
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 데이터과학
- 논문 리뷰
- Tableau
- 태블로 실습
- 데이터 증강
- data analysis
- Data Augmentation
- 개 vs 고양이
- Computer Vision
- Deep Learning
- 딥러닝
- 파이썬 구현
- kt희망나눔재단
- 머신러닝
- 데이터 시각화
- cnn
- Attention
- k-fold cross validation
- 데이터 분석
- LLM
- super resolution
- tcga
- SRCNN
- kt디지털인재
- 장학프로그램
- ResNet
- 태블로
- VGG16
- 논문리뷰
- sparse coding
- Today
- Total
기억의 기록(나의 기기)
[논문리뷰 / Corrosion Prediction] A Data-Driven Approach for Bridge Weigh-in-Motion fromImpact Acceleration Responses at Bridge Joints 본문
[논문리뷰 / Corrosion Prediction] A Data-Driven Approach for Bridge Weigh-in-Motion fromImpact Acceleration Responses at Bridge Joints
황경하 2024. 5. 14. 13:20논문리뷰
안녕하세요, 데이터과학 전공하고 있는 황경하입니다.
오늘은 1D-CNN, 2D-CNN을 활용한 교량 위 차량의 중량과 주행 속도를 예측하는 논문을 리뷰해보려 합니다.
현재 소자 부식을 예측하는 프로젝트를 진행 중인데, 여러 모델을 사용하여 성능을 비교하려다 보니 CNN 모델까지 왔네요. 오늘은 CNN 모델 중 1D-CNN, 2D-CNN을 이용해 주행속도와 차량의 무게를 예측하는 논문을 리뷰해 보겠습니다.
A Data-Driven Approach for Bridge Weigh-in-Motion from Impact Acceleration Responses at Bridge Joints
Bridge weigh-in-motion (BWIM) serves as a method to obtain the weight of passing vehicles from bridge responses. Most BWIM systems proposed so far rely on the measurement of bridge global vibration data, usually strain, to determine the vehicle load. Howev
www.hindawi.com
* 이 글에 첨부된 그림은 위 논문에서 발췌한 것임을 미리 밝힙니다.
서론
이 논문에서는 기존의 BWIM(Bridge-Weight-In-Motion, 교량 반응을 통한 차량 무게 측정) 시스템에 대한 이야기가 나오는데요. 우선, 교량의 특징부터 살펴보겠습니다. 다리는 사람과 같이 노후화가 이루어집니다. 이는 비가 많이 오는 지역이나 무거운 차량이 더 많이 지나다닐수록 심해지고, 붕괴 사건이 일어나기도 하죠. 그래서, 다리 위에 지나다니는 차량의 무게를 실시간으로 모니터링하여 노후화를 관리하는 것이 매우 중요합니다. 하지만, 비용과 시간 측면에서 다니는 차들을 세워두고 무게를 측정할 순 없죠. 그래서 변형률 센서를 이용하여 다리 전체의 진동 데이터를 수집해 중량을 추정합니다. 즉, 차량이 지나가기 전과 후의 다리의 진동 데이터의 변화율을 이용하여 차량의 무게를 예측하는 것이죠. 하지만, 이 방법은 다수의 차가 다리를 지나갈 때 각 차량의 무게를 측정하는 데에 어려움이 있으며 이는 차와 차 사이의 간격이 좁을수록 더 심해집니다. 그래서 이 논문에서는 기존의 변형률에 대한 반응으로 차량 무게를 예측하는 것이 아닌 교량 연결부에 가속도계를 설치하여 차량의 무게를 예측하려 합니다. 가속도계를 사용하면 좋은 점은, 짧은 시간 안의 신호를 이용할 수 있기 때문에 여러 차량이 지나가더라도 예측 정확도가 떨어지지 않는다는 점입니다. 또한, 이 논문에서는 총 3개의 모델을 구축하는데, 첫 번째 모델은 CNN을 이용한 차량 인식 및 차선 예측 모델, 두 번째, 세 번째 모델은 차량의 무게와 속도를 예측하는 모델로써 각각 1D-CNN, 2D-CNN 모델을 사용합니다. 데이터는 교량의 연결부에 설치된 가속도계를 이용하여 충격 가속도를 수집하였고, 무게 측정기와 카메라를 통해 차량 중량, 통과 차선, 주행 속도 등을 측정하여 라벨로 사용했습니다. 이 데이터를 각 CNN 모델에 입력시킨 후 훈련을 통해 차량의 무게와 속도를 예측하는 것이 최종 목표입니다. (데이터 수집에 관한 더 자세한 내용은 시험 계측 분야 전문가의 영역이기 때문에 이 정도로 이해하고 넘어가겠습니다.)
본론-1 (차량 인식 및 차선 예측)
데이터의 수집은 자세히 다루지 않았지만, 데이터를 이해하는 건 반드시 거쳐야 하는 작업입니다. 그래야 정확한 분석이 이루어질 테니까요. 이 논문에서는 충격 가속도 센서를 설치하여 얻은 데이터와 차량의 무게, 차량의 주행 속도가 어떠한 상관관계를 가지는지 약 5900대의 차량 데이터를 이용하여 그림으로 표현했습니다. 일반적으로, 차량이 무거울수록 가속도 또한 커져야 합니다.

하지만, 보시는 것처럼 가속도의 최댓값과 차량의 무게, 차량의 속도는 모두 비선형적인 관계를 보입니다. (a) 같은 경우에 선형 관계처럼 보일 수 있지만, 사실은 실제 데이터가 추정 직선으로부터 너무 많이 퍼져있어서 비선형 관계라고 볼 수 있습니다. 따라서, 차량의 무게와 속도는 가속도만으로 예측하기 어려우며 다른 복잡한 요인이 존재함을 알 수 있습니다. 이제는, 차량 인식 및 차선 예측을 위한 CNN 모델을 구축합니다. 이를 위해서, 아래 그림을 참고해 주세요.

차량이 교량의 연결부에 들어오게 되면, 설치된 가속도계를 이용하여 다리에 진입한 차량의 가속도 데이터를 얻습니다. 이 데이터를 분석하여 차량의 차선을 예측하게 됩니다. 먼저 전처리 과정을 통해, 가속도 데이터를 CNN의 입력 형식에 맞게 바꿔줍니다. 바꾼 데이터는 행(=2개)에는 1차선 데이터, 2차선 데이터가 있으며 열(=300개)은 가속도계 데이터의 특성이 담겨있습니다. 따라서, (2,300)의 shape을 가집니다. 데이터는 8:2로 훈련데이터와 테스트데이터를 나누어 입력합니다. 이 모델은 예측 범주는 총 3가지로 1번 차선, 2번 차선, 미탐지가 됩니다. 미탐지는 말 그대로 1차선, 2차선이 아닌 이탈 차선을 이야기합니다. layer는 Convolution → Relu → Convolution → Relu → Fully connected layer로 이루어져 있으며, Fully connected layer의 마지막 층에서는 Softmax 함수를 활성화 함수로 사용하며 Cross entropy를 loss function으로 이용합니다. 그 결과 1차선은 95.24%, 2차선은 92.93%, 3차선은 96.65%의 정확도를 보였습니다. 지금까지는 가속도 데이터를 가지고 차량을 인식하고 차선을 예측하는 모델을 구성했습니다. 이제부터는, 본격적으로 우리의 목표인 차량의 무게와 속도를 예측하는 모델을 만들어보겠습니다.
본론-2 (차량 무게 및 속도 예측)
가속도 데이터를 이용하여 예측할 수 있는 건 차선뿐만이 아닙니다. 차량의 무게와 속도를 예측할 수도 있죠. 이번에는 입력 데이터는 똑같이 가속도 데이터를 이용할 것이고, 출력데이터는 해당 차량의 무게와 속도가 되겠죠. 다만, 주의할 점은 이전 모델과 달리 들어오는 데이터가 단일 데이터라는 점입니다. 즉, 이번에는 입력데이터가 가속도계 1(=1차선 가속도계)에서 얻어진 데이터만을 입력 데이터로 설정합니다. 이 데이터는 시간 순으로 정렬되어있습니다. 그래서, 이 입력 데이터의 타임 히스토리의 최대 절댓값을 중앙에 위치시키는 시간 이동 과정을 거칩니다. 이 과정을 통해 입력의 복잡성을 줄이고, 정확도를 향상시킵니다. 또한, 이번에도 훈련 데이터와 테스트 데이터의 분리는 훈련 80%, 테스트 20%로 나누며, 입력데이터와 출력 데이터에 모든 통과 차량의 무게와 속도의 최댓값으로 빼주어 정규화해줍니다. (w는 weight 중량이고, s는 speed 속도입니다.)

이렇게, CNN에 들어갈 데이터 전처리는 끝났습니다. 이제는 손실 함수를 정의하겠습니다.

pre: predicton, tar: target으로, 예측값 - 실제값의 제곱을 하고 더하여 2로 나누는 작업을 해줍니다. MSE와 비슷한 식이네요! 이렇게 데이터 전처리와 손실함수를 정의했습니다. 이제 본격적으로 모델을 구축하고 정확도를 확인해 보겠습니다.
먼저, 1D-CNN에 대해 생소하신 분들이 계실 것 같아 짧게 설명해 보겠습니다.
1D-CNN이란?
1D-CNN은 일반적인 CNN과 달리 이미지 처리보다 신호처리나 텍스트 분석, 시계열 데이터 분석에 많이 사용됩니다. 그 이유는, 1D-CNN의 작동 방식을 살펴보면 알 수 있는데요. 각 데이터 sequence룰 하나의 필터가 순차적으로 합성곱을 진행합니다. 그렇기 때문에 순차적으로 정렬된 데이터와 시계열 데이터에 높은 성능을 보여주죠. 여기서도 가속도계 데이터를 활용할 때에 짧은 시간에 프레임별로 쪼개어 데이터를 획득하며, 시간대별로 정렬되어 있기에 1-D CNN이 높은 성능을 보일 것이라 예측됩니다.
모델을 정의했으니 이제 1D-CNN 모델에 데이터를 넣어보죠! 레이어 구성은 이렇습니다.

가속도계 1을 이용하여 얻은 데이터만 사용한다고 했으니 입력데이터는 1차원이죠. (1D-CNN은 입력이 항상 1차원입니다.) 그리고 합성곱과 Relu를 거쳐 Fully connected layer에 입력해 줍니다. Fully connected layer에서 학습을 진행할 때에는 Early stopping 기법을 활용하여 과적합을 방지하며 3번 이상 테스트 성능이 떨어지는 경우 학습을 멈추고 최고 성능의 결과를 출력합니다. 모델의 성능을 평가하기 위한 지표로는 MAE(Mean absolute error), RMSE(Root mean squared error)를 사용하였습니다. 이전 차선 예측 모델 같은 경우는 이 지표로 accuracy를 이용했었죠. 그 이유는 calssification 문제였기 때문입니다. 하지만, 지금은 regression 문제이기 때문에 MAE, RMSE 값을 사용합니다. 결과는 2D-CNN 모델까지 수행하고 한 번에 비교하여 확인해 보죠! 이번엔 2-D CNN 모델을 구축할 것입니다. 이전에 1-D CNN 모델에 입력데이터를 넣을 때 어떠한 전처리 과정 없이 가속도 데이터를 입력받아 그대로 입력 데이터로 넣었습니다. 그 이야기는, 가속도계 데이터와 차량의 속도, 중량과의 관계를 신경망이 알아서 해석해야 된 다는 것을 이야기합니다. 즉, 분석을 하지 않고 넣었기 때문에 신경망은 그냥 입력된 데이터만으로 알아서 예측을 한다는 것이죠. 반면에, 데이터를 미리 분석해서 신경망에 넣는다면 어떨까요? 아마도 성능이 올라갈 것으로 예측됩니다. 그래서 2-D CNN에 입력 데이터를 넣을 때는 웨이블릿 변환이라는 것을 사용해 데이터를 분석하여 입력합니다. 웨이블릿 변환을 거치게 되면, 시간과 주파수로 채워진 2차원 행렬로 바뀌게 됩니다. 이제 데이터를 2차원으로 변경했으니 2D-CNN 모델에 입력할 수 있습니다.
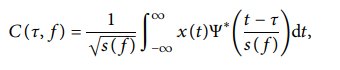
2D-CNN 모델의 레이어 구성은 다음과 같습니다.

이번에도 역시 가속도계 1 데이터만을 이용할 것이며 이번엔 시간과 주파수로 변환된 것이죠. 이번에는 pooling층을 추가했습니다. 그래서 convolution → Relu → Maxpooling → Convolution → Relu → Maxpooling → Fully connected layer 순으로 들어갑니다. 1D-CNN 모델과 똑같이 Fully connected layer의 경우 Early stopping을 사용하여 과적합을 방지하였고, 3번 이상 테스트 성능이 떨어지는 경우 학습을 멈추고 최고 성능의 결과를 출력합니다. 평가지표는 위와 마찬가지로 MAE와 RMSE를 사용하였습니다. 이제 1-D CNN과 2-D CNN의 결과를 비교해 보죠!

보시다시피, 2-D CNN의 성능이 더 좋음을 알 수 있습니다. 그래서 최종 모델을 2D-CNN 모델을 활용하여 차량의 무게와 속도를 예측합니다. 하지만, 지금 사용한 데이터는 가속도계 1만을 이용한 결과이죠. 이게 차선2에 지나가는 차량의 무게와 속도를 잘 예측할 것이라 장담할 순 없습니다. 그래서 이미 가속도계1 데이터를 이용해 학습한 모델에 가속도계 2 데이터를 넣어서 전이학습을 진행합니다. (전이학습에 대한 설명까지 넣으면 너무 길어질 것 같아서 머신러닝 카테고리에 전이학습에 대한 내용을 포스팅하겠습니다.)

이렇게 가속도계2 데이터를 이미 가속도계 1 데이터에 학습된 모델에 전이학습시킨 결과가 그렇지 않은 경우보다 성능이 더 좋네요.
결론
결론적으로, 이 논문에서는 기존의 변형률 센서를 이용한 BWIM 방식은 여러 차량이 한 번에 지나갈 때 차량의 무게와 속도를 정확히 예측하기 어렵다는 문제점을 언급합니다. 그리고 그 문제점을 가속도계 데이터를 이용하여 극복하려 하죠. 그 이유는 가속도계 데이터의 경우 짧은 시간의 데이터만으로 예측할 수 있기 때문에 차량이 여러 대 지나가더라도 정확히 예측할 수 있기 때문입니다. 이 가속도 데이터를 이용하여 1D-CNN, 2D-CNN 모델에 입력하여 차량의 무게와 속도를 예측합니다. 그 결과, 2D-CNN의 결과가 더 뛰어남을 알 수 있었고, 오차도 매우 작죠. 그리고 다른 차선의 데이터를 학습시킬 때에도 전이학습을 통해 더 쉽게 학습 가능합니다. 이는 활용성 측면에서도 뛰어나다는 것을 말합니다.
후기
오늘은 1D-CNN, 2D-CNN에 대해 알아봤습니다. 제가 진행하고 있는 부식 예측 프로젝트도 시계열 데이터여서 1D-CNN, 2D-CNN을 활용할 수 있지 않을까 생각하여 논문을 찾아봤습니다. 근데, 저의 생각보다 너무 어렵고 그만큼 시간도 오래 걸렸네요 ,, 아직도 정확히 이해했다고 할 순 없을 것 같습니다. 다음에는 Early stopping 기법과 텍스트 생성을 예로 든 전이학습 기법에 대해 포스팅해 보겠습니다. 이 글을 읽으시는 분들 모두 파이팅입니다!



