
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Computer Vision
- k-fold cross validation
- 데이터과학
- cnn
- sparse coding
- 파이썬 구현
- kt희망나눔재단
- super resolution
- 장학프로그램
- SRCNN
- ResNet
- 개 vs 고양이
- 태블로 실습
- 논문리뷰
- kt디지털인재
- Deep Learning
- Data Augmentation
- VGG16
- 데이터 증강
- object detection
- data analysis
- 데이터 분석
- Semantic Segmentation
- 딥러닝
- 데이터 시각화
- Tableau
- 논문 리뷰
- VGG
- 태블로
- 머신러닝
- Today
- Total
기억의 기록(나의 기기)
[Data Analysis] 데이터 시각화를 위한 태블로 - 2주차 본문
Data Analysis - 태블로 2주차
안녕하세요, 데이터과학을 전공하고 있는 황경하입니다.
오늘은 데이터 시각화를 위한 태블로 2주차 강의를 요약해 보겠습니다.
* 이 글에 적힌 것은 모든 강의 내용을 포함하지 않습니다. 개인적으로 중요하다 생각하는 부분만 표시하고 있으니, 필요하시다면 직접 강의를 들으시는 걸 추천드립니다.
* 위 강의는 BoostCourse에서 무료로 들으실 수 있으며, 이 글에 포함된 내용은 강의 내용을 토대로 한 것임을 밝힙니다.
강의(광고 X): https://m.boostcourse.org/ds121/lectures/243160
데이터 시각화를 위한 태블로
부스트코스(boostcourse)는 모두 함께 배우고 성장하는 비영리 SW 온라인 플랫폼입니다.
m.boostcourse.org
Donut Chart
태블로를 통해 도넛 차트를 표시해 보겠습니다. 도넛 차트의 기본적인 아이디어는 두 개의 파이 차트를 합쳐서 만든다는 것입니다. 기존 파이 차트와 다른 점은 가운데가 뻥 뚫려 있어 그 부분에 레이블을 넣어주면, 가독성이 올라간다는 것입니다. 차근차근 만들어보겠습니다 :)
1) 축 만들기: 파이 차트를 만들기 위한 축을 임의로 설정합니다. 축을 가운데로 잡기 위해 0으로 설정했습니다. (열 더블클릭 - 0 입력). 이렇게 축을 만들고 이번엔 파이 차트로 만들어 줍시다. (마크 - 파이차트 설정)
그러면, 파이 차트 하나가 만들어지는데 도넛 차트는 파이 차트 두 개가 필요하므로 하나 더 복사해야 합니다.
(열에 있는 컨트롤 누른 후 열에 있는 합계(0)을 옆으로 드래그)
* 중요한 건, 왼쪽 파이 차트는 주된 값을 나타낼 것이고, 오른쪽 파이 차트는 나중에 합치면서 가운데를 채워주는 역할을 할 것입니다.

2) 왼쪽 파이 차트 전처리
앞서 언급한 대로, 왼쪽 파이 차트가 주된 역할을 하게 될 것입니다. 따라서, 왼쪽 파이 차트부터 건드려보죠.
우리가 나타내고 싶은 것은 고객 세그먼트 별 매출입니다. 그리고, 그 매출에 따라 내림차순 정렬을 해볼게요.
- 고객 세그먼트 별 매출: 마크 - 색상에 고객 세그먼트 설정 - 각도에 매출 설정
- 오름차순 정렬: 색상으로 설정된 고객 세그먼트 오른쪽 클릭 - 정렬 - 정렬 기준을 필드로 설정 - 정렬 순서를 내림 차순으로 설정 - 필드명을 매출로 설정
2) 파이 차트 합치기 & 오른쪽 파이 차트 설정
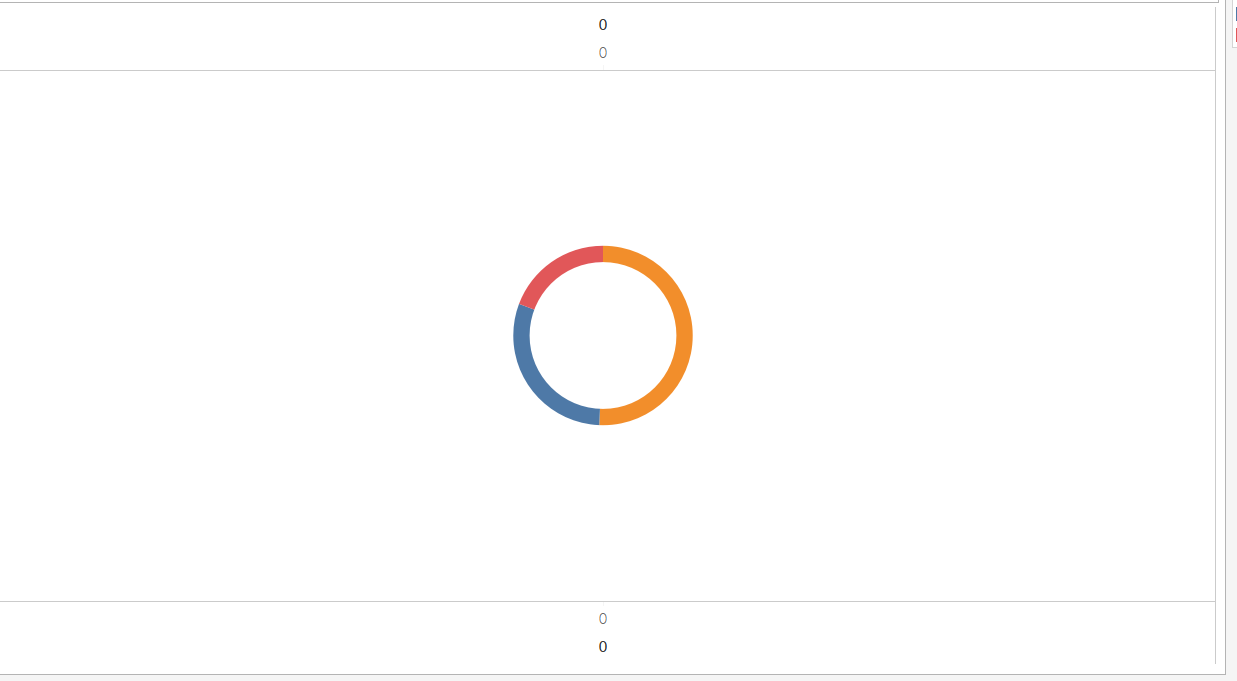
우선, 합치기 전에 왼쪽 파이 차트의 크기를 키워보죠. 크기는 적당히 키워주시면 됩니다. 이 과정이 없으면, 두 파이 차트의 크기가 같아 가려져버립니다. 그리고, 두 파이 차트를 합친 후 두 번째 파이 차트의 색상을 배경과 같은 하얀색으로 바꿔줘서 보이지 않게 해볼게요. 그리고, 머리글과 배경에 있는 선도 없애볼게요.
- 파이 차트 합치기: 열에 있는 두 번째 합계(0)의 오른쪽 클릭 - 이중축
- 두번째 파이 차트 색상 변경: 마크 - 색상 - 하얀색으로 설정
- 머리글 없애기: 축 오른쪽 클릭 - 머리글 표시 버튼 해제
- 선 없애기: 필드 안에 빈 공간에 오른쪽 클릭 - 서식 - 라인 - 열 - 격자선 없음으로 설정 - 영(0) 기준선 없음으로 설정
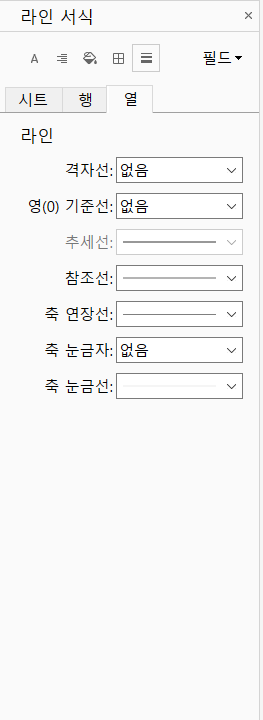

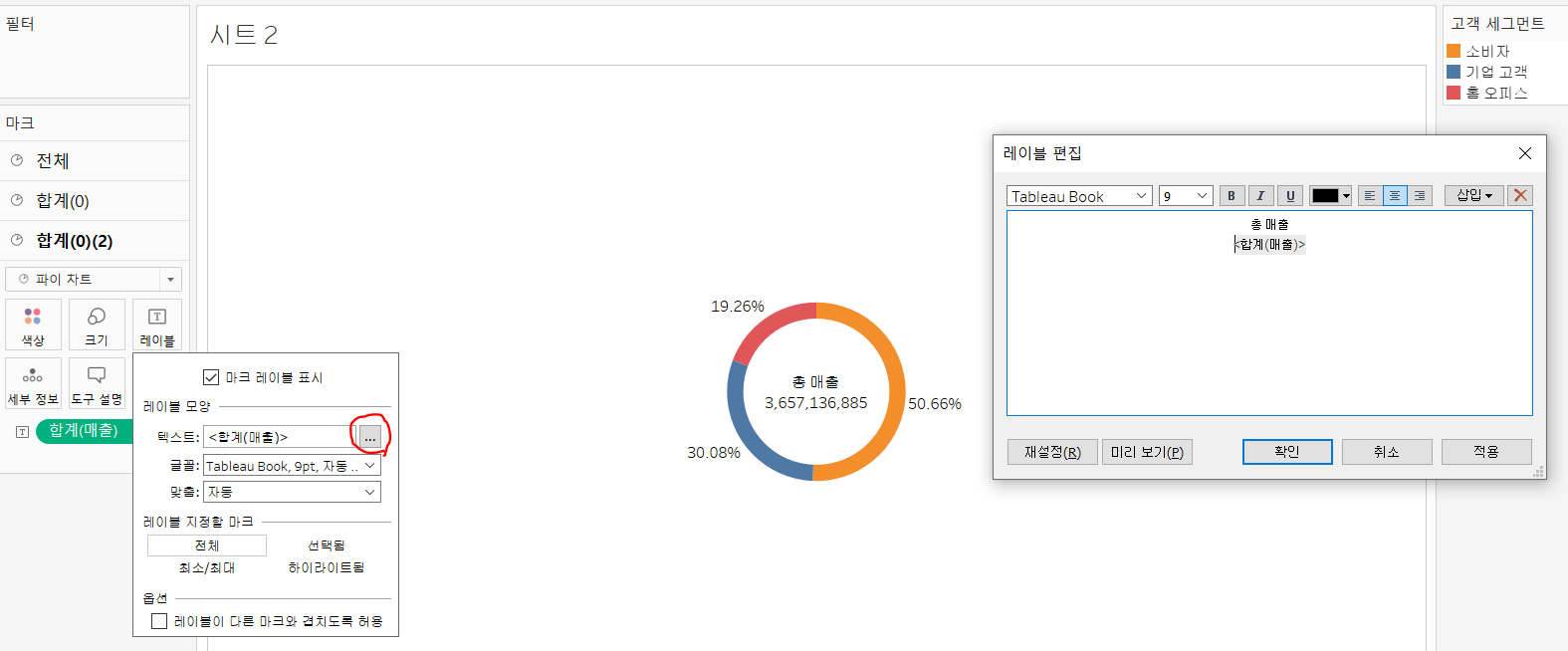
3) 레이블 표시
이렇게 만들어진 결과는 뭘 의미하는지 알아보기 어렵습니다. 따라서, 레이블을 추가해 줄게요. 먼저, 바깥쪽을 차지하는 첫 번째 파이 차트부터 레이블에 매출을 추가하고 그걸 구성 비율로 바꿔줍니다. 그리고, 안 쪽에 있는 파이차트의 레이블을 전체 매출을 표시해 줄게요. 이로써 훨씬 더 가독성을 올릴 수 있습니다. (레이블 추가는 이전 블로깅을 참고해 주세요)
안쪽 파이 차트의 경우에는 총매출이라는 말을 넣어 좀 더 시사하는 바를 명확히 나타냈습니다.
이후, 추가적으로 연도별로 보는 등의 작업을 할 수 있습니다.
Tree Map
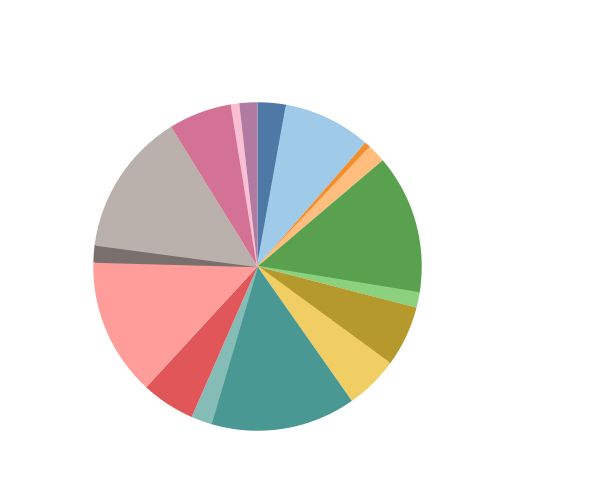
트리 맵의 경우, 파이 차트로 표시하기에는 너무 많은 범주를 가지거나 혹은 범주의 값들이 큰 차이를 보이지 못할 때 사용하면 효과적입니다. 하지만, 저는 범주가 많은 경우에는 파이 차트나 트리 맵보다 막대 차트로 표시하는 것이 더 효율적이라고 생각해서 이 부분을 구체적으로 작성하진 않겠습니다. 간단히 결과로 비교해 보시죠.
아래 그림처럼 범주가 많고, 값이 비슷한 경우에는 파이 차트가 정확히 시사하는 바를 분석하기 어렵습니다.
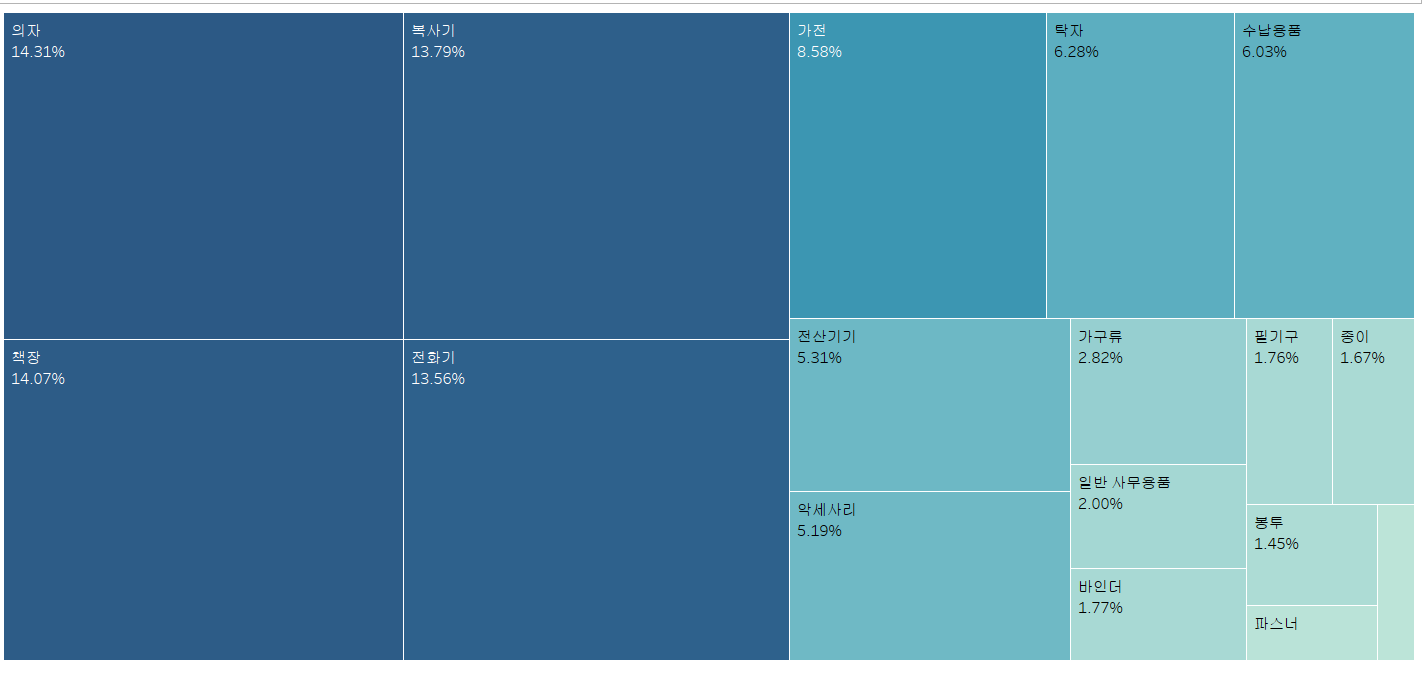
따라서, 표현 방식을 트리 맵으로 표현하여 좀 더 가독성을 올릴 수 있습니다.
또한, 이런 식으로 같은 결과를 막대 차트로 표현하여 그릴 수도 있습니다. 개인적으로는 막대 차트가 더 보기 편한 것 같아서 트리 맵에 대해 자세히 다루진 않았습니다.
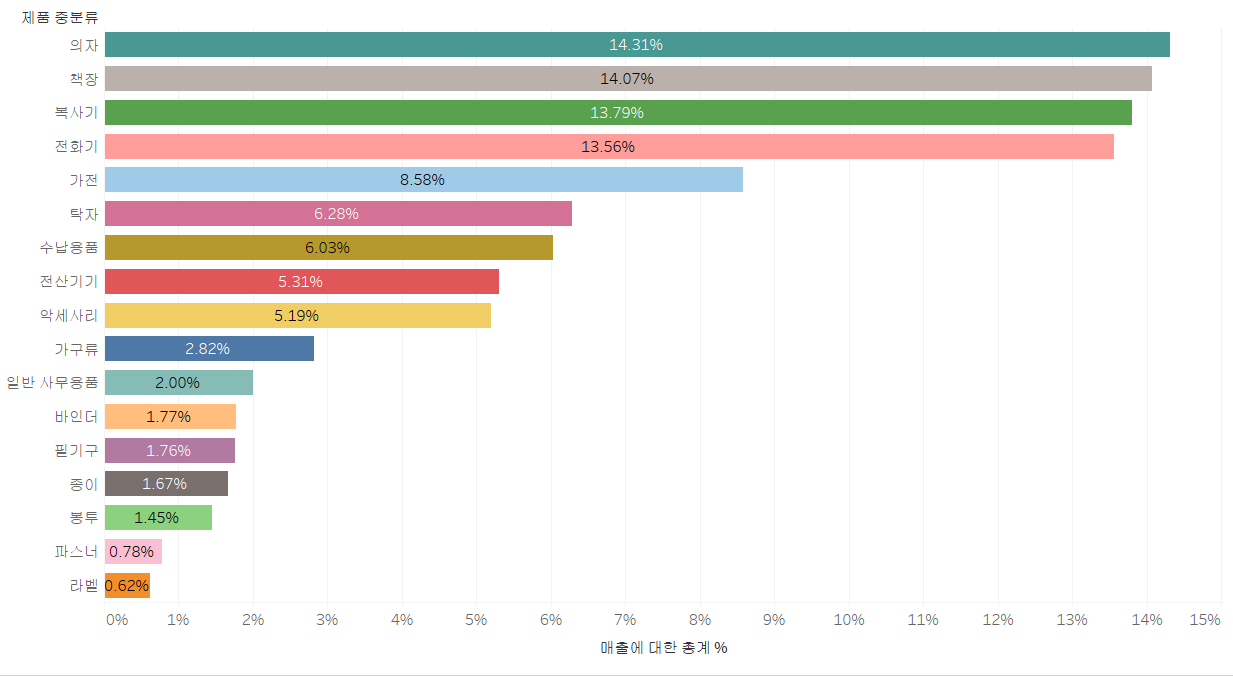
상관관계 분석
이번엔, 두 측정값을 가지고 상관관계 분석을 해보겠습니다. 결과를 보시면, 파이썬의 scatterplot과 굉장히 유사합니다.
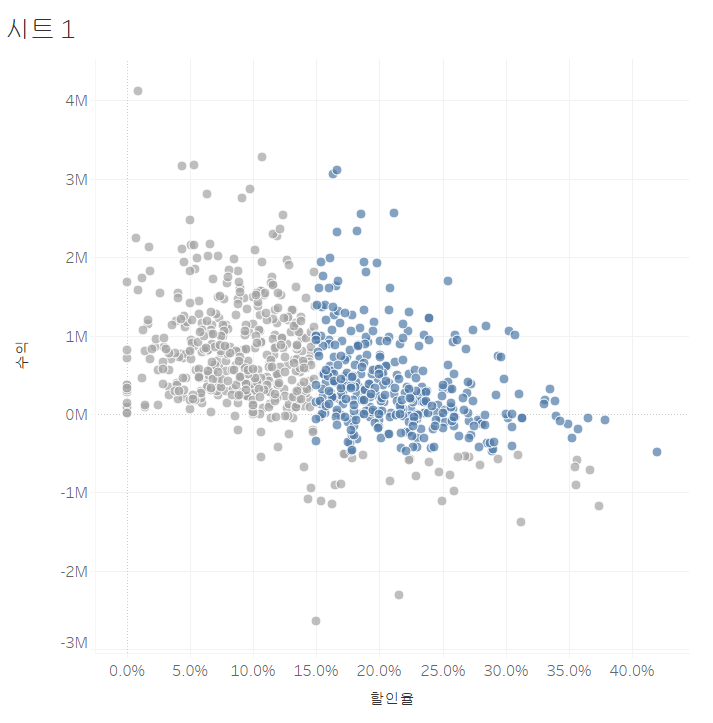
먼저, 할인율과 매출 사이의 상관관계를 살펴보겠습니다. 파이썬으로 생각한다면, 고객 별 할인율에 따른 수익이 있는 테이블에서 x축을 할인율, y축을 수익으로 잡고 scatter plot을 한 것과 같습니다.
- 행 - 수익 입력, 열 - 평균(할인율) (= AVG(할인율)) 입력, 세부정보 - 고객명 설정
- 색상 - 수익으로 설정, 투명도 70%로 변경
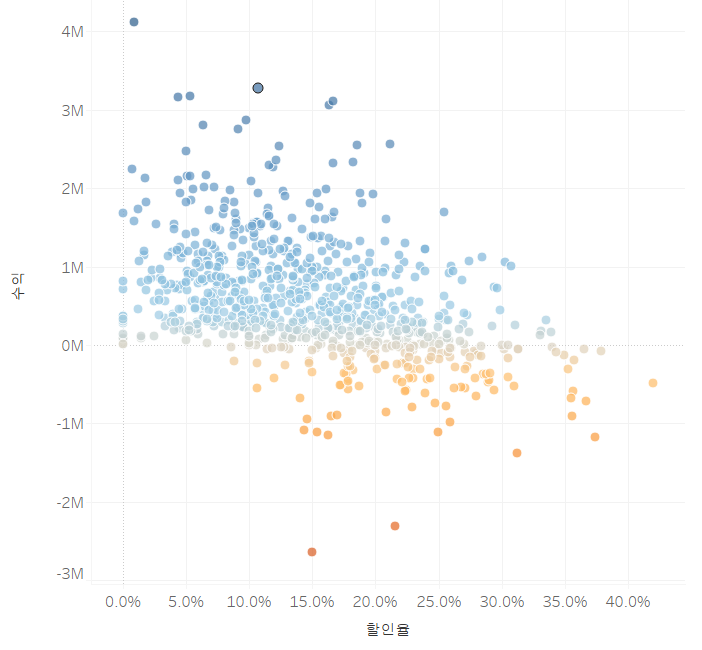
또한, 추세선도 나타낼 수 있습니다. 결과는 마치 선형 회귀 분석을 한 것처럼 나오네요.
- 분석 패널 - 추세선 - 선형
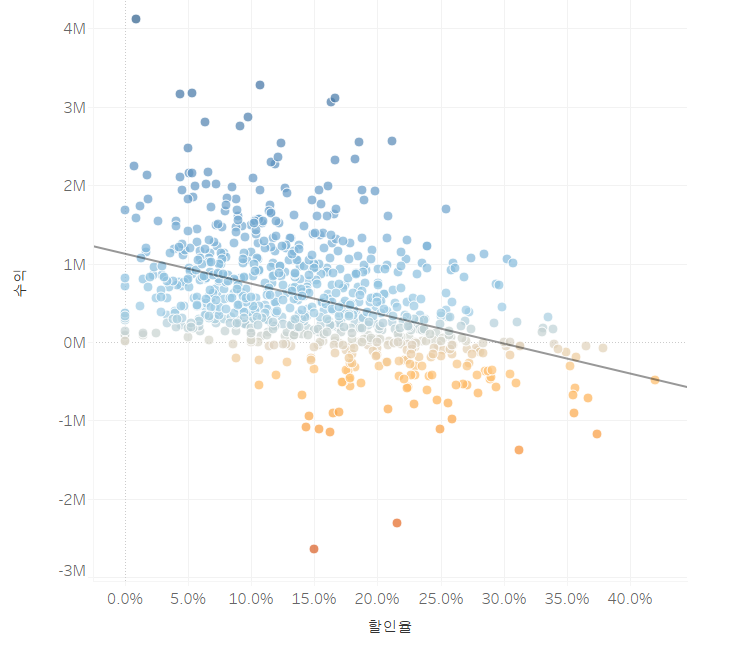
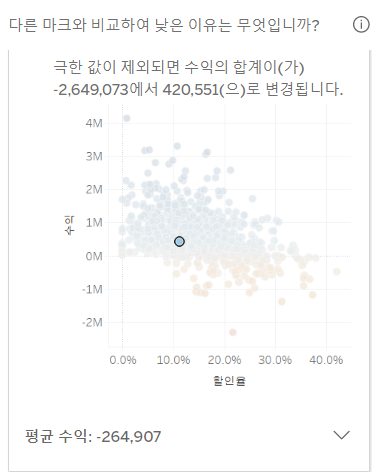
여기서 태블로의 엄청난 장점이 나타납니다. 이 중 가장 작은 수익을 보이는 값에 마우스를 대고 클릭 후 전구 모양을 누르면 데이터 설명이 뜹니다. 여기서는, 이 고객이 왜 수익이 이렇게 낮은 지를 태블로가 알아서 분석하여 알려줍니다.
이렇게 가장 낮은 수익을 보이는 이서준 고객은 하나의 극한값을 가지고 있으며, 이 극한값을 제외하면 오히려 다 평균에 가까운 수익을 보여줍니다.
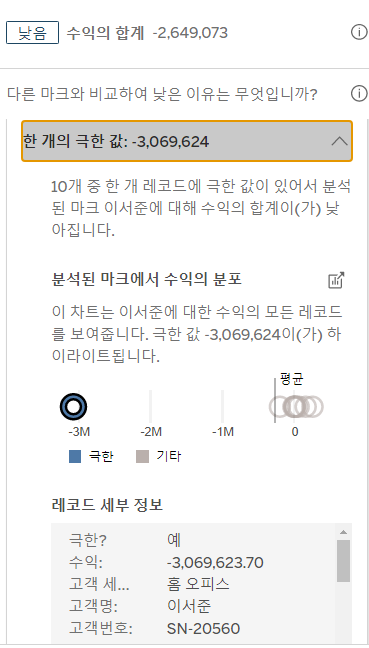
또한, 이 극한 값을 제외했을 때 어느 정도의 수익을 보이는지와 그에 따른 위치도 표시해 줍니다. 제외하고 나니 평균의 수익을 보이네요. 즉, 한 번 크게 잃어서 수익이 낮은 것으로 나타남을 알 수 있습니다.
이제 가장 하이라이트이자 데이터 분석에서 태블로의 또 다른 장점인 매개변수 설정을 보여드리겠습니다.
매개 변수 설정은 축으로 잡습니다. 즉, 할인율과 수익에 대한 매개변수 두 개를 설정해 주겠습니다. 이 매개변수를 설정하게 되면, 할인율이 변화할 때나 수익이 변화할 때 혹은 둘 다 변화할 때 고객이 얼마나 포함되는 지를 나타낼 때 사용됩니다.
빨간색 동그라미 부분을 눌러 매개변수 만들기 선택합니다.
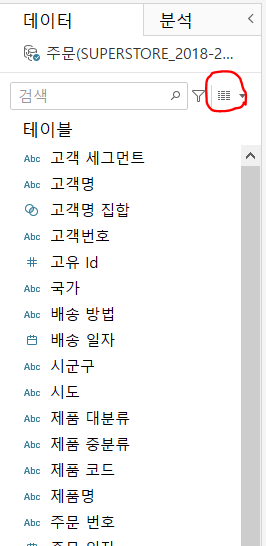
매개 변수명을 설정하고, 데이터 유형과 값 범위를 설정해 줍니다. 값 범위는 해당 축의 범위를 설정하면 되고, 저는 이미 만들어놓아서 이미 있다고 뜨네요.
그 후, 만들어진 매개변수에서 매개 변수 표시를 누르면, 아래 사진처럼 버튼이 생성되게 됩니다.
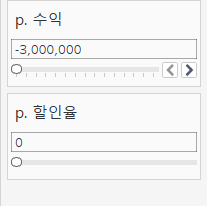
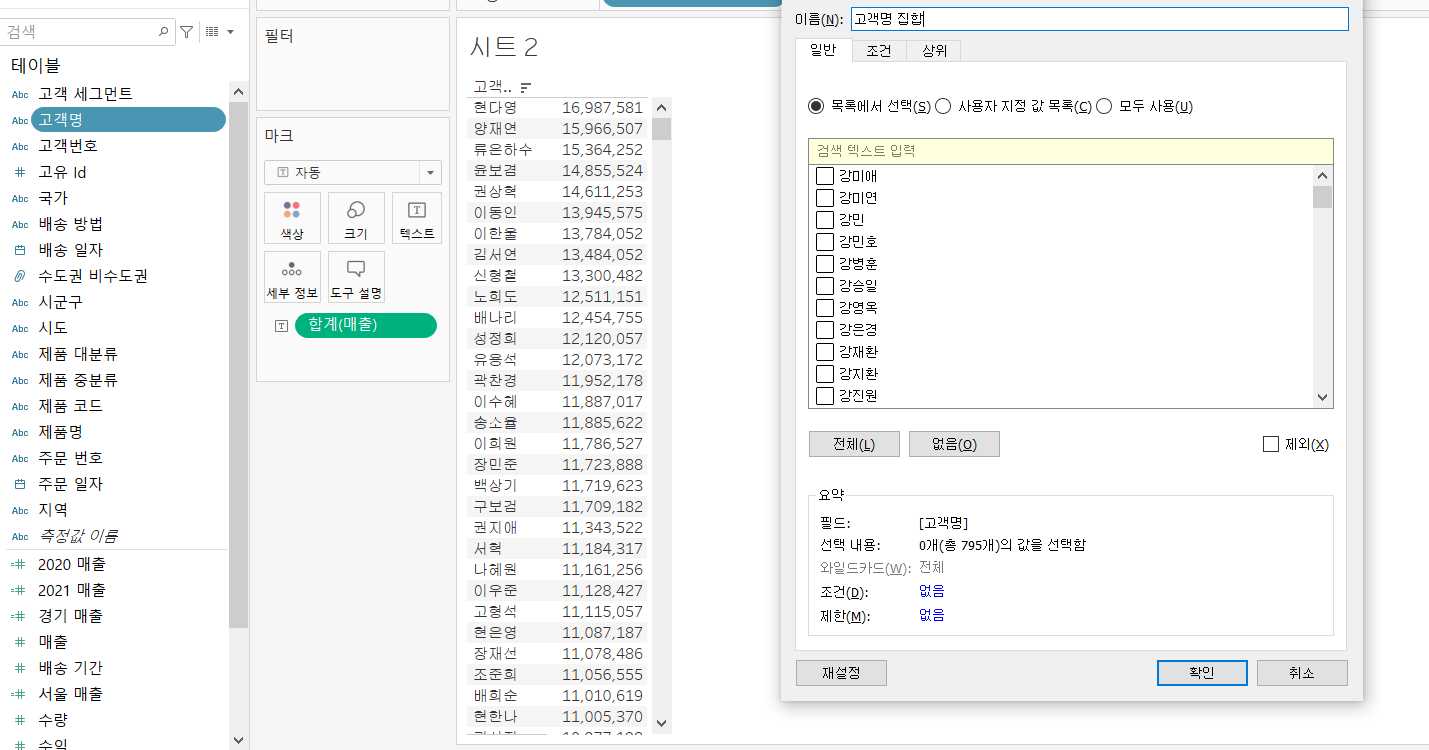
우리는 이 수익과 할인율이라는 변수의 값이 변할 때 어떤 고객이 포함되지 않고, 어떤 고객이 포함될지를 보고 싶습니다. 즉, 수익이 p.수익이라는 매개변수보다 크며 동시에 평균 할인율도 p.할인율이라는 매개변수보다 큰 값만 표시하고 싶습니다. 그러면, 표시할 대상은 고객이 될 것이니 고객명에서 위 조건을 설정할 하위 셋을 만들어줘야 합니다.
- 고객명 - 만들기 - 집합 - 조건 - 수식 기준 - 조건 입력
- 조건: sum(수익) >= [p. 수익] and avg(할인율) >= [p. 할인율]
위 과정을 거치면 아래처럼 고객명 집합이라는 고객의 서브셋이 만들어짐을 알 수 있습니다. 이제 이를 색상에 넣어주면, 매개변수를 변경할 때마다 조건에 만족하는 애들만 색상으로 표시하게 되죠.
Combined Axis & 필드 생성
이번엔, 축을 결합하는 것과 새로운 필드를 생성하는 것을 보여드리겠습니다. 필드를 새로 생성하는 것은 내가 가지고 있는 필드(=데이터)에서 특정 조건에 해당하는 데이터만 보고 싶을 때 사용합니다. 예를 들어, 주문 일자가 연도 별로 되어 있는데, 여기서 2020년에 해당하는 매출만 보고 싶은 경우에는 2020 매출이라는 새로운 필드를 생성할 수 있죠. 실제 비즈니스에서 많이 사용될 것 같습니다.
그러면, 측정값에는 우리가 새로 만든 필드가 들어가야 합니다. 따라서, 필드를 먼저 생성해 줍시다.
- 데이퍼 패널 - 빨간색 동그라미 클릭 - 계산된 필드 만들기 - 제목을 2020 매출로 설정 - 조건 입력
- 조건: IF YEAR([주문 일자]) = 2020 THEN [매출] END

2020년도 매출과 함께 2021년도 매출도 라인으로 표시해 보겠습니다. 그러면, 2021 매출도 동일하게 만들어줘야겠네요. 위와 동일한 과정을 거쳐서 해도 되고, 아니면, 해당 필드를 우클릭 후 복제하여 이름과 조건만 변경하셔도 됩니다.
이제 시각화를 해보죠. 2020년도 매출 먼저 그리겠습니다. 값은 SUM(매출)이 되므로 단일값으로 표현될 것입니다. 그래서 2020년도의 월 별 매출 합계를 보도록 하죠.
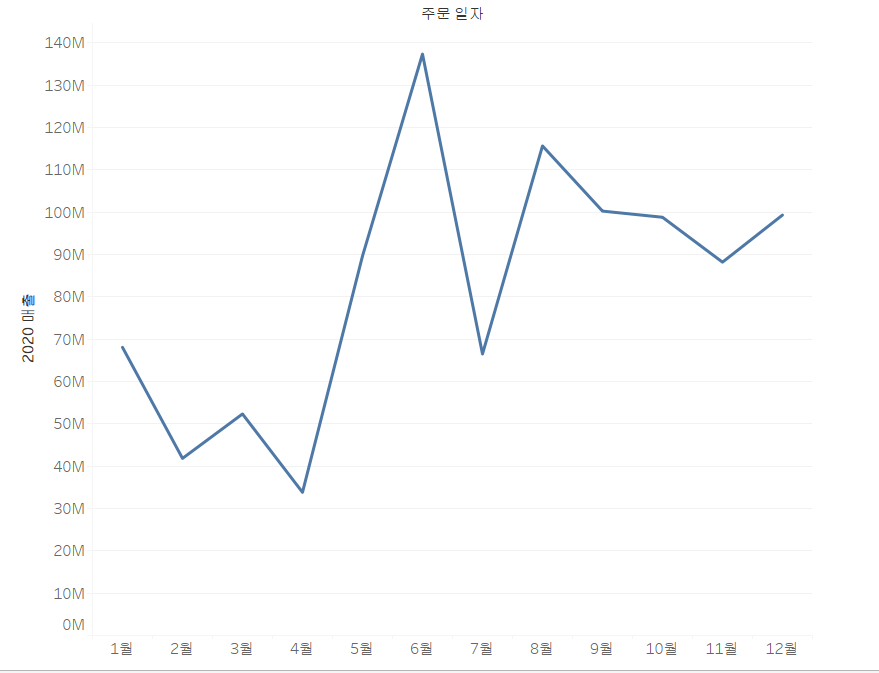
이제, combined axis 즉, 축을 결합해 보겠습니다. 축을 결합할 때에는 같은 마크를 사용하게 됩니다.
열(=2020 매출)에 2021 매출을 넣어줍시다.
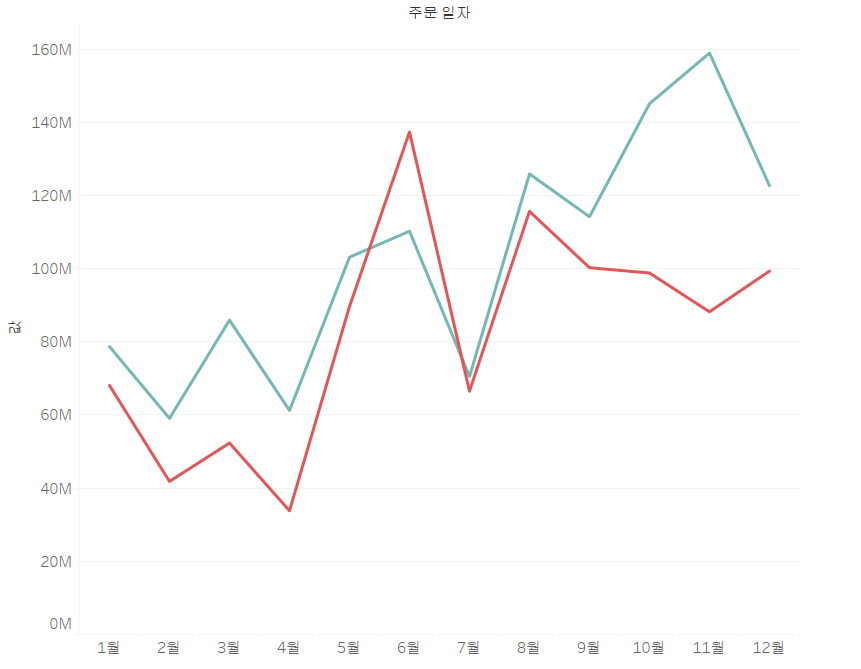
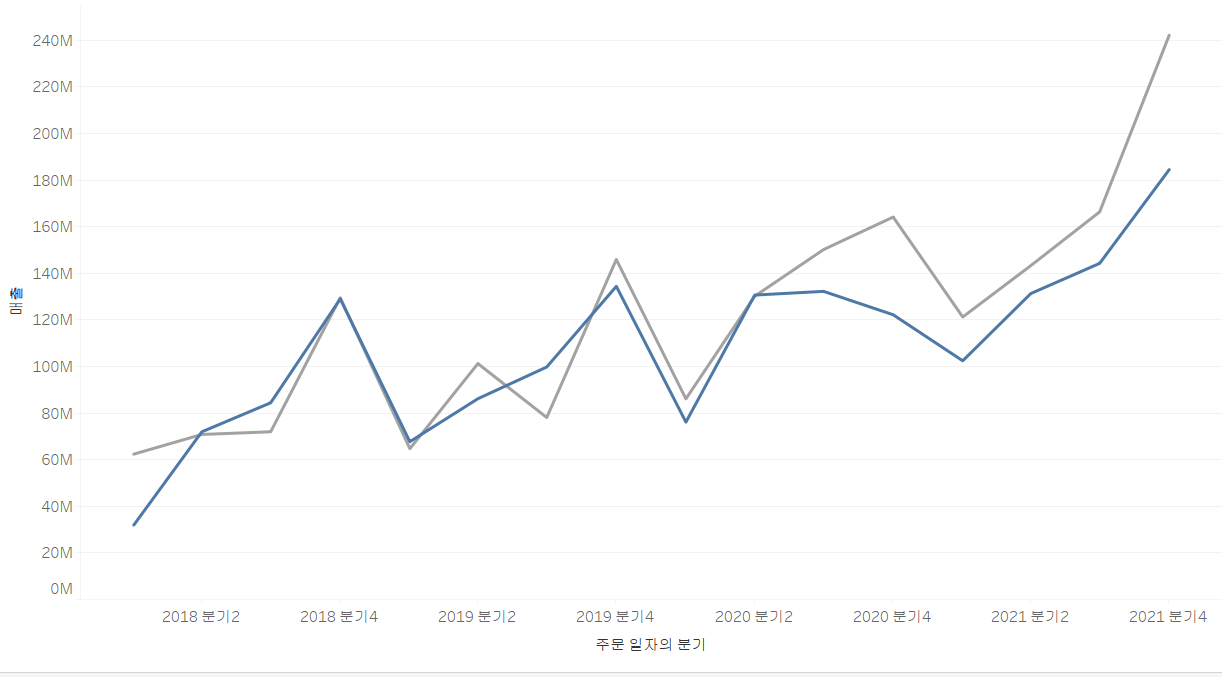
이런 식으로, 2020년도와 2021년도의 매출을 쉽게 비교할 수 있습니다. (빨강: 2020 매출, 청록: 2021 매출)
레이블도 표시할 수 있는데, 마크에 레이블을 넣으면 같은 레이블이 들어가집니다. 그래서, 상단에 있는 T를 클릭해 줍시다.

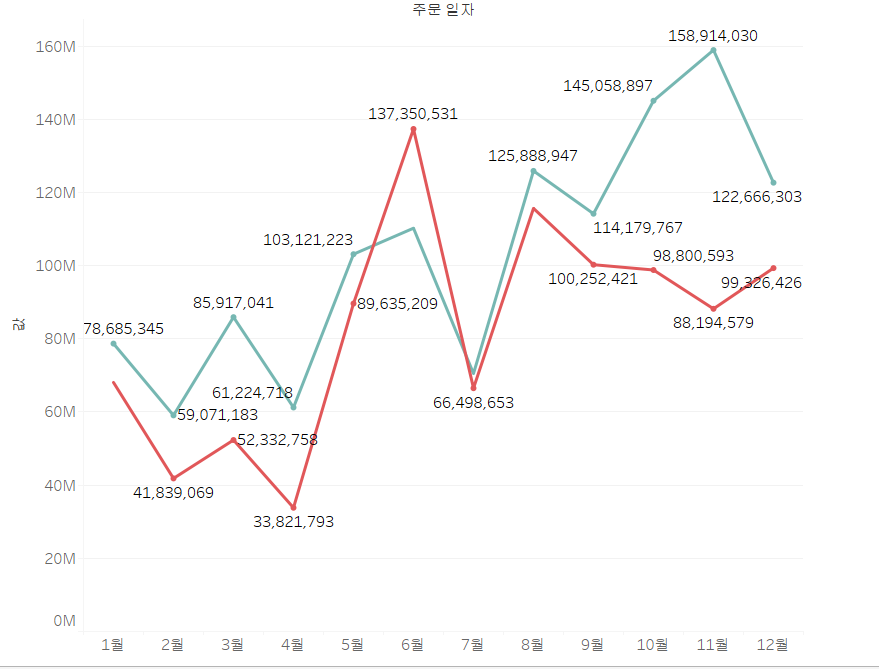
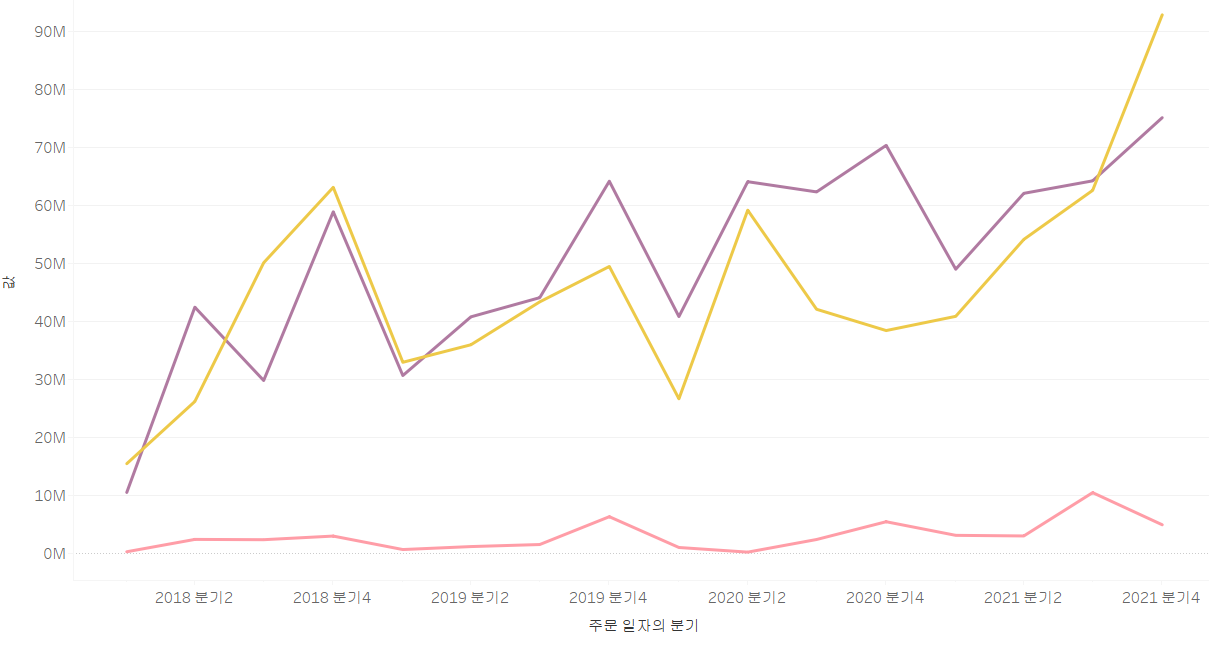
하지만, 그림이 이렇게 나오는 경우도 있을 수 있습니다. 바로, 값들의 차이가 심할 때인데요.
노란색은 경기도의 분기별 매출, 보라색은 서울의 분기별 매출, 분홍색은 제주도의 분기별 매출을 표현한 것입니다. 이렇게 보면, 차이가 굉장히 심하다 보니 한쪽이 뚝 떨어져 보기 좋지 않습니다.
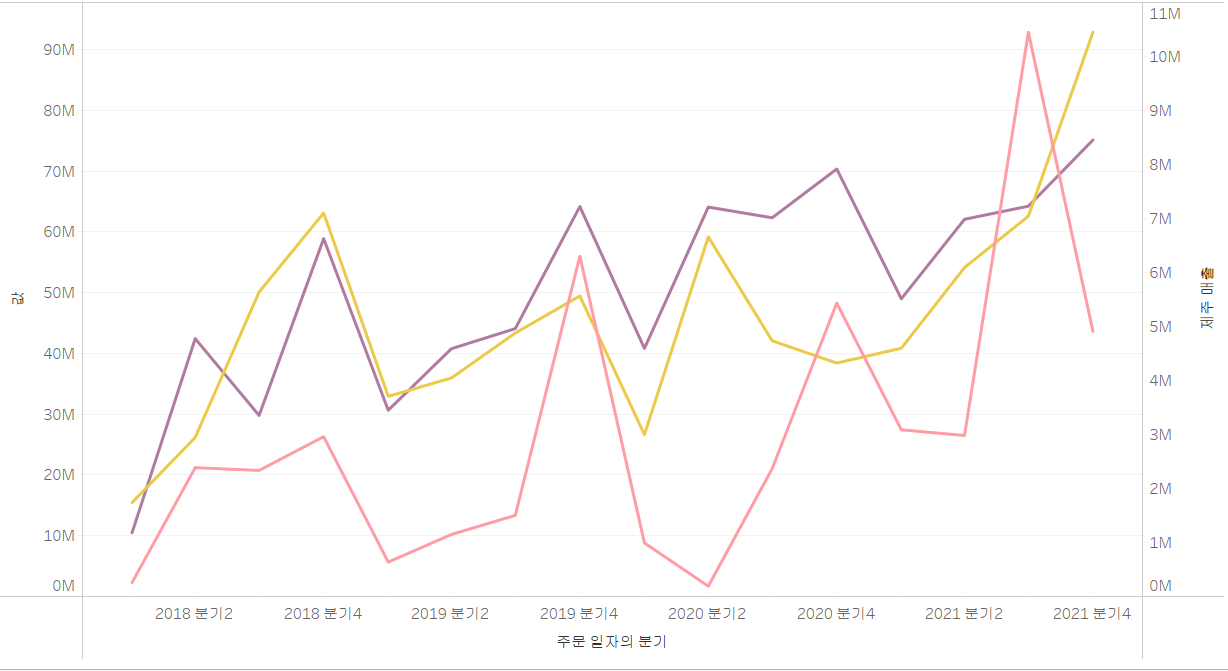
이런 경우에는 차라리 새로운 축에다가 제주 매출을 입력하여 그 축을 제주 매출에 핏 시켜서 표현할 수 있습니다. 다만, 제가 생각하기에는 위 그림이 더 낫지 않나 싶습니다. 아래 그림은 오히려 보는 사람들로 하여금 혼동을 줄 수 있을 것 같아요.
그룹 & 집합
이번엔 우리가 묶어서 보고 싶은 그룹과 그렇지 않은 그룹을 나누어서 표시해 보겠습니다. 미리 말씀드리자면, 그룹과 집합은 태블로에서 아예 다른 개념입니다. 그룹은 말 그대로 우리가 묶고 싶은 필드의 범주를 묶는 것이고, 집합은 수학에서 말하는 다이어그램처럼 거기에 해당하느냐 해당하지 않느냐로 나누는 IN/OUT으로 표현되게 됩니다.
먼저, 묶고 싶은 그룹을 선택해 보죠. 강의의 내용과 동일하게 수도권과 비수도권으로 나눠서 매출을 표시해 보겠습니다.
- 그룹화할 필드(시도) 선택 - 만들기 - 그룹 - Ctrl을 누른 상태에서 묶을 범주 선택 - 그룹 클릭 - 기타 포함 선택 - 기타 이름을 비수도권으로 만들기 - 확인

이렇게 그룹화를 했으니 각 그룹별 매출을 그려보죠. 표현방식은 라인으로 설정합니다.
수도권은 3개의 지역밖에 포함하지 않았고, 비수도권은 다른 지역들을 모두 포함하는데도 그렇게 큰 차이는 나지 않습니다.
(파랑: 수도권, 회색: 비수도권)
이번엔, 집합을 공부해 보겠습니다. 집합은 앞서 언급한 것처럼, IN/OUT으로 표현됩니다.
먼저, 우리는 고객 별 매출을 표현할 건데, 그중 상위 10명 집합을 만들어보겠습니다.
고객명 우클릭 - 만들기 - 집합 - 상위 - 필드 기준 - 상위 10명으로 설정
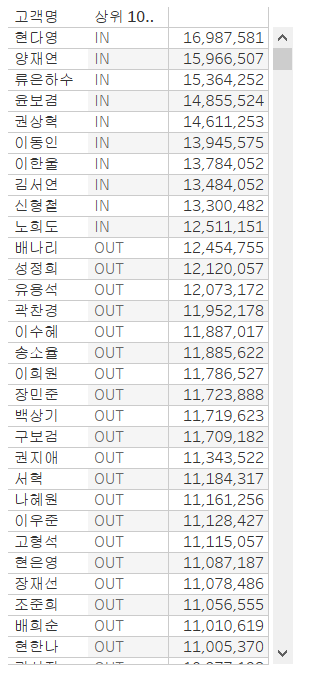
위와 같이 상위 10명만 IN으로 표시됨을 알 수 있습니다. 그러면, 앞서 언급을 다이어그램과 같다고 했으니 차집합과 합집합의 개념도 존재하겠죠? 위와 같은 과정을 반복하여 상위 20명 집합을 만들고, 두 집합을 동시에 선택 후 결합된 집합 만들기를 클릭합니다. 우리는 11위부터 20위까지 표현할 것이므로 상위 20에서 상위 10명을 제외하는 차집합을 계산해야 합니다. 따라서, 아래와 같이 설정합니다.
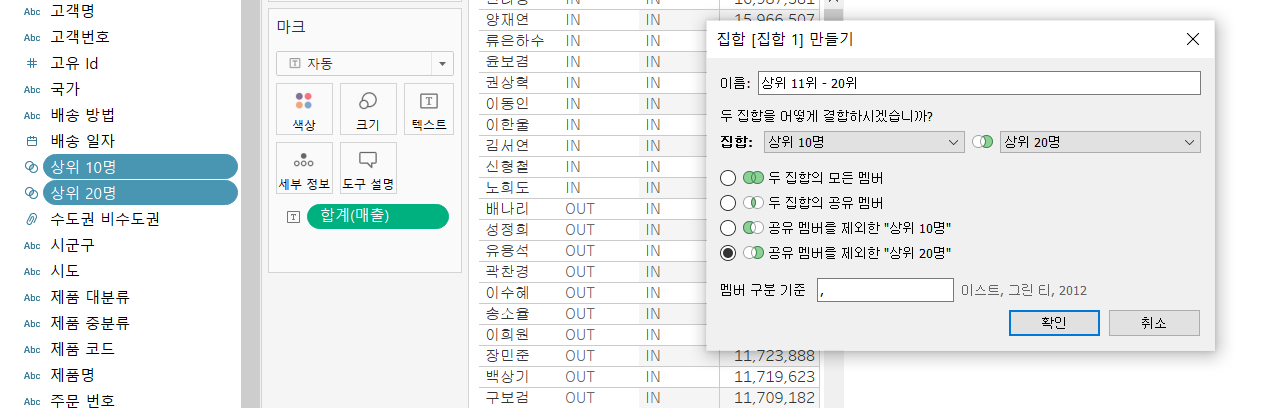
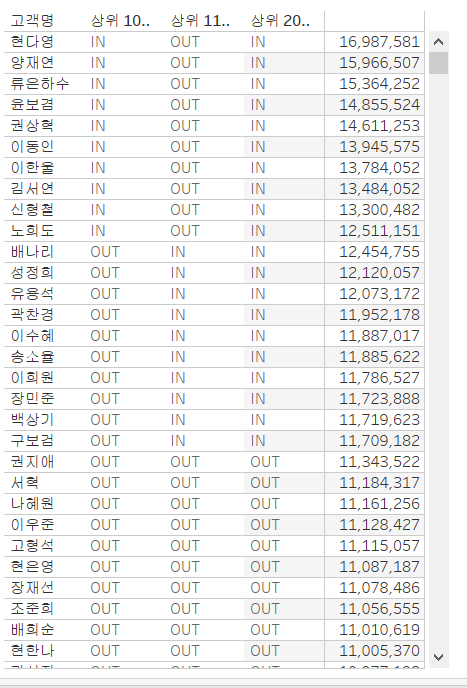
이렇게 만든 집합들은 필터에 넣어 해당 집합에 IN으로 표시되는 개체들만 표시할 수 있습니다.
이후에 설명되는 계층이나, 맵 같은 경우는 사실 python에서 folium을 통해 모두 대체될 수 있어 이번 포스팅에 포함하지 않았습니다. 다만, python과 tableau를 모두 사용할 수 있는 능력을 배양하는 것이 목표이기에 folium을 통한 결과와 tableau를 통한 결과가 같게 만들 수 있도록 공부해 볼 생각입니다. 글이 길어지니 관련 내용은 그 포스팅에서 더 자세히 다뤄보겠습니다.
Insight
: 태블로를 2주차까지 수업을 들었는데, 너무나 긴 시간이 걸렸다. 사실 수업을 들으며 실습을 하고 퀴즈까지 푸는 데에는 3시간도 걸리지 않는다. 그런데, 이를 한 번 더 풀어보면서 블로그에 설명까지 하는 블로깅 작업 시간이 더 걸리는 것 같다. 따라서, 올리는 방식의 전환이 필요하다는 생각이 든다. 고작 한 주차 진도를 나가는 데에 거의 6시간 ,, 앞으로는 수업 내용을 리뷰하기보다는 내가 학업에서 배운 Python Visualization 결과를 Tableau로 옮기는 작업을 해보려 한다. 물론, 작업 파일을 올려서 같이 공유하면 좋겠지만 학업에서 사용한 데이터이기에 저작권이 나에게 없어 공유할 수 없는 점은 아쉽겠지만, 푸는 과정은 Tableau 수업들에서 배운 내용들이기에 독자들이 스터디하기에는 나쁘지 않을 것 같다.
마치며..
오늘은 이렇게 데이터 시각화를 위한 태블로 2주차를 마쳤습니다. 영상을 통해 실습을 같이 하고, 그걸 블로그에 옮기면서 혼자 다시 다 실행해 봤습니다. 확실히 공부는 더 되는 것 같은데, 시간이 배로 드니 ,, 5주차까지 계속 남길지는 모르겠습니다. 만약, 올리더라도 이런 강의 내용이 아닌 python과 병행하는 스터디를 올리지 않을까 싶습니다.
오늘도 긴 글 읽어주셔서 감사합니다.

'스터디' 카테고리의 다른 글
| [Data Analysis] 데이터 시각화를 위한 태블로 - 4주차 (0) | 2024.07.27 |
|---|---|
| [Data Analysis] 데이터 시각화를 위한 태블로 - 3주차 (0) | 2024.07.27 |
| [Data Analysis] 데이터 시각화를 위한 태블로 - 1주차 (0) | 2024.06.30 |


