
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- kt희망나눔재단
- Computer Vision
- object detection
- 태블로
- 데이터과학
- 논문리뷰
- Tableau
- 태블로 실습
- 장학프로그램
- 데이터 시각화
- 머신러닝
- ResNet
- sparse coding
- 딥러닝
- 개 vs 고양이
- VGG
- 데이터 분석
- Deep Learning
- 파이썬 구현
- SRCNN
- cnn
- data analysis
- k-fold cross validation
- Data Augmentation
- kt디지털인재
- 논문 리뷰
- VGG16
- super resolution
- Semantic Segmentation
- 데이터 증강
- Today
- Total
기억의 기록(나의 기기)
[Computer Vision] GastroVRG: Enhancing early screening in gastrointestinal health via advanced transfer features 논문 리뷰 본문
[Computer Vision] GastroVRG: Enhancing early screening in gastrointestinal health via advanced transfer features 논문 리뷰
황경하 2024. 11. 19. 13:53[Computer Vision] GastroVRG: Enhancing early screening in gastrointestinal health via advanced transfer features
안녕하세요, 데이터 과학 전공하고 있는 황경하입니다.
오늘은 위암 조기 진단을 위한 GastroVRG 구조를 제안한 논문에 대해 리뷰해보려 합니다. 최근에 위암 조기 진단에 관한 논문들을 찾아보고 있는데, 종류가 너무 많더라고요. 여러 기법들이 있는데, 하나씩 좀 살펴보고 있습니다. 오늘도 시작해 보겠습니다.
* 리뷰할 논문: https://www.sciencedirect.com/science/article/pii/S2667305324000747
GastroVRG: Enhancing early screening in gastrointestinal health via advanced transfer features
The accurate classification of endoscopic images is a challenging yet critical task in medical diagnostics, which directly affects the treatment and m…
www.sciencedirect.com
* 해당 글에 첨부된 사진들은 모두 위 논문에서 발췌한 것임을 미리 밝힙니다.
* 해당 글에 설명은 논문을 기반으로 한 주관적 해석이므로 틀린 부분이 있다면, 댓글로 지적 부탁드립니다!
# Abstract
본 연구에서는 식도염과 용종(논문에서는 용종을 polyps로 표현)을 분류하는 데에 초점을 맞춥니다. Kvasir-v1 데이터셋을 이용하였으며 VGG, RF(Random Forest), GB(Gradient Boosting) 모델을 앙상블 하여 99.73%의 정확도를 달성하였습니다. 이는 오진율을 줄이고, 실제 환경에서 활용되어 의료 서비스의 질을 향상할 수 있다고 주장합니다.
# Introduction
기존 연구에서는 AI, AR, VCE(비디오 캡슐 내시경)을 이용한 위 질환 조기 발견을 위한 노력이 계속되어왔습니다.그러나, VCE와 AR은 결과의 설명력과 계속 변화하는 움직임에 비디오 분석을 지동화하는 것에 한계점이 있다고 합니다. 결국, 우리는 AI를 통해서 위 질환 조기 발견 기술을 연구해야 한다는 이야기입니다. 본 연구에서는 이를 위해, ML(Machine Learning) 모델 두 개 (RF, GB)와 DL(Deep Learning) 모델 VGG를를 결합한 새로운 앙상블 특징 추출 방법을 통해 위장 건강의 조기 검진율을 향상하고자 합니다. 또한, Cross Validation을 통해 하이퍼파라미터 튜닝을 하여 성능을 향상했습니다.
# Proposed methodology
데이터셋은 훈련과 테스트 세트를 80:20 비율로 나누어 사용했습니다. 사용 모델은 K-Fold Cross Validation 방법을 사용하여 평가되었습니다. 이는 데이터셋의 크기가 검증까지 나눌 양이되지 않았기 때문이라고 하며, 실제로 데이터셋이 작을 때에는 이런 Cross Validation 기법이 많이 사용되곤 합니다.아래는 데이터셋의 분포로 클래스가 골고루 분포됨을 알 수 있습니다.

원래 Kvasir 데이터셋은 총 8개의 클래스가 있으나, 본 논문에서는 식도염과 용종 클래스만을 사용하여 분류합니다. 그 이유는 아래와 같습니다.
- 식도염: 조기에 치료하지 않으면 식도암과 같은 심각한 합병증으로 이어질 수 있습니다. 또한, 식도암의 잠재적 지표이므로 조기 발견과 치료는 더 나은 예후와 건강 결과를 보장하는 데 필요합니다.
- 용종: 일부 폴립은 대장암으로 발전할 수 있으므로 폴립을 검출하는 것은 대장암 진단에 중요합니다.
모두 조기 진단을 하지 못하면, 향후에 암으로 발전할 수 있는 질병들이기에 사용했다고 합니다.
## Random Forest (RF)
분류와 회귀 목적으로 널리 사용되는 강력한 앙상블 학습 기법으로, 훈련 단계 동안 다수의 결정 트리를 생성하여 최종적으로 개별 트리의 출력을 기반으로 합니다. 분류 작업의 경우 클래스를, 회귀 작업의 경우 평균 예측을 산출하게 됩니다.
분류의 경우에는 각 트리의 산출 결과를 다수결에 따라 최종 결과를 산출하게 됩니다. 각 Y_1, Y_2, … 는 1번 트리, 2번 트리의 출력 결과이며, 최종 예측값 Y^을 출력합니다.

회귀의 경우에는 각 트리의 산출 결과를 평균 내어 결정합니다.
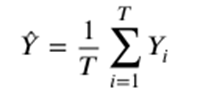
## K Nearest Neighbors Classifier (KNN)
분류 및 회귀 작업에 사용되는 간단하면서도 효과적인 지도 학습 알고리즘입니다. 가장 가까운 K개의 이웃 중 다수 클래스를 자신의 레이블로 할당하게 됩니다.
분류 작업의 경우, 랜덤 포레스트와 비슷하게 다수결로 출력 결과를 도출합니다.
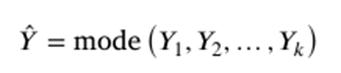
회귀 작업의 경우에는, 주변 k개의 값들의 평균으로 출력값을 산출합니다.

그러나, 이 방법의 경우 k가 하이퍼파라미터이기에 신중하게 선택해야 하며, 대규모 데이터셋의 경우 연산량이 많아 높은 계산 복잡도를 가지는 단점이 있습니다.
## Gaussian Naive Bayes
피처의 독립성을 가정하면서 베이즈 정리를 기반으로 값을 도출하여 분류하는 알고리즘입니다. 연속 데이터 유형에서 높은 효율성을 보여주고, 많은 차원의 데이터셋을 분석하는 데 유용합니다. Gaussian Naive Bayes 접근법은 특징 벡터 𝑥 = (𝑥₁, 𝑥₂, …, 𝑥𝑛)과 타깃 클래스에 대해 베이즈 정리를 통해 𝑥가 주어졌을 때, y의 조건부 확률을 아래와 같이 계산합니다.

## Gradient Boosting (GB)
여러 약한 모델(주로 결정 트리)을 순차적으로 결합하여 강력한 예측 모델을 구축하는 앙상블 학습 방법입니다. 이전 모델의 잔차에 새로운 모델을 반복적으로 적합시켜 각 반복마다 오차를 줄이게 됩니다. 이를 수식으로 나타내면 아래와 같습니다. 이전 앙상블에 현재 약한 학습기를 더한 결과를 사용하며, 𝜆는 학습률로 약한 학습기의 앙상블에 대한 기여도를 의미합니다.

GB는 손실 함수를 최소화하기 위해 약한 모델을 앙상블에 반복적으로 추가하게 됩니다. 따라서, 최종 예측은 모든 약한 학습기의 예측값의 합이 됩니다.
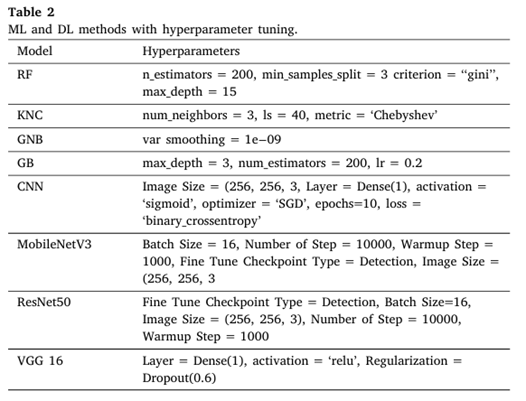
마지막으로 딥러닝 모델들로는 MobileNet v3, ResNet50, VGG16 모델을 사용하였습니다.
이 모델들은 모두 성능 비교를 통해 어떤 앙상블 조합이 가장 좋은 성능을 보이는지를 체크하는 데에 사용되게 됩니다. 본 논문에서는 그 조합으로 VGG, RF, GB를 선택하였습니다. 성능 체크에 사용된 파라미터는 아래와 같습니다.
#proposed architecture
본 연구에서는 GastroVRG를 제안합니다.
- 소아 내시경 이미지 데이터를 VGG16 모델에 도입하여 공간적 특징을 추출합니다. 이를 통해 1000차원의 공간적 특징으로 구성된 아웃풋으로 변환하게 됩니다. (Spatial Features)
- 이를 각각 RF와 GB에 입력하여 특징을 재추출합니다. (RF classfier, GB Classifier)
- 이후, 각 각 결과를 더하여 최종 특징을 추출합니다. (Ensemble transfer Features)

즉, 제안된 방식은 Feature engineering 단계이며 VGG는 이미지의 기본적인 시각적 정보를 추출하고, RF와 GB는 이를 더욱 세분화하여 다양한 관점에서 특징을 추출하며, 최종적으로 이러한 특징들을 결합하여 이미지를 더욱 정확하게 분류할 수 있는 정보를 얻도록 하는 것입니다. 이렇게 추출된 특성맵은 다시 Train, Test로 분리되어 일반적인 분류처럼 ML, DL 모델에 적용하여 최종 분류가 이루어집니다.
# Metrics
분류 문제이기에 평가 지표는 정확도, 정밀도, 재현율, F1 score를 사용하였습니다. 식은 아래와 같습니다.

## Results with spatial feature with proposed - ML models
ML 모델 중 어떠한 모델이 가장 공간적 특성을 잘 나타내는지를 보기 위한 성능 비교 결과입니다. 주어진 데이터에서 공간적 특성을 잘 표현한다는 것은, 분류를 잘한다는 것과 마찬가지일 겁니다. 특성을 잘 표현하니 분류도 더 잘하는 것일 테니까요. 따라서, 이 논문에서는 성능 평가를 위해 분류 성능을 체크하였습니다. 결과는 아래와 같습니다.

결과를 보면, GNB는 다른 모델에 비해 성능이 낮으며, RF, GB, KNC는 성능이 좋음을 알 수 있습니다. 그 중 RF와 GB는 모두 정밀도, 재현율, F1 score가 0.87로 같아 유사한 결과를 보였습니다.
## Result of the spatial features with applied - DL models
아래는 CNN 모델들의 성능 평가 결과입니다.

결과를 보면, VGG, MobileNet v3, ResNet 모두 좋은 결과를 보임을 알 수 있습니다. 여기서 VGG, MobileNet v3, ResNet은 사전 훈련된 모델, CNN 모델은 사전 훈련되지 않은 뉴럴 네트워크를 사용했습니다. 이는 사전 훈련된 모델이 더 좋은 성능을 보일 수 있음을 시사합니다.
# Performance with GastroVRG of applied methods
아래는 논문에서 제안된 GastroVRG 방법을 적용한 후의 성능 비교 결과입니다. 즉, ML 모델에 입력하기 전, VGG를 통해 공간적 특성을 추출한 후, 그 결과를 RF, GB에 넣어 특징을 추출 및 결합하고 나서의 데이터를 DL, ML 모델에 입력하여 분류한 결과입니다. (말이 어렵게 느껴질 수 있는데, 그저 특성 추출에 VGG, RF, GB를 앙상블 하여 이용하고, 그 후에 분류 모델에 넣었다는 것입니다.)
먼저, ML 모델의 결과를 살펴보면 아래와 같습니다. 결과를 보면, GNB 모델을 포함한 모든 모델에서 성능이 대폭 향상됨을 알 수 있습니다.

다음은, 딥러닝 모델의 결과입니다. 딥러닝 모델 또한 성능이 대폭 향상되었습니다. 이는 CNN 아키텍처를 사용하는 사전 훈련된 모델과 함께 GastroVRG 특징을 사용하면 식도염과 폴립의 정확한 식별에 효과적임을 강조합니다.

#Cross Validation (CV)
이는 제 다른 블로깅 글에 자세히 설명되어 있습니다. 이것까지 설명하면, 글이 너무 길어질 것 같아 개념이 헷갈리시는 분들은 이 글에 들어가서 봐주시면 감사하겠습니다. 본 논문에서의 결과는 아래와 같습니다.

# visualization
아래는 Gastro VRG 모델을 사용한 전후의 공간적 특징을 시각화한 결과입니다.

결과를 보면, 모델 적용 전에는 두 클래스가 굉장히 섞여있음을 보여줍니다. 이는 ML모델이 분류 작업을 수행할 때 굉장한 어려움을 겪을 수 있습니다. 그러나, 제안된 구조를 적용한 후에는 거의 선형적으로 나누어짐을 볼 수 있습니다. 이는 ML모델의 성능 향상을 불러일으켜 위에서 보신 결과처럼, 분류 성능이 대폭 향상됩니다.
# Conclusions and future directions
아래는 기존 연구들과의 비교 결과입니다.

이는 GastroVRG를 GB 모델에 적용한 결과이며, 정확도 약 99.73%로 매우 높은 결과를 보여주며, SOTA 모델들보다 더 뛰어난 성능을 보여줍니다.
향후 연구로는 다중 클래스 데이터셋에 적용하여 더 넓은 임상 환경에서 효과를 평가할 계획이며 실제 응용 분야에 배포하여 진단 프로세스를 더욱 신뢰할 수 있고 효율적이며 접근 가능하게 만들 것이다.
마치며...
본 논문에서는 배울 게 참 많았습니다. 제안된 구조가 그리 어려운 구조도 아닐뿐더러, 범용성이 높다고 봤습니다. 저도 연구를 하며 클래스를 분류하는 태스크가 있는데, 한 번 적용해 보는 것도 좋겠다는 생각이 들었습니다. 이제는 많은 모델들이 이미 개발되고, 성능도 증명되니 이런 앙상블을 이용하거나, 인코더와 디코더에 다른 모델을 두어 함께 사용하는 경우가 많아진 것 같습니다. 바쁘게 쫓아가야죠... 파이팅 합시다!!
제 글이 이 논문을 읽으시려는 분들에게 조금이나마 도움이 되었으면 합니다. 오늘도 읽어주셔서 감사합니다 :)




