
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 파이썬 구현
- sparse coding
- super resolution
- 논문 리뷰
- data analysis
- VGG16
- Deep Learning
- 태블로
- 데이터 증강
- k-fold cross validation
- 개 vs 고양이
- 딥러닝
- Tableau
- kt디지털인재
- 데이터 분석
- 논문리뷰
- cnn
- 머신러닝
- SRCNN
- VGG
- 데이터과학
- Data Augmentation
- Semantic Segmentation
- 데이터 시각화
- 장학프로그램
- ResNet
- kt희망나눔재단
- object detection
- 태블로 실습
- Computer Vision
- Today
- Total
기억의 기록(나의 기기)
[논문 리뷰 / Car Damage Classification] CarDD: A New Dataset for Vision-based CarDamage Detection 본문
[논문 리뷰 / Car Damage Classification] CarDD: A New Dataset for Vision-based CarDamage Detection
황경하 2024. 7. 1. 17:00논문리뷰 - CarDD: A New Dataset for Vision-based Car Damage Detection
안녕하세요, 데이터과학 전공하고 있는 황경하입니다.
계속 모델에 관련된 논문만 읽었는데, 오늘은 처음으로 Dataset을 소개하는 논문을 읽어봤습니다.
논문: CarDD: A New Dataset for Vision-based Car Damage Detection
https://ieeexplore.ieee.org/abstract/document/10078726
CarDD: A New Dataset for Vision-Based Car Damage Detection
Automatic car damage detection has attracted significant attention in the car insurance business. However, due to the lack of high-quality and publicly available datasets, we can hardly learn a feasible model for car damage detection. To this end, we contr
ieeexplore.ieee.org
* 이 글에 포함되는 모든 그림은 위 논문에서 발췌한 것임을 미리 밝힙니다.
서론
논문을 리뷰하기 전에 먼저 CarDD라는 것이 무엇인지부터 설명해 보겠습니다.
CarDD란, Car Damage Detection의 줄임말입니다. 이전에 논문 리뷰할 때도 언급했지만, 인건비와 공정성을 위해서 보험사들의 보험비 청구 프로세스를 자동화할 필요가 있습니다. 따라서, 딥러닝을 활용하기로 했죠.
하지만, 딥러닝(CNN)을 활용하기 위해서는 필수적으로 하나의 조건이 성립해야 합니다. 학습하기에 충분한 양의 데이터이죠. 하지만, 차량 손상 유형은 매우 다양하며 그 크기마저 다양합니다. 따라서, 고품질의 데이터가 부족했고 다양한 연구가 시도되었지만 손상 분류는 아래와 같은 2가지 문제점이 존재합니다.
- 여러 가지 손상 유형이 있는 샘플 데이터를 처리하기 어렵습니다. (다양한 유형의 데이터 부족)
- 손상 분류만으로는 손상 위치나 손상 정도를 파악할 수 없습니다. → 자동차 손상 검출 및 세분화 연구가 필요.
위 두 가지 문제를 해결할 수 있는 가장 간단한 솔루션은 충분한 양의 데이터 확보입니다. 기존의 모델들은 손상 이미지의 양이 너무나 적었기에 단순히 이진분류 정도의 태스크만 가능했습니다. 하지만, 다양한 손상 유형의 이미지가 주어진다면 어떨까요? 기존 모델들을 새로 학습시켜 손상 데이터에 대한 성능을 올릴 수 있을 것입니다. 또한, 객체 탐지 모델을 학습시켜 손상 부위도 감지할 수 있겠죠. 따라서, 이 논문에서는 CarDD라는 dataset을 소개하며 최대 크기의 공개 데이터셋을 소개합니다. 더불어, DCN+라는 DCN 모델을 업그레이드한 객체 탐지 모델을 제안합니다.
Data Desription
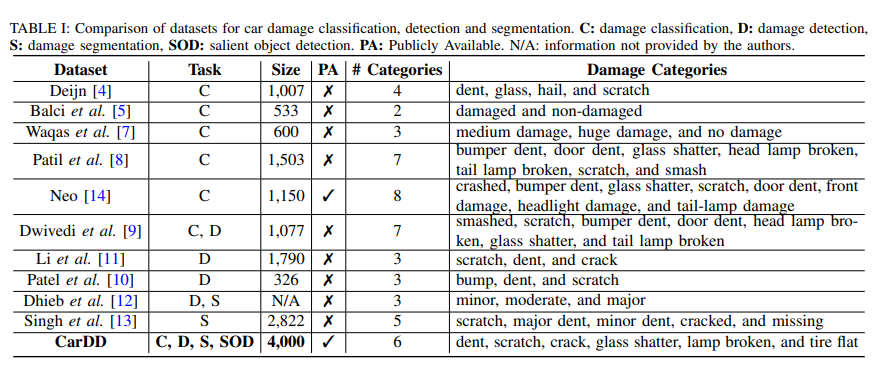
CarDD dataset은 기존 데이터셋과 달리 다양한 task에 적용 가능하며, 지금까지 공개된 자동차 데이터셋 중 가장 큰 고품질 데이터셋입니다. 아래 그림은 관련 연구들에 쓰였던 Dataset과 CarDD를 비교한 사진입니다.
Size를 봤을 때, [13]을 제외한 모든 데이터셋의 size가 2000 미만임을 알 수 있습니다. 그러나, CarDD는 4000개로 매우 크죠. 또한, Task도 C, D, S, SOD로 가장 많은 task에 적용할 수 있음을 알 수 있습니다.
Task Desription
- C: Damage Classification
- D: Damage Detection
- S: Damage Segmentation
- SOD: Salient Object Detection
SOD?
이 논문을 보며 SOD라는 말을 처음 들어서 블로그를 뒤져보고 논문도 찾아보며, SOD에 대해 알아봤습니다.
SOD는 Salient Object Detection의 줄임말이며 한국말로는 중요 객체 탐지입니다. 일반 Object detection과 차이점은 Object detection 모델은 입력 사진에서 어떤 객체가 있는지를 단순히 bounding box로 표시하는 반면, SOD는 가장 중요한 객체를 찾아 그 객체의 범위 전체를 Saliency map으로 표현하는 것입니다.

반면, Object detection 방식은 모든 객체를 다 표시하죠.

또한, CarDD는 6가지 손상 범주에 대한 4000장의 고품질 데이터가 포함되어 있으며, 9000장의 segment 라벨링 된 이미지가 포함되어 있습니다. 여기서 고품질이란 라벨링이 되어 있으며, 해상도도 다른 데이터셋에 비해 큼을 의미합니다. 해상도는 약 684,231 픽셀로 다른 관련 논문에서 사용된 데이터셋이 50,334 픽셀을 가지는 것을 생각하면 약 13배 더 큰 해상도를 가집니다. 레이블은 아래와 같습니다.
- Dent: 찌그러짐
- Scratch: 스크래치
- Crack: 균열
- Glass shatter: 유리 파손
- lamp broken: 램프 파손
- tire flat: 타이어 펑크
이 외에도 추가적인 작업을 위한 손상 심각도도 제공된다고 언급되어 있지만, 자세한 설명이 없어 생략했습니다.

여기서 해상도가 크다는 것이 의미가 있는지를 살펴볼 필요가 있습니다. 만약, 저해상도 이미지와 고해상도 이미지가 성능차이가 크지 않다면, 단순히 메모리만 차지할 뿐이니까요. 논문에서 나와있는 말을 인용하면, CarDD의 용량은 739KB인 반면 다른 공개된 github dataset은 9KB 정도라고 하니 매우 큰 메모리 용량을 차지한다는 것을 알 수 있습니다. 따라서, 해상도에 따른 성능의 차이를 보겠습니다.
아래 그림의 각 이미지의 3번째 이미지를 비교해 보면, (a)에서는 detection 되는 부위가 (b)에서는 detection 되지 못하는 것을 알 수 있습니다. 이처럼, 고해상도 이미지를 이용한다면, 작은 스크래치 같은 손상 부위도 잘 감지할 수 있음을 알 수 있습니다.

데이터 수집 과정
데이터 수집은 Flickr5, Shutterstock6이라는 웹사이트에서 크롤링하여 사용했습니다. 이유는, 고품질 데이터이며 동시에 다양한 시점에서 찍힌 사진들이 있어 일반화 성능을 높이기 위함입니다. 중복된 이미지는 duplicate cleaner를 이용하여 제거합니다. 이 과정에서 제거되는 중복 이미지를 데이터셋에서는 제거하되 이진 분류기로 활용할 VGG16의 학습 이미지로써 사용합니다.
VGG16 모델을 데이터 수집 과정에서 사용하는 것이 저에게는 매우 생소했는데요. VGG16 모델을 사용한 이유는 이렇습니다. 우선, 크롤링 한 사진에 라벨링 작업을 해야 합니다. 하지만, 모든 이미지에 수동으로 라벨링을 하기에는 매우 많은 시간이 걸리죠. 따라서, 이미지를 손상 이미지와 정상 이미지로 분류하는 작업을 모델이 대신해주는 것입니다. 모델을 학습하기 위한 데이터는 직접 라벨링 하여 손상 이미지와 정상 이미지를 5:5 비율로 만들어 훈련 데이터와 테스트 데이터를 만듭니다. 그 후 VGG16 모델을 이용하여 이미지를 분류하고, 라벨링을 해줍니다.
VGG16 모델을 이용하여 라벨링을 한다면, 오류율을 체크할 필요가 있습니다. 잘못 라벨링이 될 수 있으니까요. 그래서 성능을 체크했을 때, 위양률(False Positive rate)이 4.5%, 위음률(False negative rate)이 1.2%로 허용할 수 있는 오류율이 나왔습니다. 이렇게 데이터를 분류하여 직접 라벨링을 통해 4000장의 이미지를 수집하였습니다.

Labeling
이 논문에서 최종적으로 가고자 하는 목표는 결국 보험 청구 프로세스를 자동화하는 것입니다. 따라서, 라벨링이 매우 중요한 부분을 차지합니다. 이 라벨링에 따라 모델이 다른 대답을 할 것이고, 그 대답은 클라이언트에게 청구되는 금액일 테니까요. 따라서, 이 논문에서는 3가지 기준을 제시합니다.
1) Priority between damage classes
: 자동차 수리 기준을 사용하여 결정합니다. 대부분의 손상은 복합적으로 일어나는 경우가 많습니다. 이런 경우에는 라벨링을 할 때 자동차 손상 수리 기준에 따라서 심각도에 따라 우선순위를 결정합니다. 예를 들어, Scratch + Dent가 있는 차량의 경우, Scartch는 도장 수리만 필요하지만, Dent는 금속 복원 + 도장 수리가 필요합니다. 따라서 Dent가 Scratch보다 더 심각한 것으로 판단하고, Dent로 라벨링 합니다.
2) Damage boundary split:
: 서로 다른 손상 부위는 별도로 청구합니다. 예를 들어, 앞 문과 뒷 문에 스크래치가 있다고 하면, 그 부분은 손상 부위가 다르기에 별도로 청구합니다. 따라서, 라벨링도 따로 설정해야 하죠. 그래서, Detection 모델이 필요합니다.
3) Damage boundary merging
: 같은 부위의 같은 손상은 동일한 가격으로 청구합니다. 손상량에 관계없이 한 부위에 나타난 동일한 손상은 라벨을 하나만 부여합니다.

EDA (Exploratory Data Analysis)
라벨링까지 완료했으니, 데이터셋을 분석해 보겠습니다.
(이 결과는 이후 모델링 결과에 많은 영향을 끼칩니다.)
- (a): Dataset의 크기 비교
- (b): CarDD dataset의 범주별 크기별 샘플 개수 분포
- (c): CarDD dataset의 범주별 샘플의 크기 분포
- (d): 촬영 앵글 분포
- (e): 차량의 색상 분포

Modeling (DCN+)
이 논문에서는 새로운 객체 탐지 모델로 DCN+를 제안합니다.
DCN+ 모델은 기존 DCN모델에 multi scale learning 방식과 focal loss 방식을 도입한 방법입니다.
우선, 전체적인 Flow chart는 아래와 같습니다. input으로 자동차 이미지가 입력되면, multi class resizing을 통해 데이터 증강을 해줍니다. 이 방법은, 이미지의 높이를 너비(hyper parameter)와 동일하게 유지하면서 [640, 1200] 범위 내에서 resizing 하여 증강하는 기법입니다. 그렇게 증강한 사진으로 DCN 모델을 학습시키고, 모델의 예측 결과를 확인합니다. 모델이 감지한 손상 부위와 실제 손상 부위를 비교하여 loss를 측정하고 그 loss를 줄이는 방향으로 학습하게 됩니다.

조금 더 구체적으로 들어가면, loss function을 정의할 때 3가지 loss를 더하여 산정합니다.
앞서, DCN에서 추가되었다는 focal loss와 생성된 감지 범위와 실제 ground truth 이미지의 L1 loss, 분리 이미지에 대한 Cross Entropy로 총 3가지 loss를 더합니다.
이제, Focal Loss와 Cross Entropy를 추가한 것이 의미가 있는지 확인해 보겠습니다. AP라는 지표를 사용하는데, 이는 Average Precision의 약자입니다. 분류 문제이니 Precision을 사용합니다.

아래 그림에서 보이는 것처럼, 추가하는 것이 의미가 있는 걸 알 수 있습니다.

Optimizer로는 Momentum을 이용합니다. 그러면, 최종적으로 모델의 하이퍼파라미터는 4개가 됩니다.
Multi scale learning의 재조정 범위와 너비, focal loss 설정 시 알파 값과 감마 값이죠. 하이퍼파라미터를 튜닝하기 위해 재조정 범위와 너비는 고정한 채로 알파 값과 감마 값에 변화를 주어 AP값을 비교합니다.
아래 그림처럼, 중간 크기의 객체는 알파 값이 커질수록 잘 감지하지만, 반대로 작은 물체는 잘 감지하지 못합니다. 따라서, 적절한 값을 설정해야 합니다. 이 논문에서는 알파 값을 0.5로 감마 값을 2.0으로 설정합니다.

위처럼, 하이퍼 파라미터를 설정한 후 모델의 감지 결과를 표시해 보면 아래와 같습니다. 왼쪽 사진은 DCN+ 모델에서 MSL(Multi scale learning)을 제외한 경우, 오른쪽은 포함한 경우입니다. 결과를 보시면, 스크래치가 더 잘 감지됨을 알 수 있습니다. 이를 통해 DCN+ 모델의 유효성이 한 번 더 강조되었네요.

Result
이제 DCN+ 모델과 다른 모델들의 성능 차이를 보겠습니다. 중요한 건, 비교하는 모델들도 모두 SOTA 모델들로 성능이 좋다는 것입니다. 모델들의 Backbone 모델은 ResNet으로 동일하지만, 성능은 DCN+가 압도적입니다. 또한, Backbone 모델의 층이 깊어질수록 성능도 향상되는 경향이 있습니다.

DCN+ 모델의 예측 결과를 시각화해서 보면, 아래와 같습니다.
일부 범주는 정확히 Detection 하지만, 일부는 그렇지 않습니다. 이는 Dent, Scratch, Crack은 거의 동반되어 나타나기 때문입니다. 또한, 크기도 매우 작습니다. 위에서 데이터의 분포를 살펴본 그림을 한 번 더 보면, 이 3개의 범주는 Small size가 매우 큰 부분을 차지합니다. 즉, 아주 작은 손상이기 때문에 Detection 하는 데에 어려움이 있는 걸로 보입니다. 마지막으로, Scratch와 Crack은 매우 비슷한 모양을 띕니다. 예를 들어, 스크래치와 균열 모두 가느다란 선과 비슷한 색상을 가지고 있습니다. 모델에 혼란을 야기할 수 있는 부분입니다. 이를 논문에서는 "Hard Sample"이라고 표현하며, 다른 범주들은 "Easy Sample"이라고 표현합니다.

그리고 하나 더, 어려운 케이스가 있습니다. 이렇게 손상된 이미지로만 학습시킨 모델을 실제 보험사에 도입했을 때, 사기꾼들이 정상 이미지를 넣고 보험금을 수령할 수 있다는 것이죠. 따라서, 손상 이미지가 아닌 일반 이미지에 대한 성능도 체크해야 합니다. 여기서 신기했던 점은, 모델은 손상 이미지에 초점이 맞춰져 있는데도 정상 이미지에 잘 반응한다는 것입니다. 1.2%의 AP밖에 감소되지 않았습니다.

SOD 사용
위에서 SOD에 대해 간략히 설명했었습니다. 현재 모델에서는 Object detection 방식을 사용했지만 이 방식이 Dent, Scratch, Crack에 대해서 잘 구분하지 못하는 것을 봤습니다. 따라서, SOD 방식을 사용해 보겠습니다.
SOD 방식은 두 가지 장점을 가집니다,
1) SOD 방법은 특징 객체의 경계를 세밀하게 조정하는 데 집중하기 때문에 불규칙하고 가느다란 모양의 객체를 세분화하는 데 더 적합합니다.
2) SOD 방법은 객체를 분류하지 않고 이미지에서 모든 특징적인 객체를 찾는 데 중점을 둡니다. 범주 정보가 거의 없는 클래스의 경우 객체를 분류하기보다는 손상 위치와 크기를 파악하는 것이 더 중요합니다.
실험 방법은 위와 동일합니다. CarDD에 최첨단 (SOTA) SOD 방법 네 가지 (CSNet, PoolNet, U2-Net, SGL-KRN)를 적용합니다. 모든 모델을 CarDD로 처음부터 훈련합니다. 또한, 각 손상 카테고리에서 SOD 방법의 성능을 평가하기 위해 클래스별 성능을 체크합니다. 즉, 이진 맵에서 하나의 손상 클래스 마스크만 활성화된 상태로 CarDD에서 모델을 훈련 및 테스트합니다.
성능 비교 결과, SGL-KRN이 가장 좋은 성능을 보여주네요. 결과도 시각화해 보겠습니다.
시각화 결과도 SGL-KRN이 가장 잘 Detection 하는 것을 알 수 있습니다.


SGL-KRN 모델의 범주별 결과도 확인해 보겠습니다.
여기서 특이한 점은 Crack이 가장 낮은 MAE를 보인다는 것인데요, 이는 MAE의 함정 때문입니다. MAE는 평균 에러율입니다. 즉, 예측한 손상 감지 이미지와 실제 손상 감지 이미지의 평균 차이인 것이죠. 따라서, 크기에 민감합니다. 그런데, Crack의 경우 약 95%가 다 small size인 것으로 보아 MAE가 가장 작게 나온 것을 확인할 수 있습니다.

따라서, MAE가 아닌 다른 평가 지표가 필요한데 그 부분에 대해서는 논문에서 자세히 다룬 내용이 없어 아쉽습니다.
결론
처음에는 CarDD 데이터셋에 대한 설명으로 이루어져 있습니다. 그리고 이 모델을 이용한 결과를 보여주고, DCN+라는 새로운 모델을 제시하며 기존의 모델들보다 더 Object detection이 잘 되는 지를 보여주었습니다. 실제로 더 성능이 뛰어나기도 했죠. 그러나, 일부 범주에 대해 성능이 저하되었고, SOD라는 기법에 CarDD 데이터셋을 이용하여 성능을 확인해 봤습니다. 결과를 확인했을 때 DCN+ 모델보다 더 세세한 부분을 더 Detection 하는 것을 확인할 수 있었죠. 이로 인해 CarDD dataset이 Object Detection과 SOD 방식에 모두 잘 적용됨을 확인할 수 있었습니다.
Insight
: 이번 논문에서는 새로운 정보를 많이 얻게 된 것 같아 기쁘다. 먼저, 다른 논문들과 달리 데이터셋을 어디서 수집을 했고, 어떻게 전처리를 했는지 등이 상세히 나와있어 좋았다. Duplicate Cleaner라는 프로그램으로 전처리를 했다고 해서 찾아보니 중복 이미지 제거 프로그램이던데, 나도 Vision Project를 시작하니 한 번 해봐야겠다. 또한, 프로젝트를 위해서는 Object Detection 모델도 개발할 예정이라 다른 논문들을 위주로 공부 중인데, SOD라는 개념은 이 논문을 통해 처음 알게 되었다. 퀄리티가 비교적 낮은 논문들을 보면, SOD라는 개념은 던지되, OD와 SOD의 차이는 정확히 설명하지 않는 경우가 많다. 하지만, 이 논문은 개념을 설명함과 동시에 그 차이점을 제시해서 더 이해가 편했다. 물론, 그럼에도 한 번 더 정보를 찾아보긴 했지만 논문만으로도 이해가 되어서 시간이 오래 걸리진 않았다.
마치며..
차량 손상 감지, Object Detection에 대한 논문들을 살펴보고 있었습니다. 그러다 이 논문을 발견했고, 제가 맞닥뜨린 문제점과 유사하여 읽게 되었습니다. 이 논문을 읽으며 Object detection 모델의 SOTA 모델들, SOD 기법이 무엇인지와 SOD SOTA 모델들을 알게 되었습니다. 그리고, 데이터 라벨링 과정에 VGG16을 사용한다는 점도 신기했고요. 논문이 순서가 뒤죽박죽이어서 정리하면서 쓰느라 평소보다 2배 더 시간이 걸린 것 같습니다.. 그래도 하고 나니 뿌듯하네요.
Computer Vision 분야를 깊게 공부해보려 하니 계속 새로운 것들이 등장하는 것 같습니다. 쉽지 않네요,, 그래도 열심히 해보겠습니다. 오늘도 읽어주셔서 감사합니다.




