
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 태블로
- kt희망나눔재단
- object detection
- 논문 리뷰
- 데이터 증강
- sparse coding
- VGG
- 데이터 분석
- Deep Learning
- cnn
- SRCNN
- 데이터 시각화
- Semantic Segmentation
- Tableau
- k-fold cross validation
- super resolution
- ResNet
- 머신러닝
- 장학프로그램
- 딥러닝
- 데이터과학
- Computer Vision
- kt디지털인재
- data analysis
- 개 vs 고양이
- 태블로 실습
- Data Augmentation
- 논문리뷰
- 파이썬 구현
- VGG16
- Today
- Total
기억의 기록(나의 기기)
[Computer Vision] SRGAN - Photo-Realistic Single Image Super-Resolution Using a Generative AdversarialNetwork 본문
[Computer Vision] SRGAN - Photo-Realistic Single Image Super-Resolution Using a Generative AdversarialNetwork
황경하 2024. 8. 8. 19:52[SRGAN] Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
안녕하세요, 데이터 과학 전공하고 있는 황경하입니다.
오늘은 개인적으로 진행하고 있는 프로젝트에서 사용하려 하는 SRGAN 모델에 대한 리뷰를 해보려 합니다. Super Resolution 프로젝트를 진행하면서, SRCNN, FSRCNN 모델들도 논문들을 읽고 구현해 보았습니다. 그런데, 문득 GAN 모델도 이런 task를 할 수 있지 않을까? 하는 생각이 들었는데, 실제로 GAN 모델들이 SR분야에 많이 사용되고 있어 놀랐습니다. 오늘은 그중에 SRGAN이라는 Super SR분야에 처음으로 GAN 기법을 도입한 모델에 대해 논문 리뷰를 해보겠습니다.
CVPR 2017 Open Access Repository
Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network Christian Ledig, Lucas Theis, Ferenc Huszar, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, Wenzhe Shi; Pro
openaccess.thecvf.com
* 해당 글에 첨부된 사진들은 모두 위 논문에서 발췌한 것임을 미리 밝힙니다.
* 해당 글에 설명은 논문을 기반으로 한 주관적 해석이므로 틀린 부분이 있다면, 댓글로 지적 부탁드립니다!
# Introduction
Super Resolution(초고해상도) 기술은 Low Resolution Image(저해상도 이미지)를 High Resolution Image(고해상도 이미지)로 변환하는 기술입니다. 이 기술을 구현하기 위하여 예전부터 많은 연구들이 이루어졌고, 대다수의 분야가 그렇듯 인간이 수동으로 하던 일들이 Deep Learning에 도입으로 컴퓨터가 하는 일로 대체되었습니다. 그럼 우리는 왜 Super Resolution 기술을 연구할까요? 이 논문에는 나와있지 않지만, 다른 논문에서 본 내용을 짧게 덧붙이겠습니다.
왜 Super Resolution 기술이 필요할까?
Computer Vision에서 최근에는 Transformer가 대세이지만, 이전에는 CNN을 주로 사용했습니다. CNN 모델 아키텍처 특성상 성능은 입력 이미지에 굉장히 많이 의존합니다. 즉, 고품질 데이터가 입력될수록 모델이 더 많은 특성들을 정확히 학습할 수 있고 자연스럽게 더 높은 성능을 보이는 것이죠. 그런데, 이 고품질 데이터를 수집하기란 쉽지 않습니다. 하나의 예로, 다리(Bridge) 사진을 수집한다고 합시다. 고품질 데이터를 얻기 위해선 화질이 좋은 카메라를 사용해야 하지만 그러려면 사람이 직접 사진을 찍어야 합니다. 그러면, 다리 위에 있는 차량들의 진입을 막고 사람이 도로로 들어가서 사진을 찍어야 하는데 교통 체증과 사고 위험 등을 고려했을 때 매우 위험한 방법입니다. 따라서, 드론으로 사진들을 수집합니다. 그러나, 드론은 화질이 좋은 (=무거운) 카메라를 장착하면 날지를 못하죠. 따라서, 저품질 데이터를 수집할 수밖에 없습니다. 이럴 때 Super Resolution 기술이 필요한 것이죠.
그래서, SR분야에 대한 많은 연구가 진행되었으며 SRCNN을 시작으로 Deep Learning을 도입하게 되었습니다. 하지만, SRCNN을 비롯한 다양한 모델들은 "디테일한 부분을 표현하지 못한다"는 공통적인 문제점이 존재했습니다. 이 부분에 대해서 더 깊게 이해하고 싶다면, SRCNN 논문을 읽어보시는 것을 추천드리며 시간이 없으신 분들은 제가 업로드한 논문 리뷰를 읽어보시는 것을 추천드립니다.
CNN계열 모델들은 왜 디테일한 부분을 표현하지 못할까?
CNN계열 모델들(SRCNN, FSRCNN 등)이 디테일한 부분을 표현하지 못하는 이유는 모델들의 Object Function이 MSE(Mean Squared Error)였기 때문입니다. MSE는 pixel-wise 방식으로 각 픽셀을 비교하여 평균적인 차이가 가장 적게 나도록 학습하게 됩니다. 그러다 보니 Smoothing 현상이 발생합니다. 그림을 보면서, 설명해 보겠습니다. 원본 이미지가 있을 때 그 이미지에 대한 세부 이미지 (pathes)를 추출합니다. 그렇게 된 것이 빨간색 사진들입니다. 그러면, MSE 방식으로 학습한다는 것은 이 빨간색 이미지들과 가장 average error가 적게 나도록 픽셀을 정하게 된다는 것입니다. 그러다 보니, 실제 이미지와 가장 유사하기보다는 차이가 적게 나도록 값이 설정되어 그림이 뭉개지게 됩니다. 따라서, 복원된 사진은 디테일한 부분을 잘 표현하지 못하게 되는 것이죠. 반면, GAN모델의 값은 MSE가 아닌 새롭게 정의한 Loss Function을 사용하므로 더 정확한 결과를 보여줍니다. (새로운 Loss Function에 대한 설명은 뒤에서 다루도록 하겠습니다.)

그리고, Super Resolution 분야에서 평가 지표로써 많이 쓰이고 있는 PSNR은이 MSE가 낮아질수록 높게 측정되게 설계되어 있습니다.

하지만, PSNR이 높은 모델이 반드시 더 높은 해상도를 보이는 것은 아닙니다. 아래 그림을 보시면, 인간의 눈으로 평가하기에는 SRGAN이 가장 좋은 성능을 보인다고 느껴지지만, PSNR 지표는 가장 안 좋은 성능을 보인다고 말하고 있습니다. 이로써, PSNR이 초고해상도 기술을 평가하는 지표로써 문제가 있음을 알 수 있죠.

# Method
Data
SRGAN 모델은 LR image와 HR image를 paired 하게 사용합니다. 즉, LR image로부터 HR image를 생성하는 Supervised learning 방식으로 활용이 되는데, 이 LR image를 구하는 방식이 특이합니다. HR image에서 가우시안 필터를 거친 후에 H와 W를 r배 다운 샘플링 시킵니다. 그러면, LR image가 H X W X C shape을 가진다면, HR image는 rH X rW X C shape을 가지게 되고, 생성 이미지 SR image도 rH X rW X C shape을 가지게 되죠. 따라서, LR Image를 따로 수집하는 것이 아닌 HR Image로 부터 LR Image가 수집되는 것입니다.
GAN
GAN 모델은 기본적으로 생성자(Generator)와 판별자(Discriminator) 네트워크를 가지고 있으며, 이 둘은 적대적인 관계를 가진다고 하여 적대적 생성 신경망 GAN(Generative Adversarial Networks)이라고 합니다. 적대적이라는 것은 생성자는 판별자가 자신이 생성한 이미지와 실제 이미지 중에 어떤 것이 실제 이미지인지를 못 맞추게끔 속이는 것이 목표이고, 판별자는 생성 이미지와 실제 이미지 중 실제 이미지가 무엇인지를 맞추는 것이 목표이기 때문입니다. 즉, 서로 반대의 입장에 있죠. 그래서 적대적이라고 표현합니다. GAN 모델이 SR 분야에 적용된 것도 이 생성자가 결국 실제 이미지와 최대한 유사하게끔 가짜 이미지를 생성하기 때문에 실제 이미지가 HR Image라면, 생성되는 가짜 이미지를 HR Image랑 최대한 유사하게끔 만들기 때문입니다.
Architecture
GAN 모델에서 가장 핵심적인 아이디어는 생성자입니다. 이 생성자가 얼마나 진짜 이미지와 유사한 가짜 이미지를 만들어내느냐가 중요한 것이죠. 이를 위해 이 논문에서는 Batch Normalization, Residual Block, Skip Connection을 사용합니다. 구체적으로는 Residual Block은 3 x 3 filter 64개로 이루어진 합성곱 레이어 2개와 ParameticRelu, Batch Normalization이 사용되었으며, Residual Block은 B개로 이루어져 있는 Resnet 구조입니다. 또한, 마지막에는 PixelShuffler x2 layer가 2개 있으며, 이는 이미지의 크기를 2배 늘려주는 역할을 합니다. 우리는 4x upscailing framework이므로 2개가 들어가 총 4배 키워줍니다.

판별자는 가짜 이미지와 실제 이미지를 구별하는 네트워크로써 이는 간단한 이미지 분류 문제로 생각할 수 있습니다. 따라서, 기존 CNN 모델들과 구조적으로 크게 다른 점은 없습니다. 다만, 이진 분류 문제이므로 마지막 층에 Sigmoid를 사용한다는 점은 주의 깊게 볼 필요가 있습니다.

Object Function
SRGAN 모델에서 가장 중요한 부분은 Object Function입니다. 왜냐하면, 위에서 기존 Object Function이었던 MSE가 잘못되었음을 지적했기 때문이죠. 그래서 이 논문에서는 Perceptual Loss (지각적 손실)를 제안합니다. 이는 Content loss와 Adversarial loss의 합으로 구성됩니다. 이는 생성자의 손실 함수이며, 판별자의 손실 함수는 기존 GAN 모델과 동일합니다.
Discriminator Loss
먼저, 비교적 간단한 판별자의 손실함수부터 살펴보겠습니다. D는 Discriminator (판별자)를 이야기하며, G는 Generator(생성자)를 이야기합니다. 또한, 판별자는 진짜 이미지를 1, 가짜 이미지를 0으로 표현합니다. 즉, 판별자가 잘 훈련되었다면 진짜 이미지가 입력될 시에 1을 반환해야 하는 것이죠. 그러면, I(HR)이 입력으로 들어왔을 때, 만약 판별자가 잘 훈련되었다면 1을 반환할 테니 log 1 = 0 이 되어, 앞은 0이 되는 것이고, I(LR)이 들어왔을 때는 0을 반환할 테니 뒤도 log 1이 되어 0이 됩니다. 즉, 판별자가 잘 훈련된 경우에는 loss가 0이 되는 것입니다.

Generator Loss
생성자의 loss는 Perceptual Loss로 이 논문에서 제안한 새로운 Function입니다. 비교적 어려울 수 있으나, 최대한 쉽게 설명해 보겠습니다. 앞서 언급했듯이, Perceptual Loss는 Adversarial Loss와 Content Loss의 합으로 구성되어 있습니다. Adversarial Loss는 일반적인 GAN의 loss와 동일합니다. 즉, 가짜 이미지가 실제 이미지와 최대한 유사하게끔 변화하도록 학습을 시키게 되죠. Content loss는 생성자가 만들어낸 가짜 이미지와 실제 이미지를 사전 훈련된 VGG 모델에 넣어 feature map을 추출한 후, 그 feature map들의 fixel-wise MSE를 이용하여 가짜 이미지의 특성이 진짜 이미지의 특성과 유사하도록 변화하게끔 만드는 것입니다. 그렇다면, Perceptual Loss는 가짜 이미지를 생성한 후에 그 이미지가 실제 이미지의 특성과 유사하게끔 학습하도록 하는 function이 되는 것이죠.

Adversarial Loss
앞서 언급했듯이, 기존 GAN 모델의 Loss와 동일합니다. 여기서 판별자는 생성자가 만들어낸 이미지가 진짜 이미지일 확률을 반환합니다. 그러면, 그 값이 작을수록 전체 값은 커지게 되는 것이죠. 그래서 이 값을 낮추는 방향으로 학습됩니다. 여기서 -log를 사용한 이유는 단순히 속도를 높이기 위함입니다. 논문에서는 "For better gradient behavior"라고 표현했습니다.

Content Loss
식이 복잡해 보이지만, 사실은 그리 어렵지 않습니다. 우선, 식의 구조는 MSE와 동일합니다. 그리고, HR image와 생성된 가짜 이미지를 사전 훈련된 VGG 모델에 입력한 후에 feature map들의 MSE를 줄이는 방식인 것이죠. 말로 하면 쉬운데 수식으로 보니 거부감이 드는 것 같습니다.

이렇게 모든 Obejct Function에 대한 정의가 끝났습니다. 총 3가지를 정의했네요. 하지만, 아직 풀지 못한 문제가 하나 있습니다. 바로, Metrics에 대한 부분입니다. PSNR은 MSE가 작아지면 커지기에 우리가 눈으로 보는 것과 다른 결과를 반환한다는 것을 그림을 통해 보았습니다. 그러면, 어떤 Metrics를 사용해야 할까요? 논문에서는 MOS(Mean Opinion Score)를 사용합니다.
MOS
26명의 사람들이 초고해상도 사진을 직접 평가하는 방식입니다. 하나의 사진을 여러 모델에 넣고, 그 모델들의 결과를 1점부터 5점까지 점수를 매겨 그 점수에 평균을 구하는 것입니다. 하지만, 이는 사람이 평가하는 것이기에 주관적인 견해가 들어갈 수 있다는 문제점이 있습니다. 따라서, 원본 사진과 NN 보간 방식의 사진을 넣어 원본을 5점으로 잘 평가했는지, NN 보간 방식은 1점을 주었는지 등을 통해 확인했으며, 동시에 평가자들이 동일한 데이터에 대해 유의미한 차이를 내지 않았음을 확인했습니다. 개인적으로, MOS loss는 개인 프로젝트에 쓸 수 없는 것 같습니다. 저도 이번에 프로젝트를 하면서 SRGAN을 구현해 보고, 평가할 일이 있었는데, MOS는 시간이 많이 드는 작업으로 누군가에게 부탁하기가 미안하더라고요. 다른 Metrics가 없는지 더 살펴보고 있는데, 아직까지는 찾지 못했습니다.
# Experiments
Data
학습 데이터는 ImageNet dataset을 랜덤 샘플링하여 350,000장을 사용하였으며, 학습된 모델을 평가할 때에는 BSD100, Set5, Set14와 같이 Super Resolution 분야에서 많이 쓰이는 유명 데이터셋을 이용했습니다. 아무래도, 기존 연구들과 결과를 비교하기 위해서는 같은 데이터셋을 이용하는 것이 더 신뢰성이 있어 그런 것 같습니다.
LR image는 bicubic kernel 방식을 이용하여 4배만큼 축소하였으며, 하나의 이미지를 96 X 96 size 16개로 잘라서 이용했습니다. LR image는 [0,1]로 HR image는 [-1,1]로 normalize 시켰으며, VGG feature map은 MSE 손실과 비교할 수 있도록 1/12.75 비율로 재조정되었습니다.
Weights
생성자의 Weight를 사전 학습된 SRResNet에서 가지고 왔습니다. 이는 Local optima(극소점)에 빠지는 것을 방지하기 위함이며, MSE based SRResNet을 먼저 학습시키고 난 후에 Weight를 가져와서 생성자에 사용하였습니다.
comparison
이렇게 완성된 SRGAN 모델과 다른 모델들의 결과를 비교해 보겠습니다. 먼저, BSD100 dataset에 대한 MOS 점수를 비교해 보면, HR이 5점과 가장 가까운 것을 보아 결과를 신뢰할 수 있고, 그다음으로 가장 높은 점수를 받은 모델이 SRGAN인 것으로 보입니다.
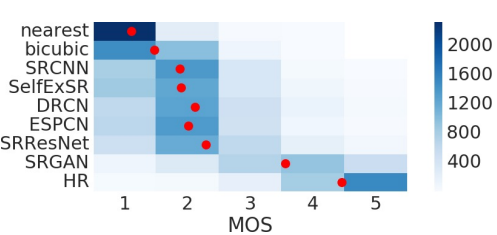
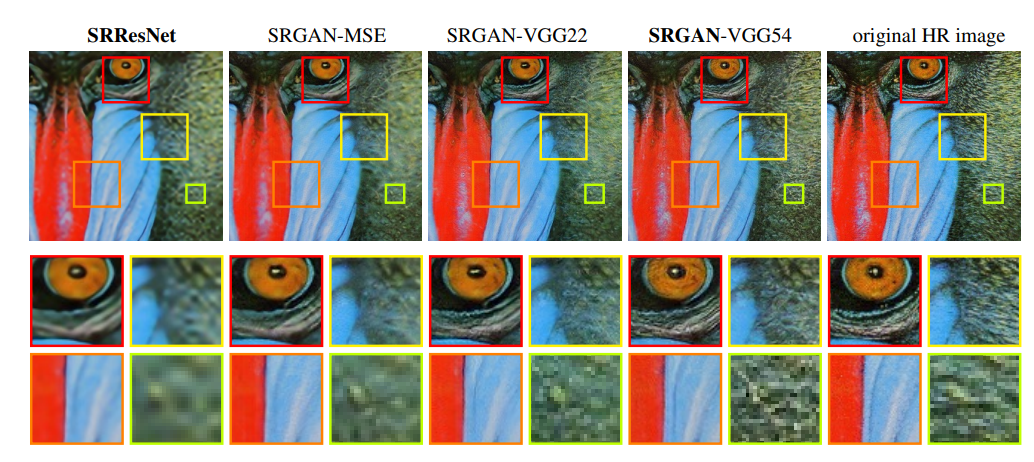
그다음으로 높은 MOS를 받았던 SRResNet 모델과 SRGAN이지만, content loss를 측정하는 과정에서 다르게 쓰인 SRGAN 모델들의 결과를 비교해 보겠습니다. SRGAN - VGG 54가 가장 디테일한 정보를 잘 표현하고 있음을 알 수 있으며, SRGAN - MSE 모델조차도 SRResNet보다 높은 성능을 보여줍니다.
- SRGAN - MSE: Content loss를 MSE로 설정한 기본 모델
- SRGAN - VGG22: Content loss를 VGG based로 구하지만, 2번째 max pooling 이전의 feature map을 이용한 모델
- SRGAN - VGG54: Content loss를 VGG based로 구하지만, 4번째 max pooling 이전의 feature map을 이용한 모델
아래 사진은 제가 구현한 이미지에 대한 모델 성능 비교입니다. 이 논문과 같이 PSNR과 사람이 눈으로 보는 결과가 다름을 알 수 있죠. 그리고 SRGAN이 다른 모델들보다 더 좋은 성능을 보임도 알 수 있었습니다. 다만, 개인적인 프로젝트이다 보니 MOS를 넣을 수 없었던 점이 아쉽습니다.


# Conclusion
이 논문에서는 기존 MSE based Super Resolution Model 들의 문제점을 짚고, 동시에 SRGAN과 SRResNet 모델에 대한 이야기를 다뤘습니다. 실제로, SRGAN모델과 SRResNet 모델이 SRCNN을 비롯한 다른 모델들보다 사람이 보기에 더 나은 결과를 보이며, MOS 지표로써도 가장 좋은 결과를 보였습니다. 하지만, SRGAN은 SRResNet보다 더 많은 훈련 시간과 runtime을 보입니다. 속도 측면에서는 아직 더 개선할 부분이 있지만, 성능 측면에서는 가장 좋은 결과를 보여줍니다.
Insight
SRCNN과 FSRCNN을 먼저 공부하고 난 후에 SRGAN 모델로 넘어왔다. 이유는 비교적 내가 많이 다뤄봤던 CNN계열이 쉽게 와닿을 것 같아서이다. 실제로 그랬지만, 조금 더 흥미가 가는 것은 SRGAN 모델이다. 프로젝트를 하는 만큼, 결과물이 어느 정도 나오는지가 중요한데 그 결과가 SRGAN 모델이 압도적인 우세를 보였다. 이번 SRGAN 논문 리뷰는 여러모로 도움이 되었다. 모델을 사용하는 데에 이론적인 내용은 알 필요가 없다고 하지만, 실제로 내가 구현하는 과정에서는 내용을 알아야만 구현을 할 수 있는 부분도 있었다. 이번 논문에서 VGG 모델을 Content loss를 계산하기 위해 쓰인다는 점이 참신했고, 다른 논문에서는 라벨링 과정에서 VGG를 썼는데 이렇게 하나의 모델링을 위하여 다른 모델을 쓰는 경우도 빈번히 이루어지는 것 같다. 그래서 더 신선했고, GAN 모델에 더 관심이 생겼다. 다만, 아직 궁금한 점은 결국 Content loss를 계산하는 과정에서 MSE가 쓰이는데 그러면, 생성 이미지와 실제 이미지의 특성을 유사하게 맞추는 과정에서도 smoothing이 발생하지 않느냐는 것이다. 나와 같은 의문을 가진 사람이 있는지 더 찾아봐야지 ,,,
마치며..
오늘은 이렇게 SRGAN 모델에 대한 리뷰를 해보았습니다. 저도 SRGAN 모델을 직접 구현해 보고 실제 프로젝트에도 이용을 했는데, 결과를 보고 깜짝 놀랐습니다. 다른 모델들보다 훨씬 더 좋은 결과를 보여주더라고요. 동시에 Perceptual loss 같은 새로운 loss를 생각해 내는 저자들이 대단하다고 느껴집니다. 논문에서도 "기존의 loss function이 아닌 자신에게 맞는 loss function을 찾아야 한다."라고 조언을 하는데, 새삼 공부가 부족함이 느껴졌습니다.
긴 글 읽어주셔서 감사합니다.




