
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 장학프로그램
- 데이터 증강
- 태블로
- ResNet
- VGG
- Tableau
- 머신러닝
- 개 vs 고양이
- 논문리뷰
- k-fold cross validation
- 딥러닝
- Semantic Segmentation
- Data Augmentation
- 파이썬 구현
- kt디지털인재
- data analysis
- SRCNN
- 논문 리뷰
- sparse coding
- kt희망나눔재단
- VGG16
- object detection
- Deep Learning
- 태블로 실습
- 데이터과학
- Computer Vision
- super resolution
- cnn
- 데이터 시각화
- 데이터 분석
- Today
- Total
기억의 기록(나의 기기)
[논문 리뷰 / Car Damage Classification] Deep Learning Based Car Damage Classificationand Detection 본문
[논문 리뷰 / Car Damage Classification] Deep Learning Based Car Damage Classificationand Detection
황경하 2024. 6. 25. 13:59논문 리뷰 - Deep Learning Based Car Damage Classification and Detection
안녕하세요, 데이터과학 전공하고 있는 황경하입니다.
오늘은 새롭게 시작한 프로젝트를 생각하여 참고한 논문을 소개해보려 합니다.
이 논문은 딥러닝을 이용하여 차량의 손상을 인식하고 손상 유형을 분류하는 모델을 제안합니다. 이 모델은 보험비 자동 청구 시스템에 활용될 수 있으며, 데이터셋이 부족하여 높은 성능을 보이진 못 하지만, 추후 발전 가능성이 매우 높아 참고해도 좋을 만한 내용이 담겨있으니 최대한 잘 설명해 보겠습니다!
논문:https://link.springer.com/chapter/10.1007/978-981-15-3514-7_18
* 해당 글에 있는 모든 사진은 위 논문에서 발췌한 것임을 미리 밝힙니다.
서론
오늘날 많은 보험 회사들은 교통사고와 자동차 손상에 관한 보험비 청구 문제와 싸우고 있습니다. 실제로 TV에서 빈번히 보험비 과다 청구 관련 뉴스들을 찾아볼 수 있죠. 이에 이 논문은 AI를 이용하여 보험비 청구 프로세스를 자동화시켜 이 문제를 극복하고자 합니다. 왜냐하면, 그동안 있었던 문제들은 보험사의 주관적인 의견이었기에 많은 논란을 빚었지만, AI를 통해 이를 수치화한다면, 쉽게 해결될 수 있기 때문이죠. 따라서, 이 논문에서는 차량의 이미지를 입력받으면, 객체 인식 모델이 이미지의 손상 부위만 detection 하고, 그 이미지를 분류 모델이 입력 이미지로 받아서 차량의 손상 유형을 분류하는 것이죠. 그리고, 그 손상 유형에 따라서 보험비가 청구되는 방식으로 작동합니다. 아래 그림처럼요!
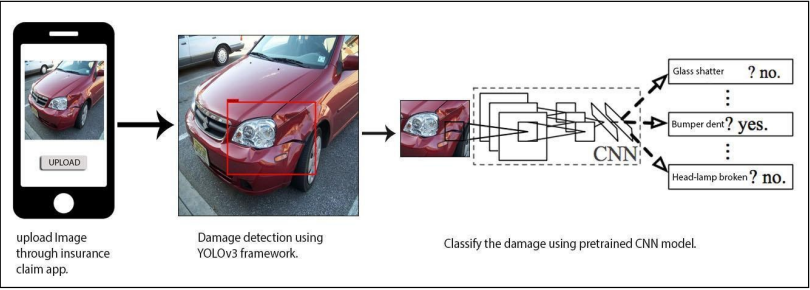
Dataset Description (데이터셋 설명)
그러나, 항상 그렇듯 데이터셋을 구하는 것이 문제입니다. 이 논문에서는 Google, Bing 웹 사이트에서 크롤링하여 데이터셋을 얻고 이를 수동으로 라벨링 하여 데이터셋을 구축했다고 합니다. 이를 다시 말하면, 수동으로 라벨링을 할 수 있을 정도로 데이터셋이 적다는 것을 의미하죠. 따라서, 모델을 처음부터 구축하고, 이렇게 적은 양의 데이터셋으로 학습시킨다면 Overfitting에 쉽게 노출될 수 있습니다. 그래서 ImageNet 데이터셋으로 사전 학습된 모델을 사용합니다. 그리고, 데이터 증강 기술을 활용하여 원래 데이터셋의 크기보다 약 4배 정도 더 늘리고 8:2로 train data와 test data를 split 합니다.

위 사진을 보면 알 수 있듯이, 차량의 손상 유형은 매우 다양합니다. 이에 따라 라벨의 범주도 늘어나겠죠. 이 논문에서는 모든 유형을 다 다룰 순 없기에 가장 일반적인 유형 8가지로 구분합니다. 범주는 아래와 같습니다.
- smashed: 부서짐
- scratch: 흠집, 스크래치
- bumper dent: 범퍼 찌그러짐
- door dent: 문 찌그러짐
- head lamp broken: 헤드램프 파손
- glass shatter: 유리 파손
- tail lamp broken: 뒤쪽 램프 파손
- no damage: 손상 없음.
Calssification Model (분류 모델 만들기)
분류 모델을 먼저 살펴보겠습니다. 크게 보아 총 5가지 계열의 모델을 사용합니다. 모델 설명은 아래와 같습니다.
- AlexNet: ImageNet 데이터에서 복잡한 장면 분류 작업을 처리하기 위해 설계된 딥 컨볼루셔널 신경망으로 총 8개의 레이어로 구성되어 있으며, 처음 5개는 Convolution Layer 일부는 Max Pooling Layer가 뒤따르며 마지막 3개는 Fully Connected Layer(FC Layer)로 구성되어 있습니다.
- VGG19: VGG19과 유사하며 VGG16은 16개의 층으로 구성되어 있는 반면에, VGG19는 19개의 층으로 구성되어 있습니다. (자세한 설명은 이 글을 참고해 주세요!)
- Inception V3: 구글에서 개발한 딥 컨볼루션 아키텍처. 42개의 레이어. 1x1 컨볼루션을 수행함으로써 Inception 블록은 공간 차원을 무시하고 교차 채널 상관관계를 수행합니다. 이어 3x3 필터와 5x5 필터를 통하여 교차 공간 상관 관계와 교차 채널 상관 관계를 수행합니다. 이러한 모든 레이어는 차원 축소를 거쳐 1x1 컨볼루션으로 끝납니다.
- Mobilenet: 모바일 애플리케이션용으로 작고 효율적인 신경망 MobileNets는 표준 컨볼루션을 depthwise convolution과 pointwise convolution으로 분해하는 분리된 컨볼루션 개념을 기반으로 합니다.
- ResNet50: 이전 포스팅에서 다뤘던 ResNet은 152층이었고, 이번에는 50층으로 바뀐 것으로 매우 유사한 구조를 가졌습니다. (자세한 설명은 이 글을 참고해주세요)
위 모델들을 이용하여 모델별 데이터셋에 대한 결과를 살펴보겠습니다. 위에서 말씀드린 것처럼 모델들은 모두 ImagNet으로 훈련되어 있기에 baseline이 12.5%(=100 / 8)가 아님을 염두해두어야 합니다.

생각보다 높은 결과가 나왔네요. 이 논문에서는 제일 좋은 성능을 보인 모델로 ResNet50을 채택하였는데요. 정확도만 본다면, VGG19가 가장 높지만 Parameter 수를 본다면 약 6배에 달합니다. 학습에서 파라미터 수는 수행 시간과 관련이 있고, 이게 만약 서비스로 개발된다면 수행 시간은 고객의 만족도에 영향을 미치기 때문에 그렇게 선택을 한 것 같습니다.
Transfer learning & Fine-tuning (전이 학습 & 미세 조정)
위 모델은 사전 학습된 모델 형태 그대로를 사용했습니다. 즉, 우리 데이터셋에 맞춘 형태가 아닌 이미 학습된 형태 그대로를 사용한 것이죠. 따라서 전이 학습과 미세 조정을 통하여 우리 데이터셋에 맞게 학습시켜줄 필요가 있습니다. 다른 글에서도 설명을 했지만, 전이 학습을 하는 과정에서는 ImagNet으로 학습된 모델의 분류기를 그대로 사용할 수 없습니다. FC 레이어의 출력 뉴런 수가 다르기 때문이죠. 따라서, 특성 추출기 부분만 가져와서 새로운 분류기를 삽입하고 그 분류기를 학습시켜야 합니다. 그리고 나서 미세 조정 과정을 통해 특성 추출기의 상위 층만 학습을 시키게 되죠. 이 과정을 통해 우리의 데이터셋에 맞도록 모델을 학습시킵니다. 하지만, 이 때의 학습률 또한 네트워크의 성능과 속도에 영향을 미치기에 중요한 파라미터입니다. 이 논문에서는 이 학습률을 정하는 방법으로 DLR 방법을 채택하였습니다.
DLR?
DLR은 Different Learning Rate의 약자로 학습률을 한 번에 정하고 고정하여 사용하는 것이 아닌 레이어마다 다르게 학습률을 적용하는 것입니다. 우선, "학습률의 경계"를 찾습니다. 학습 경계를 찾는 방법은 학습률을 초반에 낮게 설정하고 계속 올리면서 loss 값이 증가하기 직전 값을 찾는 것입니다. 이렇게 해서 초반 값 ~ 증가하기 직전 값까지를 경계로 잡습니다. 그리고 이 경계 안에서 학습률을 순환적으로 변화시킵니다. 여기서 순환적으로 변화시킨다는 것이 어렵게 느껴질 수 있는데, 쉽게 말하면, 학습률을 주기적으로 초기화 시켜주는 것입니다. 이렇게 하는 이유는, ‘spikey region(극소점)'에 빠질 수 있기 때문인데요. 극소점에 loss값이 빠져버리는 순간 gradient가 0이 되기 때문에 더 이상 학습이 진행되지 않습니다. 이를 피하기 위하여 주기적으로 학습률을 초기화 해주는 것이죠. 또한, 이 논문에서는 레이어마다 서로 다른 학습률을 지정합니다. 즉, 네트워크의 깊이가 깊어짐에 따라 학습률 또한 증가하는 방법을 사용합니다. 이렇게 레이어마다 서로 다른 학습률을 적용하는 것이 DLR 방법입니다. (DLR을 좀 더 깊이 공부해보려 했는데, 논문 참고 논문에 기재되어 있던 깃허브가 사라졌네요 ,,)

DLR 적용 전 대비 적용 후 정확도가 많게는 5%, 적게는 3%정도 증가했네요. 이는 엄청난 변화입니다.

혼동행렬을 보더라도 대각선이 매우 높은 것을 보아 잘 예측하고 있는 것으로 볼 수 있습니다.
CAM(Class Activation Mapping)
CAM 기술은 입력 이미지의 어떤 픽셀이 클래스를 예측하는 데에 중요했는지를 시각적으로 알려줍니다. 마치, SHAP 기법과 비슷하네요. 이를 통해 CNN 모델이 어떤 픽셀에 집중했는지를 확인하여 제대로 작동하는지를 확인할 수 있습니다. 이를 통해 loss를 측정하여 개선하는 방식으로 학습시킨다면, 모델이 객체 위치를 찾는 작업을 학습시킬 수도 있습니다.

위 그림에서 노란색과 빨간색으로 나타난 부분이 정확히 차량이 파손된 부분임을 알 수 있습니다. 이를 통해 CNN 모델이 제대로 작동함을 확인할 수 있습니다.
YOLOv3 (객체 인식 모델)
YOLOv3 모델은 최첨단 분류기로 106개의 레이어로 구성되어 있습니다. 이전 모델인 YOLOv2에서 잔차 연결층과 업샘플링 층을 넣어 성능을 개선하였고, DarkNet 아키텍처를 사용합니다. (DarkNet 아키텍처는 성능은 최첨단 분류기와 동등하지만 연산 속도가 ResNet 101보다 약 1.5배, ResNet 152보다 약 2배 더 빠릅니다.) 이를 통해 입력 이미지의 손상 영역만 레이블링하여 객체 탐지 기능을 테스트해본 결과 아래와 같습니다.

각 클래스는 Bumper Dent (BD), Car Scratches (CR), Door Dent (DD), Glass Shatter (GS), Lamp Broken (LB), Smashed (SM)로 구성되어 있으며, CR과 LB가 다른 이미지들에 비해 유난히 적은 이유는 데이터셋에 이미지가 적기 때문입니다. YOLOv3 모델을 그대로 사용하였는데도, 매우 높은 성능을 보이고 있습니다. 이제는 thershold를 변경해 가며 결과를 살펴보겠습니다. 이미지 해상도를 변경해가며 결과를 살펴보겠습니다.


위 두 결과를 봤을 때, 해상도가 증가함에 따라 MAP(Mean Absolute Precision)값이 증가함을 알 수 있습니다.

결론
이렇게 두 모델을 살펴보았습니다. 최종 결과 분류 모델은 ResNet50이 가장 좋은 결과를 보였고, 객체 인식 모델은 YOLOv3를 사용하였습니다. 이렇게 두 모델을 연결하여 입력 이미지가 들어왔을 때 YOLOv3 모델을 이용하여 손상 부위를 정확히 detection하고, 그 부위를 ResNet50에 입력으로 넘겨주면 손상 유형을 classification하는 구조로 되어있습니다. 이를 통해, 웹 사이트를 개발하고 클라이언트들이 손상된 차량 이미지를 입력 후 보험비를 자동화하여 계산할 수 있습니다. 또한, 시간이 지남에 따라 고객들이 입력한 이미지가 많이 쌓기 되면 그것을 다시 학습 이미지로 사용하여 모델을 개선할 수도 있습니다.
마치며..
이렇게 오늘은 Computer Vision 논문을 읽어보았습니다. 최근에 딥러닝응용 수업을 들었는데, 거기서 들었던 내용과 유사한 내용도 있어 생각보다 어렵지 않게 배울 수 있었습니다. 다만, YOLOv3에 대해서는 더 깊이 공부해야 할 것 같아 추후에 YOLOv3 모델에 대한 설명으로 돌아오겠습니다. 오늘도 읽어주셔서 감사합니다.




