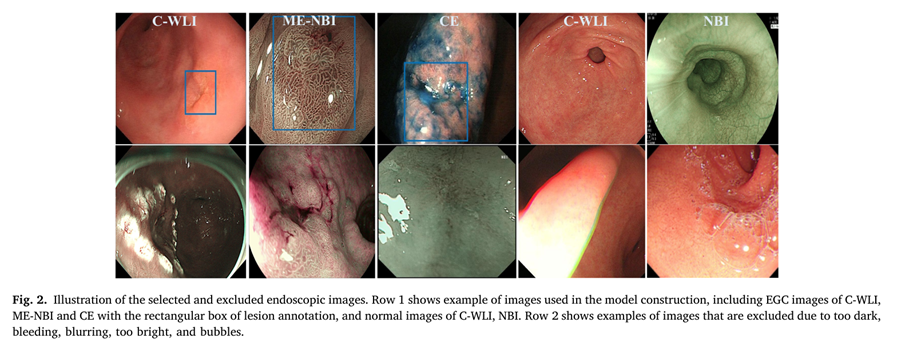
1) Data Collection: 사전에 준비된 데이터셋에서 어둡거나, 밝거나, 거품, 출혈 등의 노이즈가 많은 이미지는 제외하여 데이터셋을 재구축한다. 예시는 아래 Fig 2와 같습니다.
Fig 2를 보면, 1행은 노이즈가 많이 포함되지 않은 이미지로 연구에 사용할 수 있는 이미지입니다. 그러나, 2행을 보면, 너무 어둡거나, 밝거나, 거품, 출혈 등의 노이즈가 있는 것을 알 수 있습니다. 본 논문에서는 이러한 노이즈를 제거하기보다는 데이터 자체를 삭제하는 방향을 선택하였습니다.
2) ROI extraction: 구축된 데이터셋은 많은 내시경 장비로 추출되었고, 동시에 해상도가 제각각이기에 ROI를 통해서 이를 정상화합니다. ROI는 임계값 설정과 실시간 경계 영역 조정 방식을 사용하는데, 임계값 설정 방식은 특정 임계값을 설정한 후 그 임계값보다 픽셀값이 작으면 배경으로 인식하고, 크면 병변 영역으로 인식하여 병변 영역을 추출하는 단계입니다. 이렇게 추출된 병변 영역을 실시간으로 확인하여 조정하는 과정을 거쳐 정확도를 높입니다.
3) Image annotation: 주석은 전체 이미지에 대한 레이블과 픽셀 수준 레이블로 나누어집니다. 이미지 수준 레이블은 단순히 그 이미지가 정상인지, EGC인지에 대한 레이블이다. 즉, 이미지 자체에 대한 레이블입니다. 픽셀 수준 레이블은 ROI를 통해서 추출된 병변 영역을 배경과 분리하여 마킹된 이미지를 말합니다. 즉, 2번 과정을 거친 병변 영역이 포함된 이미지에서 배경과 병변 영역을 분리한 레이블을 말합니다.
4) DL-based anlysis of endoscopic images: 이렇게 주석된 이미지를 두 가지 태스크에 적용합니다. 첫 번째로, 이미지 수준 레이블된 이미지들은 EGC인지, 정상인지를 판별하는 딥러닝 모델에 들어가게 됩니다. 두 번째로, 픽셀 수준 레이블된 이미지는 실제 이미지와 함께 Segmentation network에 들어가 병변 영역만 분리하게 됩니다.
#Data Preparation
데이터는 2016년 6월 ~ 2021년 5월 사이에 EGC 1494개의 이미지와 3203개의 이미지로 구성됩니다. 레이블은 경력 5년 이상의 전문의 3명의 판단 하에 결정되었습니다.
#DL-based analysis of endoscopic images
여기서 부터는 각 데이터가 모두 전처리되었다 생각하고, DL 모델에 넣어 각 태스크 (Classification, Semantic Segmenation)을 수행하는 방법을 설명합니다.
## Image recognition
기본 구조는 GAIN-ResNet-50(ResNet50 + Attention Module) 모델을 사용합니다. Input Image와 픽셀 수준 레이블 이미지가 들어가게 되면, Input Image는 ResNet50의 구조에 따라 Conv층을 통과하게 되고, FC layer에 입력하기 직전의 피처맵을 Attention map으로 활용합니다. 이 Attention map은 픽셀 수준 레이블과 비교하여 모델이 어느 병변 영역에 집중해야 하는지를 학습하게 됩니다. 이를 통해 모델은 전체 이미지를 보고 EGC와 Normal을 판단하게 되며, 동시에 병변 영역을 찾는 태스크를 수행하게 된다. 이에 Classification이 아닌 Recognition이라는 표현을 논문에서 사용하였습니다.
이렇게 Attention 모듈을 학습에 넣어서, 모델이 어느 영역에 더 집중해야 하는지를 알려주게 되어 모델의 예측 성능이 향상됩니다. 마치 과녁이 있다면, 10점 위치를 알려주고 "여기를 쏴!" 하고 사격을 하는 것과, 10점 영역이 어디인지 모르는 사람이 그냥 사격을 할 때 점수 차이가 나는 것과 같습니다. 그리고, 이 Attention Map은 모델을 설명하는 XAI 영역에도 사용될 수 있으며 CAM이라는 개념에서 사용될 수 있습니다.
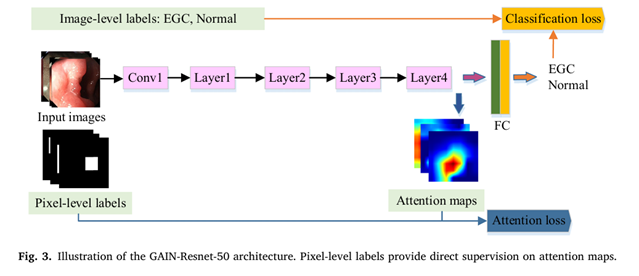
### Image Recognition의 Loss function
1) Classification Loss: Input image를 EGC인지 Normal(음성)인지를 분류하는 태스크는 기존 이진 분류로 사용하던 Cross Entropy loss를 사용하여 계산됩니다.
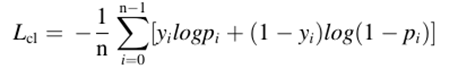
2) Attention Loss: Attention Map (FC Layer 직전의 Feature Map) 과 ROI를 통해 추출된 픽셀 수준 레이블과의 MSE Loss로 정의됩니다.
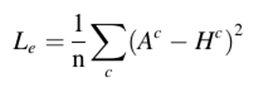
최종적인 Loss function 은 1번과 2번을 합하여 계산되며 가중치를 부여하여 계산되는데, 논문에서는 a = 0.9, B = 0.1을 주었습니다.
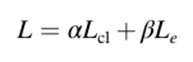
### Metrics
평가 지표는 정확도, 정밀도, 재현율, 민감도, F1-score로 아래와 같다. (이는 분류 문제에서 정말 많이 쓰이는 지표이니 모르시는 분들은 익혀두시길 바랍니다.)

### Result
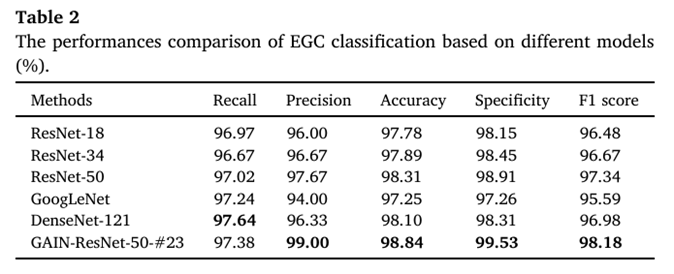
훈련은 초기 학습률이 1e-3인 Adam optimizer를 사용, 80 epoch,배치 크기는 4, 이미지 크기는 224 X 224 X 3으로 변환하여 사용하였으며, pretrained weight를 이용하여 전이 학습 및 미세 조정을 수행했습니다. 아래 Table 2를 보면, GAIN-ResNet-50 모델이 EGC와 Normal을 분류하는 사전 학습 모델들 중 가장 높은 성능을 보임을 알 수 있습니다.
## Segmentation location
병변 영역을 찾는 태스크를 수행합니다. 기본적인 구조는 U-Net을 기반으로 하여 진행됩니다. Input은 픽셀 수준 레이블 데이터와 실제 EGC 데이터가 들어가게 됩니다. 전체적인 아키텍처는 아래와 같습니다.
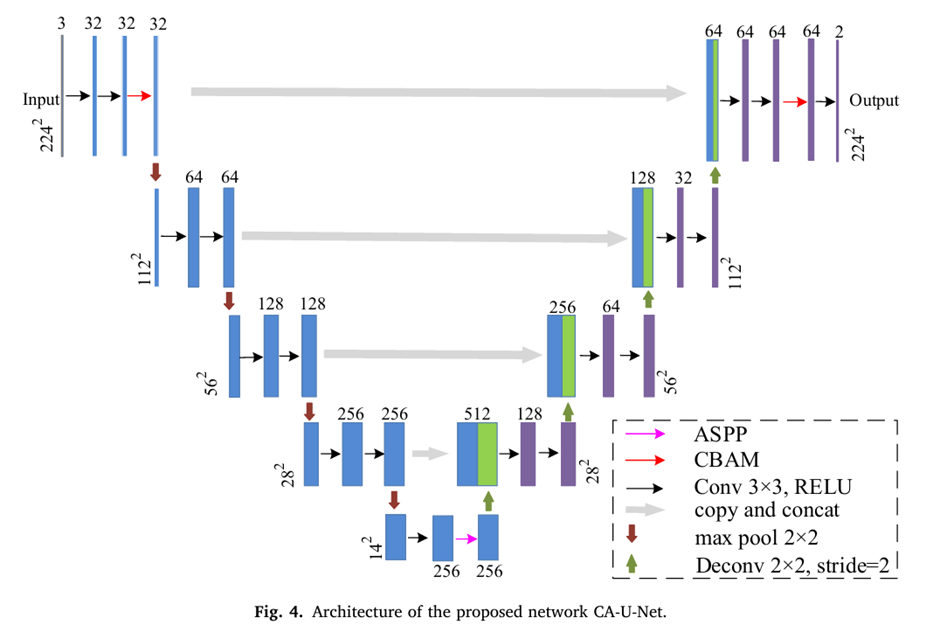
본 논문에서는 위와 같은 CA-U-Net을 제안했는데, 이는 기존 U-Net에 CABM 모듈과 ASSP 모듈을 합친 모델입니다.
### CBAM 모듈 (논문에 깊은 설명이 없어, 추가하였습니다.)
논문에서는 ”주어진 중간 특징 맵에 대해 CBAM은 채널과 공간의 두 차원에 따라 어텐션 가중치를 추론한 다음 원래의 특징 맵과 곱하여 특징을 적응적으로 조정합니다.”라고 적혀있지만, 잘 이해가 안 가서 내용을 추가했습니다.
CBAM 모듈은 채널과 공간의 attention 모듈로 구성됩니다. 이를 통해 모델이 무엇을, 어디에 봐야 하는지를 알려주어 필요 없는 정보는 억제하고 중요한 정보는 강조하게 됩니다.
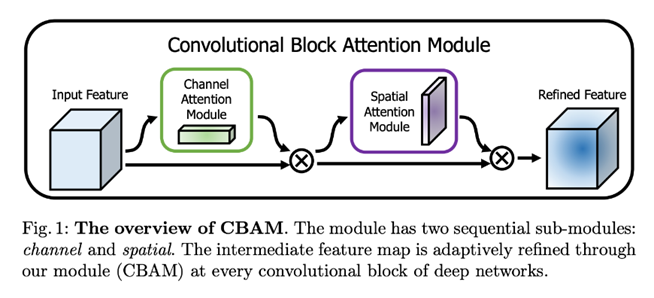
이렇게 보면, 저처럼 Attention 모듈에 이해도가 없는 사람은 이해할 수가 없더라고요. 그래서, 아래 그림을 통해 하나씩 살펴보겠습니다.
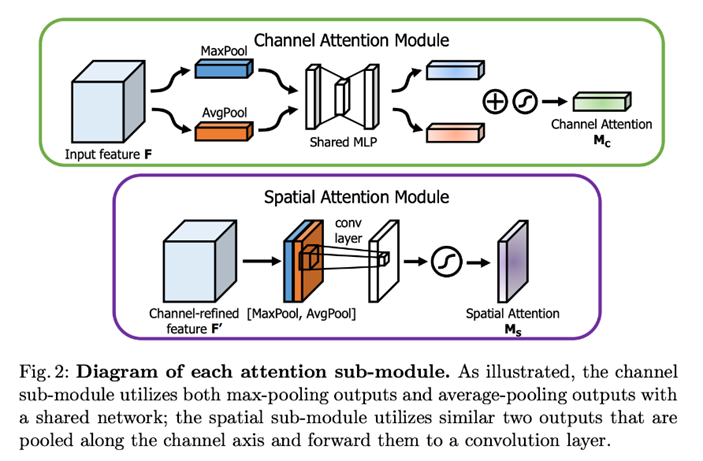
CAM: Input Feature에서 '무엇이' 가장 의미 있는 내용인가를 찾는 과정으로, Input feature를 먼저 1X1로 압축합니다. 즉, CX1X1로 압축한 후에 공간 정보를 통합하기 위해 max pooling, avg pooling을 각각 수행합니다. 그리고, 이를 따로 MLP 작업에 수행하여 각각의 Attention map을 만든 후 결과를 합치고 Sigmoid를 수행합니다. 수식은 아래와 같다. 수식이 복잡해 보이지만, 위 설명을 단순히 식으로 나타낸 것에 불과합니다.
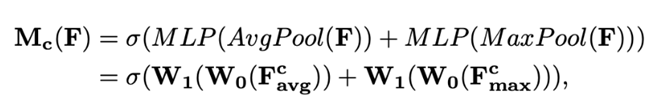
SAM: Input Feature에서 '어디에' 중요한 정보가 있는지 집중하도록 합니다. CAM 출력 결과 (M_c)과 Input Feature Map (F)을 곱하여 생성한F'에서 채널을 축으로 Max pooling과 Avg pooling을 적용한 후 두 값을 Concatenate 시킵니다. 이 값에 7X7 Conv층을 통과하여 Spatial Attention을 만듭니다. 최종적인 Feature Map은 이 Spatial Attention Map과 F'을 곱한 값이 됩니다. 두 모듈의 순서는 Channel Attention Moduel → Spatial Attention Module로 이루어집니다.
### ASSP Module
사용하는 데이터셋은 다양한 내시경 기기에서 추출된 데이터이므로 병변 영역의 크기가 제각각입니다. 따라서, 다중 스케일 특징 추출기가 수용 필드를 확장하는 데 필요합니다. 이에 ASSP 모듈을 사용해 글로벌 콘텍스트 정보를 획득합니다.
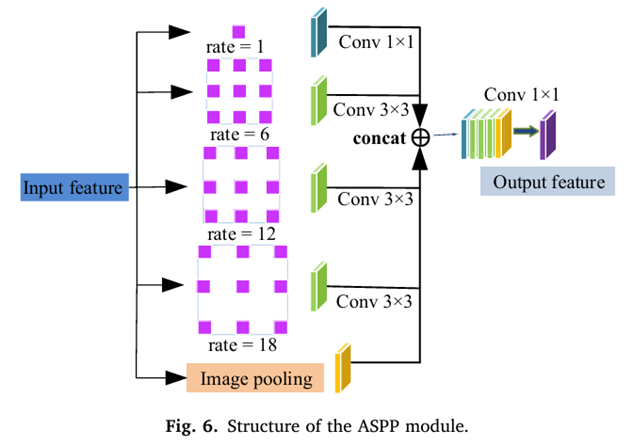
## Segmentation Network의 Loss Function
손실 함수는 기존의 Cross entropy를 사용합니다. 즉, Input으로 실제 이미지와 픽셀 수준 레이블 이미지가 들어가게 되면, 실제 이미지에서 아래 아키텍처 (CA-U-Net)를 통과하여 병변 영역을 분할하게 되고, 이를 픽셀 수준 레이블과 비교하여 Crossentropy loss로 학습시킵니다.
## Metrics
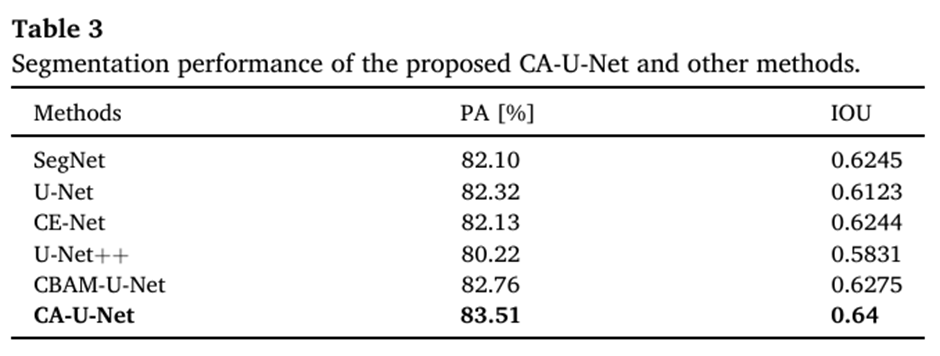
PA와 IOU를 사용하였습니다.
- PA: 예측한 것 중에 맞춘 비율
- IOU: 예측 영역과 실제 영역이 겹치는 비율
### Result
아래 그림에서 보이듯이, 다른 모델들에 비해 논문에서 제안된 CA-U-Net이 PA와 IoU값이 가장 높음을 알 수 있습니다. 이는 제안된 모델이 다른 모델에 비해 병변 영역을 잘 분할함을 의미합니다.
마치며..
오늘은 이렇게 논문에서 제안된 두 모델과 그 결과를 살펴봤습니다. Attention 모듈에 대해 알지 못했는데, 이번 기회에 공부할 수 있었습니다. 이 Attention Module이 정말 활용성이 높은 것 같아요. 성능도 끌어올릴 수 있고요. 저도 프로젝트에 한 번 적용해 볼 생각인데, 시간이 될 때 올리겠습니다.
제 글이 이 논문을 읽으시려는 분들에게 조금이나마 도움이 되었으면 좋겠습니다. 읽어주셔서 감사합니다 :)



