
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- data analysis
- Computer Vision
- 논문리뷰
- sparse coding
- Attention
- 태블로
- 태블로 실습
- 딥러닝
- 머신러닝
- kt디지털인재
- 데이터 증강
- 파이썬 구현
- Tableau
- k-fold cross validation
- ResNet
- 데이터 시각화
- kt희망나눔재단
- super resolution
- VGG16
- cnn
- 논문 리뷰
- 데이터과학
- tcga
- 개 vs 고양이
- SRCNN
- 장학프로그램
- Data Augmentation
- Deep Learning
- Semantic Segmentation
- 데이터 분석
- Today
- Total
기억의 기록(나의 기기)
[Data Analysis] 데이터 시각화를 위한 태블로 - 4주차 본문
데이터 시각화를 위한 태블로 - 4주 차
안녕하세요, 데이터 과학을 전공하고 있는 황경하입니다.
저번 포스팅에 이어 오늘은 태블로 4주 차 내용을 공유해 보겠습니다.
글의 구성은 아래와 같습니다.
- 파이썬 시각화의 결과 제시.
- 태블로로 구현하는 과정 설명
- 결과 비교
사용하는 데이터에 대한 설명은 이 글을 참고해 주세요!
제가 빨간색으로 색칠한 문제는 아직 저도 답을 정확히 찾지 못한 문제입니다. 어떤 부분에서 답을 찾지 못했는지도 적어놓았으니, 참고해서 읽어주세요.
실습 1
- 모든 평당 분양가격의 평균을 bar plot 하시오
- 모든 평당 분양가격을 box plot 하시오
- 모든 평당분양가격을 hist plot 하시오

첫 번째 axis 그림부터 구현해 보죠.
먼저, 모든 평당 분양가격의 평균을 구해줘야 합니다. c. avg(평당분양가격) 이라는 필드를 새로 만들어줄게요. 그러면, 이 값은 그냥 상수값 하나일 것입니다. 그림으로 그려주면 위와 동일하겠네요.
- 새로운 필드 만들기 - 계산식 입력


두 번째 axis 그림을 그려보죠.
먼저, boxplot으로 표현할 값은 평당 분양가격이죠. 그런데, 태블로에서는 기본적으로 특성값을 사용합니다. 즉, 평당 분양가격을 행 선반에 올려주면 자동으로 SUM(평당 분양가격)으로 계산된다는 것이죠. 그러면, 이 값은 그저 상수값 하나 일 뿐이기에 boxplot으로 표현할 수 없습니다. 따라서, 특성값이 아닌 차원으로 값을 변경해 주고, 전체 값에 대한 분포를 그리도록 변경해 주겠습니다.
- 행 선반에 평당 분양가격을 올림 - 마우스 오른쪽 클릭 - 차원 선택
그러면, 자동으로 boxplot 형태로 그림이 도출됩니다.
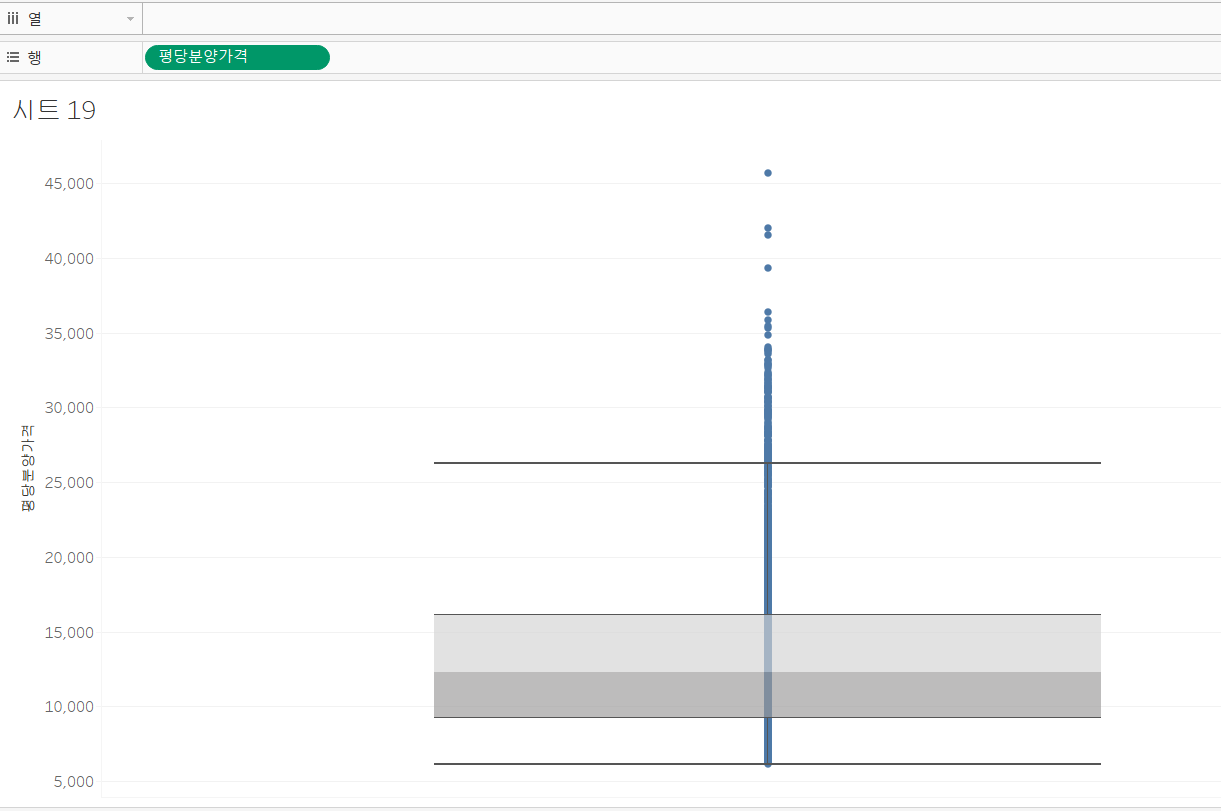
이번에는 빨간색 선을 그려주겠습니다. 파이썬 코드에서 빨간색 선은 평당 분양가격의 평균에 그려주었습니다. 따라서, 우리도 평균에 빨간색 선을 그려줄게요.
- 분석 패널 - 평균 라인 드래그 - 테이블 선택

그려진 선은 편집하여 빨간색으로 바꿔주면서, 레이블은 제거하겠습니다.
- 그려진 선에 마우스 오른쪽 클릭 - 편집 - 라인 - 빨간색 선택
- 레이블 - 없음


이제 세 번째 axis 그림을 그려보겠습니다.
단순히, 모든 평당 분양가격을 히스토그램으로 표현한 것입니다. 따라서, 행 선반에 평당분양가격을 올리고, 표현 방식을 히스토그램으로 변경해 줄게요. 이 때는 차원으로 변경할 필요가 없습니다. 왜냐하면, 표현방식이 히스토그램으로 변경된 경우에는 자동으로 구간별 카운트를 세주기 때문입니다.
이후 빨간색 선을 두 번째 axis그림과 같이 평균에 추가해주어야 하는데, 기존의 선을 추가하는 방식은 y축 값을 기준으로 추가되는 것이기 때문에 가로선으로 밖에 그려지지 않습니다. 하지만, 우리는 x축 값을 기준으로 추가를 해줘야 하기 때문에, 세로 선으로 그려줘야 하는데 제가 아직 이 부분에 대해서 방법을 찾지 못해서 해답을 찾으면 다시 추가하도록 하겠습니다.

마지막으로, 대시보드로 하나의 그림에 표현해 보겠습니다.


실습 2
- 서울 경기 별 모든 평당 분양가격의 평균을 bar plot 하시오
- 서울 경기 별 모든 평당 분양가격을 box plot 하시오
- 서울 경기 별 모든 평당분양가격을 hist plot 하시오

모든 그림이 서울 경기 지역만 사용하고 있기 때문에, 필터를 잘 설정하는 것이 중요할 것 같습니다.
그런데, 필터는 태블로 자체 프로세스의 속도를 매우 느리게 합니다. 따라서, 우리가 좀 더 고도화해서 워크시트 내에서나 대시보드에서 동작을 추가하여 어떤 작업을 한다고 했을 때에 필터는 이 수행속도를 느리게 하는 주범입니다.
그래서, 우리는 필터를 조건식으로 사용하는 필드를 만들어서 필터의 사용을 없애서 진행해 보겠습니다.
서울, 경기 지역을 필터링하는 필드를 각각 만들어주겠습니다.


이제, 이 필터들을 이용하여 각 지역의 분양가격의 평균 필드를 만들겠습니다. 아래처럼 필드를 만들면, 자동으로 합계를 집계로 설정됩니다. 따라서, 집계를 평균으로 바꿔줄게요.
- 만든 필드 모두 선택 - 마우스 오른쪽 클릭 - 기본 속성 - 집계 - 평균


만든 필드를 그려주겠습니다. 두 측정값을 모두 넣고, 표현 방식을 가로 막대로 변경해 줍니다. 그리고, 행과 열을 바꿔주면 아래와 같은 그림이 나옵니다.


이제, 대시보드를 만들 때에 디테일한 부분 (순서 정렬, 별칭 편집 등)을 수정해 주면 완성될 것 같습니다.
두 번째 axis 그림을 그려보겠습니다. 이번에는 boxplot을 그려야 하는데, 문제는 첫 번째 axis 그림을 그릴 때에는 표현 방식 중에 가로막대가 있어서 나란히 그릴 수 있었습니다. 하지만, boxplot은 가로가 없기 때문에 나란히 그릴 수가 없더라고요. 그래서 제가 아는 지식 선에서는 아직 필터 없이 하기가 어려워서 필터를 만들어 사용하겠습니다.
서울, 경기 지역만 필터링하는 필드입니다. 이 필드를 필터로 사용하겠습니다.

실습 1의 두 번째 axis 그림과 같은 과정으로 평당 분양가격의 boxplot을 그려주겠습니다.

열 선반에 "지역명" 필드를 넣어줘서 지역별 평당분양가격의 분포를 그려주고, 필터에 만든 필드를 넣어서 필터링해 주겠습니다. 이 그림도 디테일한 부분만 잡아주면 될 것 같습니다.
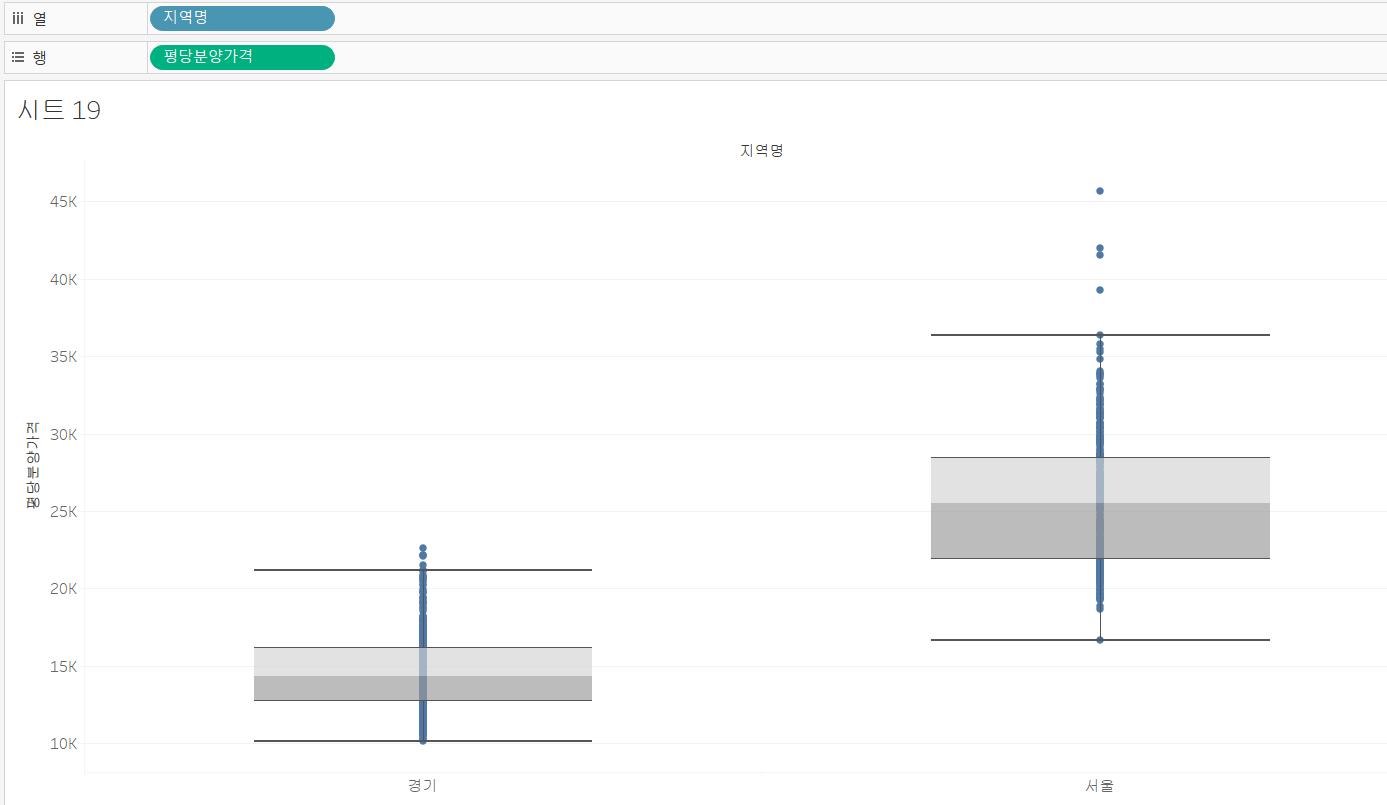
세 번째 axis 그림을 그려보겠습니다.
평당 분양가격을 히스토그램으로 표시하고, 서울, 경기 지역만 필터링해 주겠습니다.

이제, 서울 지역과 경기 지역의 색상을 구분하기 위해 마크의 색상을 지정해 주겠습니다. 파이썬의 결과를 보니 경기 지역만 색상이 다르네요. 경기 필터를 색상으로 지정해 줍시다.

이제 모든 그림을 다 완성했으니 대시보드에 하나의 그림으로 표현해 주겠습니다.


실습 3
- 지역별 모든 평당 분양가격의 평균을 bar plot 하시오 (ax1)
- 지역별 모든 평당 분양가격을 line plot 하시오 (ax1)
- 지역별 모든 평당분양가격을 box plot 하시오 (ax2)

첫 번째 axis 그림의 경우 두 개의 그림을 이중축으로 합쳐서 그려야 될 것 같습니다.
먼저, 막대그래프부터 그려보겠습니다. 단순히, 지역별 평균 평당 분양가격을 그린 것이므로 열 선반에 "지역명" 필드를 넣어주고, 행 선반에 "평균 평당분양가격" 필드를 넣어주겠습니다.

이제, 라인 그래프를 그려보겠습니다. 같은 값을 나타내므로 표현 방식만 라인으로 바꿔주면 될 것 같습니다.
- 복사하고자 하는 필드 컨트롤 키 누른 상태에서 옆으로 드래그 - 마크에서 표현 방식을 라인으로 변경
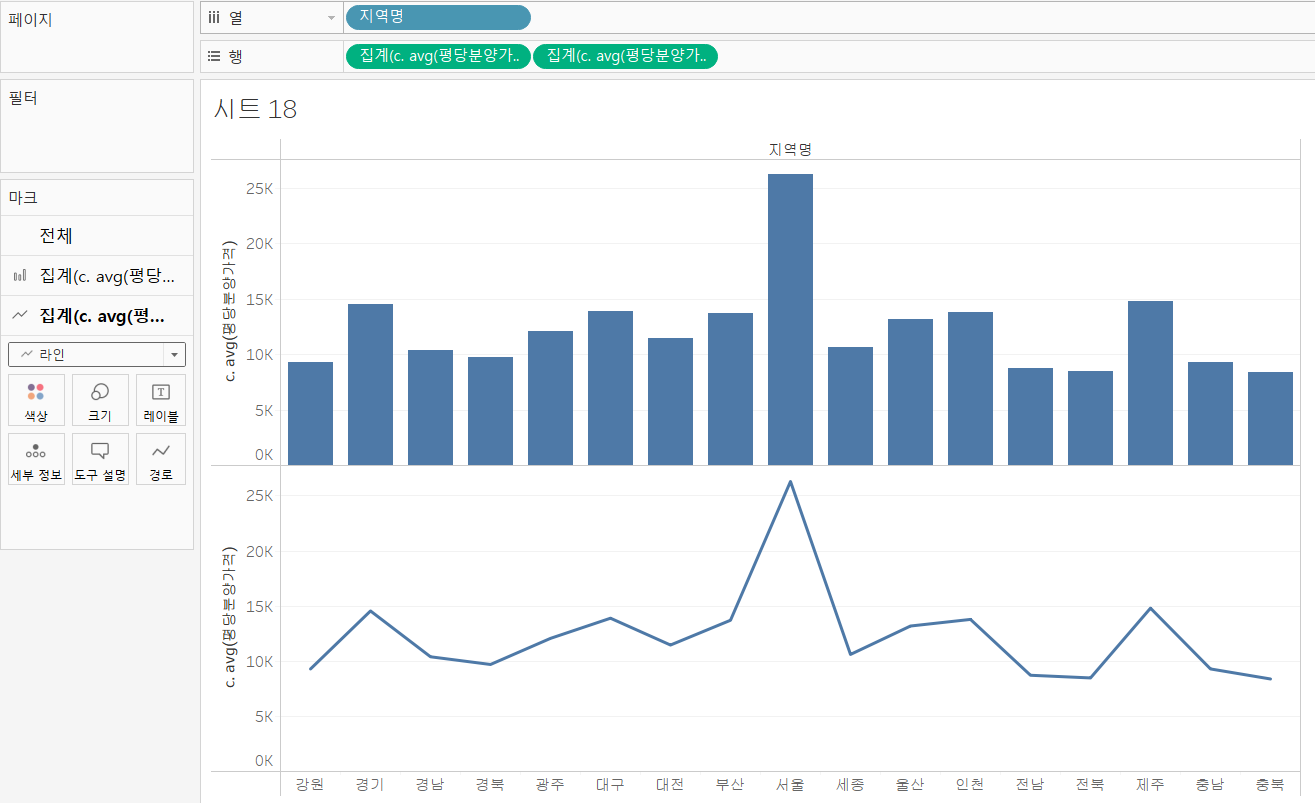
라인 그래프의 색상을 변경하고, 두 그림을 이중축으로 설정해 합쳐주겠습니다. 이번에는 두 그래프가 표현하는 값이 동일하기 때문에 축 동기화는 실행할 필요 없습니다.
- 마크 - 색상 - 노란색으로 변경
- 행 선반에 오른쪽 필드 선택 - 마우스 오른쪽 클릭 - 이중축

두 번째 axis 그림을 그려보겠습니다.
이전에 풀었던 문제들과 똑같이 평당분양가격을 차원으로 변경하여 boxplot을 그려주고, 열 선반에 "지역명" 필드를 넣어주겠습니다. 그림을 얼추 나왔으니 순서 정렬 등 디테일한 부분만 채워주면 될 것 같습니다.

이제, 두 그림을 하나의 대시보드에 표현해 보겠습니다.
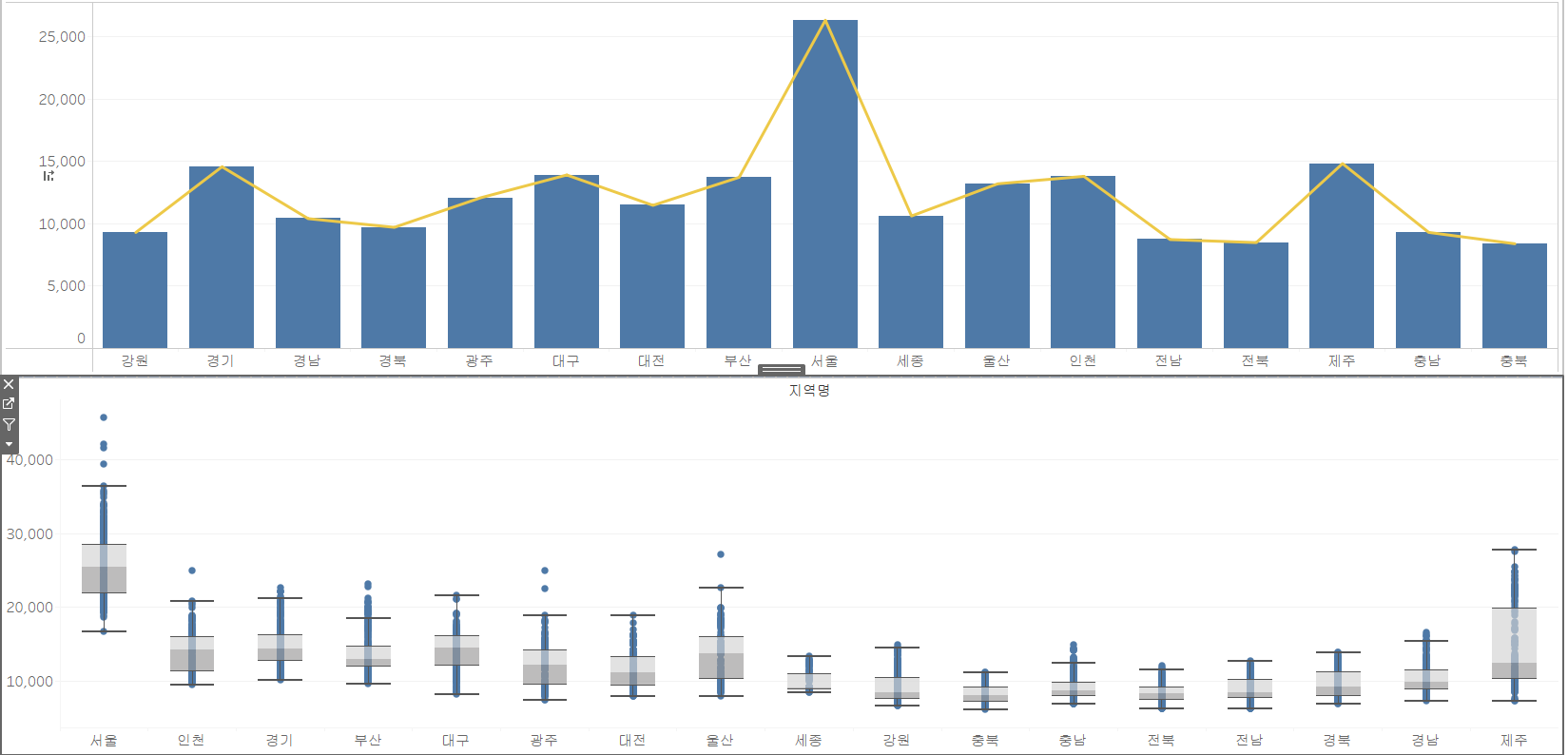

실습 4
- 2018년 중에서 평당 분양가격의 변동성이 가장 큰 도시 3, 가장 작은 도시 3개의 평당 분양가격을 boxplot으로 나타내시오
- 2023년 중에서 평당분양가격의 변동성이 가장 큰 도시 3, 가장 작은 도시 3개의 평당분양가격을 boxplot으로 나타내시오
- 변동성은 std함수를 사용하여 측정함

첫 번째 axis 그림부터 생각해 보겠습니다.
먼저 생각해 보면, 평당 분양가격을 지역별로 boxplot을 그리는 것은 바로 이전 문제인 실습 3 - ax2에서 그렸죠. 그러면, 변동성을 어떻게 구할 것인지와 그 변동성을 기준으로 top3, bottom3 지역을 어떻게 골라낼 수 있을지가 관건일 것 같습니다.
변동성 필드를 만들어보겠습니다. 표준편차를 기준으로 계산한다고 문제에서 제시되어 있기 때문에 stdev 함수를 이용해 보겠습니다. 저는 lod 식을 사용하여 연도별 지역별 평당 분양가격의 변동성을 구하였습니다.

계산이 정확히 되었는지 살펴보겠습니다. 2018년도의 지역별 변동성을 확인하고, 내림차순 정렬합니다.

다행히 파이썬 그림처럼 제주, 대전, 서울 지역이 top3이고, 충남, 울산, 세종 지역이 bottom3로 나오네요.
제가 생각한 방법은 이 변동성을 기준으로 순위를 지정하고, 그 순위에 따라 필터링을 해주는 방법입니다. 순위를 계산하는 필드를 만들어보겠습니다. 여기서 sum([lod])를 사용한 이유는 RANK_UNIQUE 함수가 집계함수만 받을 수 있기 때문에 안에 집계함수를 사용해 준 것입니다. 어차피 lod값은 연도별, 지역별 상수값 하나를 가지기 때문에 sum을 해도 같은 값이 나올 것입니다.

이제, 순위가 잘 적용되는지 보겠습니다.
이상하게 모든 지역이 다 1로 나오네요. 이유를 찾아보니, 기본적으로 설정되어 있는 것이 지역별로 순위를 정하는 것이 아니라 테이블 옆으로 순위를 지정하게 되어있습니다. 따라서, 지역별로 순위를 정하게 변경해주어야 합니다.
- 필드 선택 - 마우스 오른쪽 클릭 - 테이블 계산 편집 - 특정 차원 - 지역명 선택


바꿔주니까 다행히 순위가 잘 나오는 걸 확인할 수 있습니다.

이제, 이 순위를 기준으로 해서 상위 3개의 지역과 하위 3개의 지역을 필터링하는 필드를 만들어보겠습니다.
계산 방식은 변동성 순위가 1등 ~ 3등인 지역은 "상위 1-3"으로 분류하고, 15등 ~ 17등인 지역은 "상위 15-17"로 분류하고 다른 등수의 지역은 모두 "기타"로 분류합니다. 그러면, 우리는 필터링을 통해 "상위 1-3"과 "상위 15-17"만 선택하면 되겠네요.

필터까지 만들었으니 본격적으로 그림을 그려보겠습니다.
먼저, 2018년의 지역별 평당 분양가격의 그림을 그려보죠.

이 상태에서 우리가 만들어놓았던 필터 필드를 적용해 보겠습니다. 정확히 6개의 지역이 나왔네요.

하지만, 제가 이 문제에 빨간색 표시를 해둔 이유가 있습니다. 위는 정답과 다른 그림이기 때문인데요, 왜냐하면, 행 선반에 있는 평당 분양가격이 합계로 되어있죠. 이걸 원래 했던 방식대로 차원으로 변경해 주면, 필터가 풀리게 됩니다.

아직 정확한 이유를 찾지 못했는데, 제가 생각한 이유는 아래와 같습니다.
1) SUM(평당 분양가격)으로 했을 때에 lod값을 구한다면, 한 지역의 전용면적별 평당 분양가격의 합계 값이 있을 텐데, 그 값에 대한 변동성이 계산됩니다. 그러면, 각 지역별로 하나의 값을 가지게 되니 순위가 정확히 체크됩니다.
2) 다만, 평당 분양가격을 차원으로 변경하는 순간, 평당분양가격 전체를 보게 됩니다. 따라서, 한 지역 내의 전용면적별 평당 분양가격의 변동성이 계산됩니다. 그러면, 지역별로 순위를 체크하는 것이 아닌 한 지역 내에서 전용면적별 순위가 계산되게 되어, 모든 지역이 다 나오게 됩니다.
따라서, 해결 방안은 변동성 순위를 계산할 때에 계산 방식 자체를 각 지역별로 비교하게 변경해주어야 하는데, 아직 그 방법을 찾지 못했습니다. 그래서 이 문제를 완벽히 풀지 못했습니다.
그래서, 우선은 합계로 둔 상태로 계산하였고 추후 해결 방안을 찾으면 수정하겠습니다.
이런 방식으로 2018년의 결과를 구했으니 2023년은 연도만 바꾸어 똑같이 계산해 주었습니다.


신기하게도 결과는 얼추 비슷합니다 ㅋㅋㅋㅋ. 하지만, 완벽히 풀지 못해서 아쉬움이 남네요. 해결 방안을 찾아보겠습니다.
Insight
: 파이썬 데이터 시각화는 실제 비즈니스에서 잘 사용하지 않는다. 그러나, 태블로에서는 데이터 전처리 등의 작업을 할 수 없으므로 파이썬에서 전처리를 한 후 결과를 이용해야 한다는 단점이 있다. 하지만, 태블로로 시각화 작업을 하게 되면, 대시보드 등을 활용하여 동작 기능을 추가할 수 있다. 또한, 시각화 기능도 더 많이 추가되어 있고 간단하여 처음 배우는 사람도 쉽게 배울 수 있다. 다만, 아직 태블로를 능숙히 사용하기에는 내 실력이 부족한 것 같다. 더 많이 연습해보면서 오늘 못 푼 문제들을 해결할 것이다.
마치며..
오늘은 이렇게 태블로 4주 차까지 배운 내용을 토대로 한 파이썬 풀이를 해봤습니다. 못 푼 문제가 있어 많은 아쉬움이 남는데, 계속 찾아봐야겠습니다. 태블로를 연습하면서 느끼는 것이지만, BI툴로써 정말 최적화된 프로그램인 것 같습니다. 파이썬보다 시각화가 훨씬 쉬우며 동시에 대시보드로 깔끔하게 정리가 되어 비즈니스에서 많이 쓰일만 한 것 같아서 더 연습해보고 싶은 마음이 듭니다. 태블로를 공부하시는 분들 모두 화이팅입니다!
오늘도 읽어주셔서 감사합니다.

'스터디' 카테고리의 다른 글
| [Data Analysis] 데이터 시각화를 위한 태블로 - 3주차 (0) | 2024.07.27 |
|---|---|
| [Data Analysis] 데이터 시각화를 위한 태블로 - 2주차 (1) | 2024.07.11 |
| [Data Analysis] 데이터 시각화를 위한 태블로 - 1주차 (0) | 2024.06.30 |


