
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 파이썬 구현
- Data Augmentation
- 개 vs 고양이
- kt희망나눔재단
- super resolution
- VGG
- Computer Vision
- ResNet
- 태블로 실습
- Tableau
- SRCNN
- 데이터 시각화
- cnn
- sparse coding
- 데이터 분석
- data analysis
- VGG16
- 논문 리뷰
- k-fold cross validation
- 머신러닝
- 데이터과학
- 데이터 증강
- 장학프로그램
- 논문리뷰
- Deep Learning
- kt디지털인재
- object detection
- Semantic Segmentation
- 딥러닝
- 태블로
- Today
- Total
기억의 기록(나의 기기)
[Data Analysis] 데이터 시각화를 위한 태블로 - 3주차 본문
데이터 시각화를 위한 태블로 - 3주 차
안녕하세요, 데이터 과학을 전공하고 있는 황경하입니다.
저번 포스팅에 이어 오늘은 태블로 3주 차 내용을 공유해 보겠습니다.
그전에, 이번 포스팅부터 글의 구성을 변경하였습니다. 그전까지는 부스트코스 수업에 대한 내용을 요약하는 방식의 포스팅을 해왔는데, 3주 차부터는 수업 내용이 아닌 학업에서 배웠던 파이썬 데이터 시각화의 결과를 타블로로 구현해 보겠습니다.
글의 구성은 아래와 같습니다.
- 파이썬 시각화의 결과 제시.
- 태블로로 구현하는 과정 설명
- 결과 비교
Data Desription
제가 사용할 데이터는 학업에서 배웠던 "전국평균 분양가격 (2015년10월~2023년6월).csv" 파일입니다. 파일에 대한 소유권이 저에게 없기 때문에 이 글에 직접 첨부를 하긴 어려울 것 같습니다. 공공데이터포털 사이트에도 비슷한 데이터셋이 많기 때문에 참고하시면 좋을 것 같습니다.
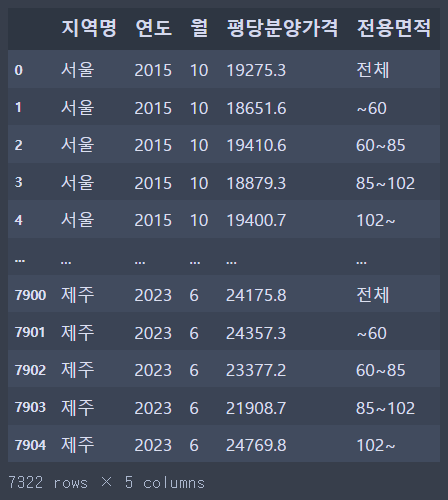
CSV 파일을 파이썬으로 불러와서 전처리를 모두 끝냈다면, 아래 코드를 통해 Microsoft Excel로 저장하여 태블로에 연결하여 사용하실 수 있습니다.
| pip install xlsxwriter df_prep.to_excel(r'저장할 경로/저장할 파일 이름.xlsx', index=False, engine='xlsxwriter') |
이렇게, 태블로에서 사용할 파일을 로컬에 저장했다고 가정하고 본격적으로 파이썬 시각화의 결과를 태블로로 구현하는 과정을 보여드리겠습니다. 총 6문제를 같이 풀어보겠습니다.
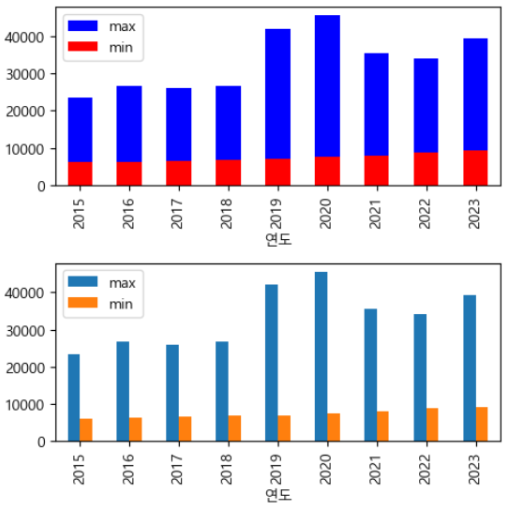
실습 1
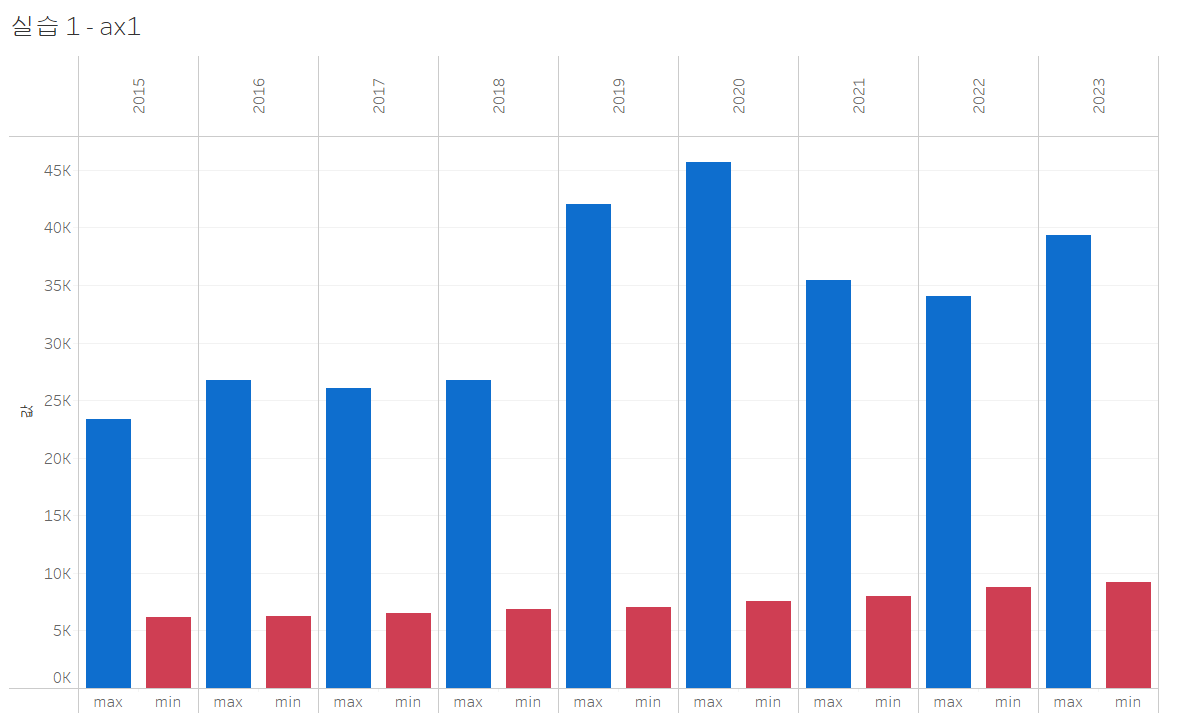
- 1) 연도별 평당 분양가격의 최솟값을 구하시오 (mn)
- 2) 연도별 평당 분양가격의 최댓값을 구하시오 (mx)
- 3) mn, mx를 이용하여 ax1, ax2에 아래와 같이 그림을 그리시오
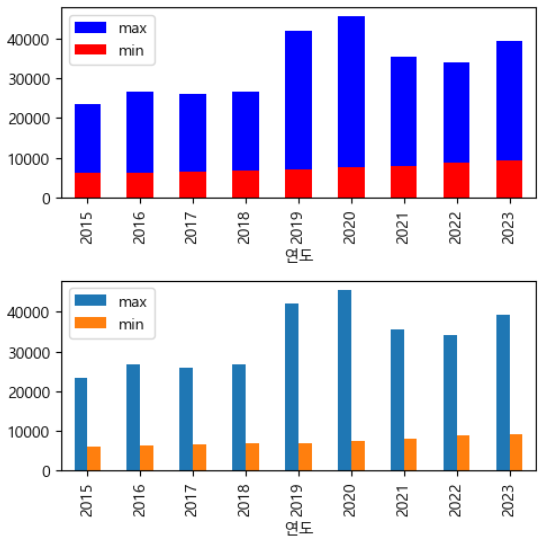
위 결과를 태블로로 구현할 것입니다. 첫 번째 axis 그림부터 구현해 보겠습니다.
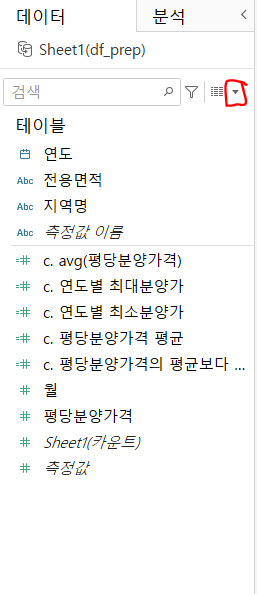
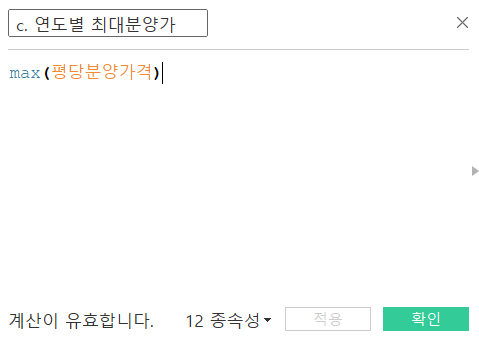
우선, 연도 별 평당 분양가격의 최솟값과 최댓값을 구해야겠네요. 새로운 필드를 만들어줍시다.
- 빨간 네모 버튼 - 계산된 필드 만들기
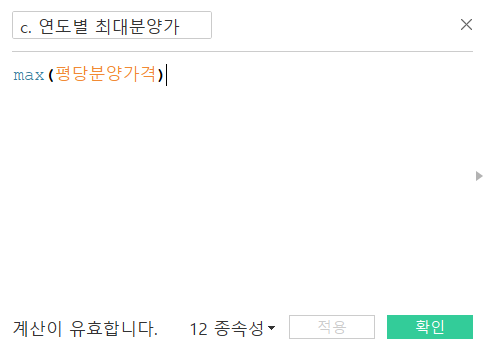
이름은 c. 연도별 최대분양가, c. 연도별 최소분양가로 지어주겠습니다.
계산 식은 간단합니다. 최댓값과 최솟값을 구하는 것이니 max와 min함수를 사용하면 되겠네요.
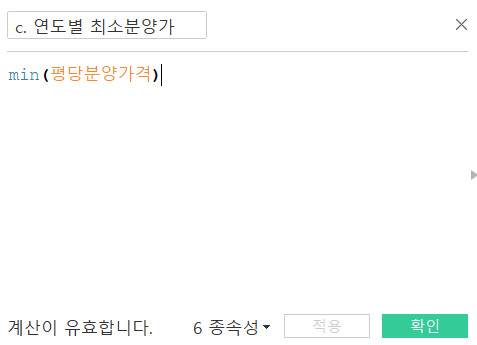
이제 본격적으로 그림을 그려보죠. 열 선반에 연도를 올리고, 행 선반에 c. 연도별 최대분양가를 올려줍시다.
이렇게 그리면, 연도 별 최대 분양가가 그려집니다.
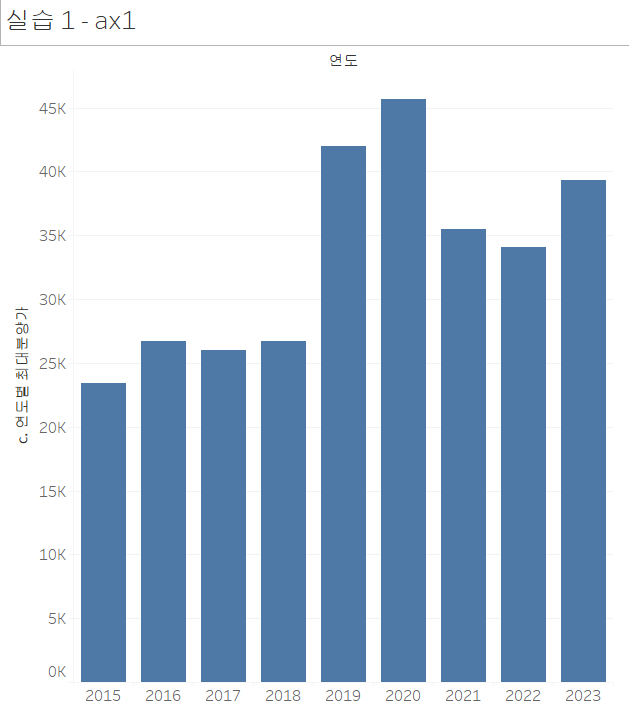
하지만, 파이썬 결과를 보면 최댓값과 최솟값이 겹쳐서 동시에 그려져 있죠. 이중축을 이용해 연도별 최대 분양가 그림과 연도별 최소 분양가 그림을 겹쳐줘야 할 것 같습니다.
이중 축을 수행하는 방식은 간단합니다.
- 행 선반에 오른쪽 필드값 선택 - 마우스 오른쪽 클릭 - 이중축
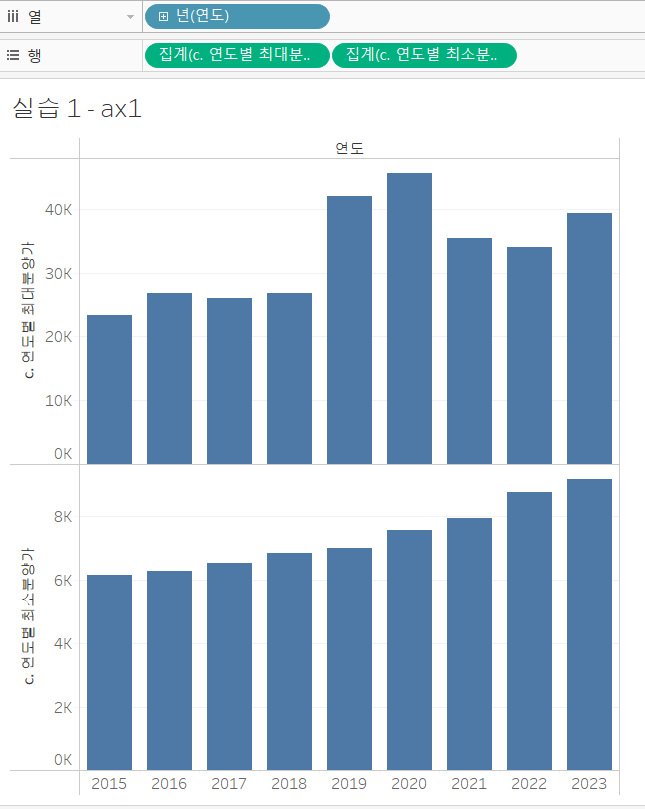
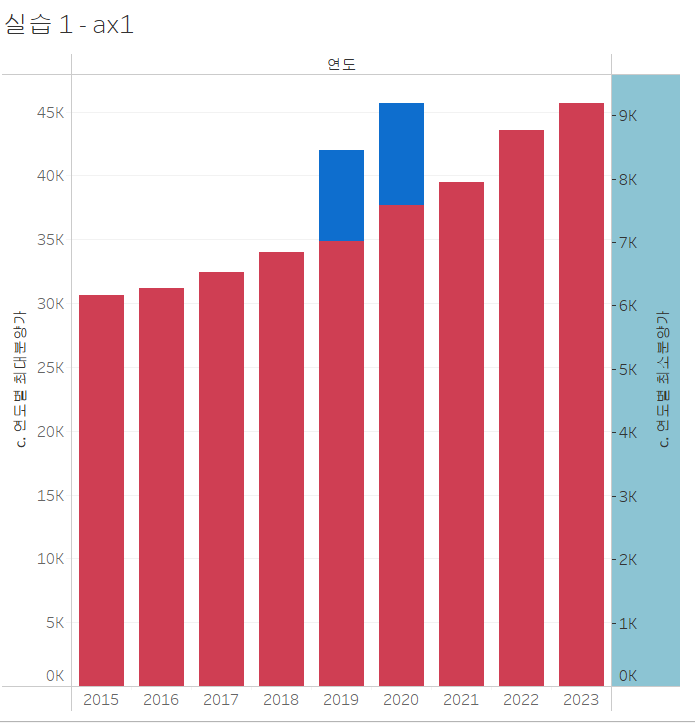
이중축을 실행했는데, 그림이 이상하죠. 양쪽 축의 범위가 서로 다르기 때문입니다. 오른쪽 축의 범위가 훨씬 더 작네요. 범위를 동일하게 맞춰주겠습니다.
- 오른쪽 축 선택 후 오른쪽 클릭 - 축 동기화
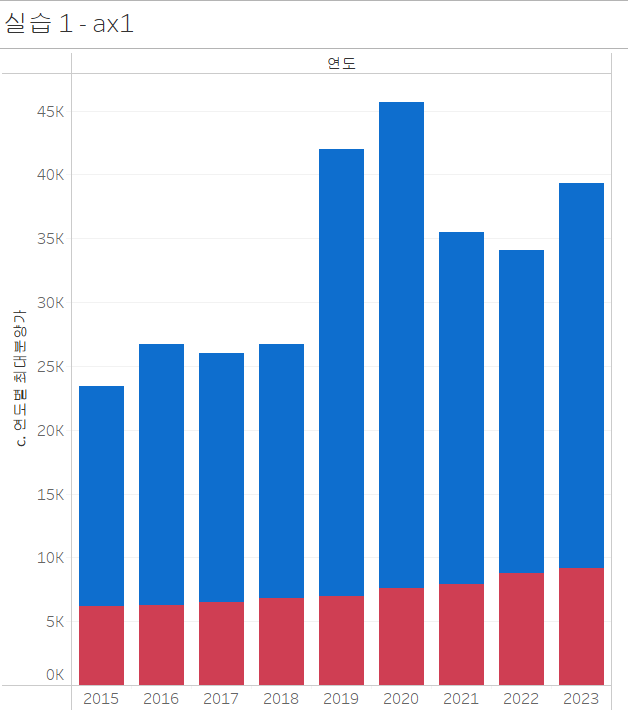
어떤가요? 제법 비슷하지 않나요? 디테일한 부분만 조금 더 잡아줍시다. 예를 들어, 왼쪽의 머리글을 지우거나 레이블을 회전시키는 작업을 해주면 더 비슷해지겠네요.
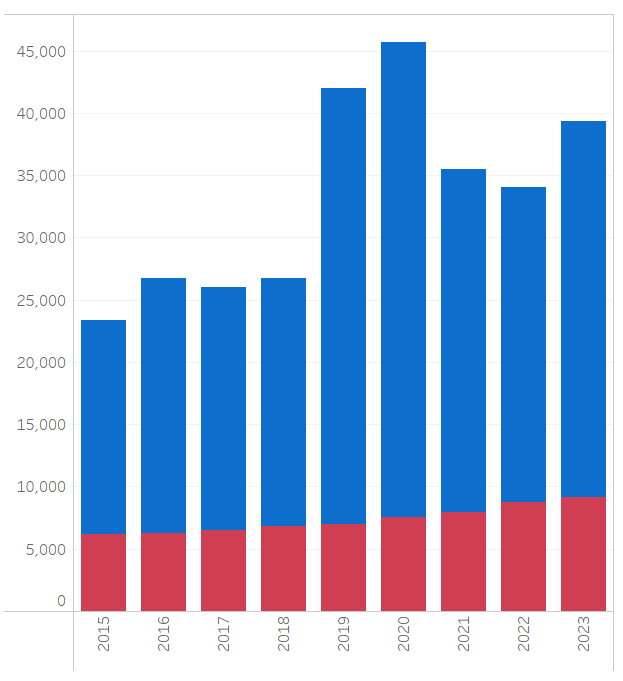
첫 번째 axis 그림을 완성된 것 같으니 두 번째 axis 그림으로 넘어가겠습니다.
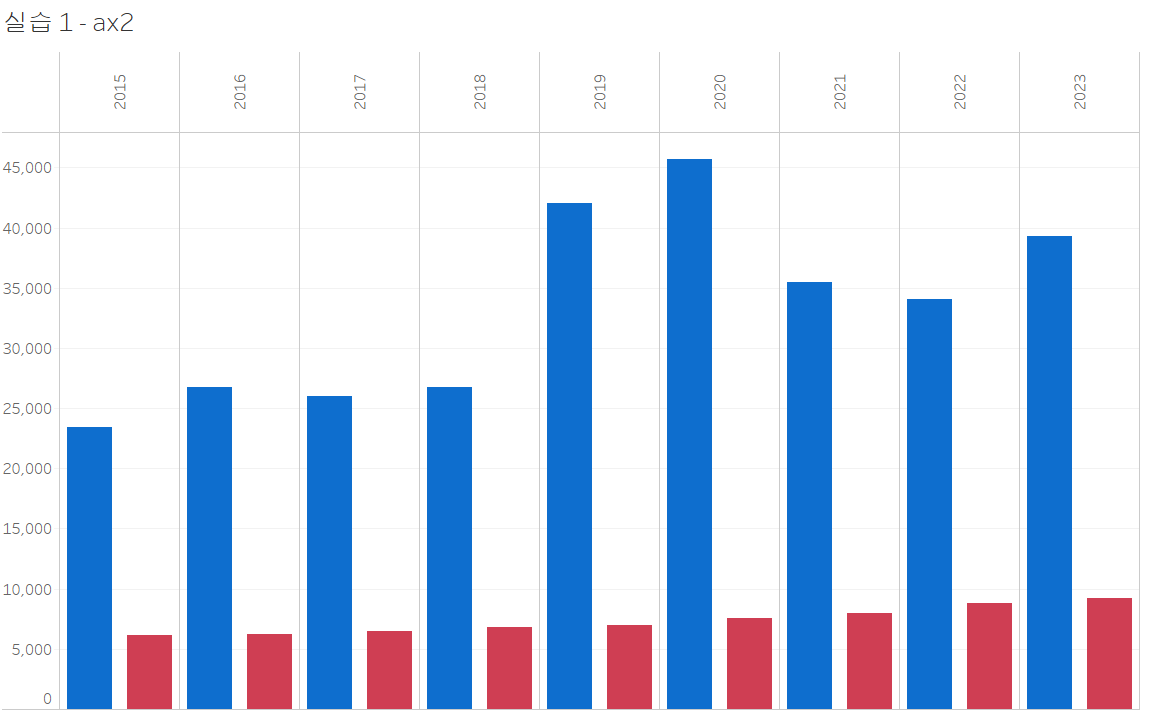
두번째 axis 그림은 매우 간단합니다. 첫 번째 axis 그림에서 단순히 표현 방식만 변경한 것이죠.
워크시트를 복제한 후 표현 방식만 빨간색 상자로 변경해 주면 끝입니다.
굉장히 비슷해졌네요. 디테일만 좀 잡아주면 될 것 같습니다.
이렇게 만든 두 워크시트를 대시보드로 옮겨서 하나의 그림에 그려보겠습니다.
- 새 대시보드 만들기 - 만든 두 워크시트를 위아래로 드래그해서 옮겨주기
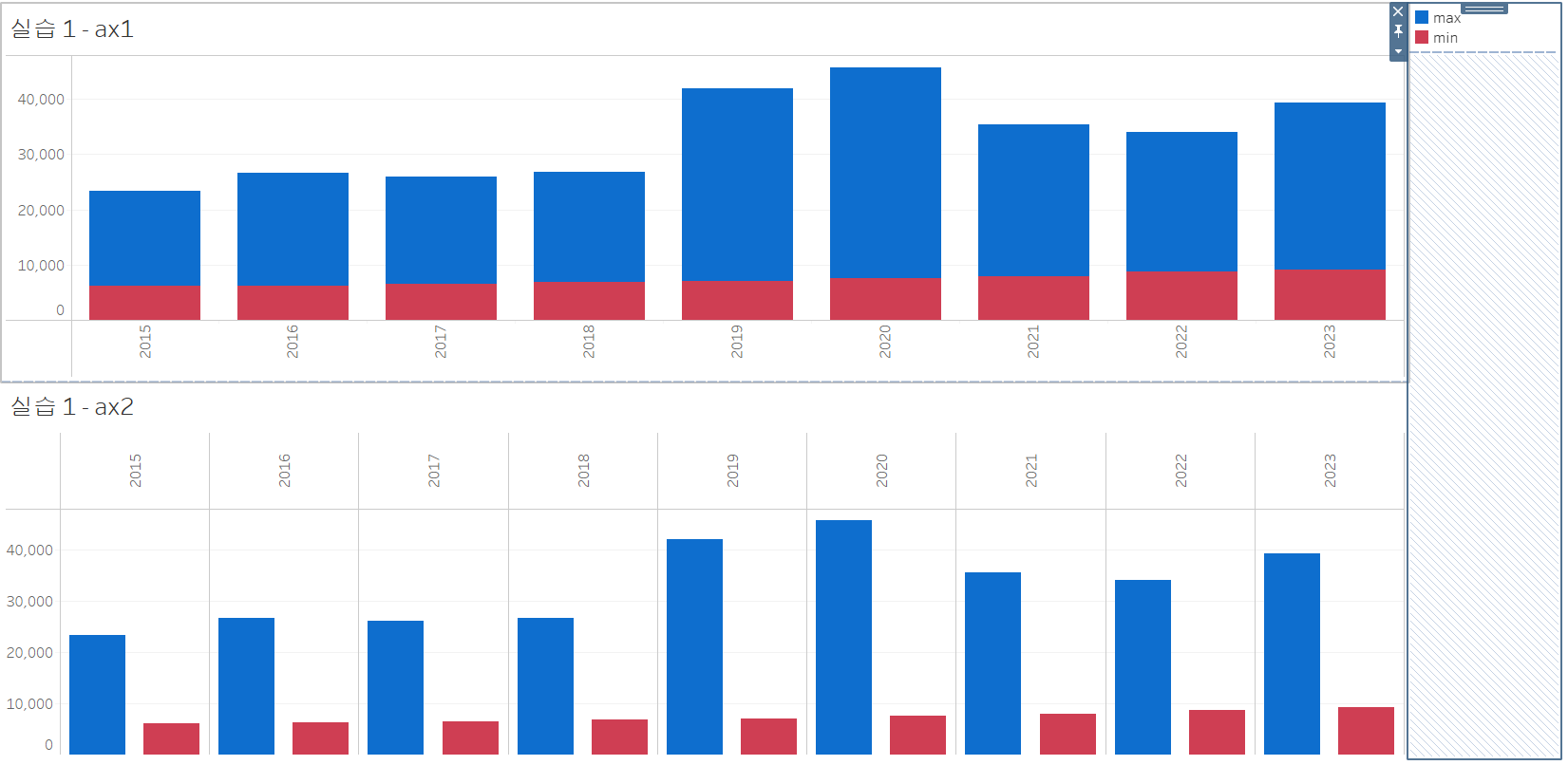
디테일만 좀 잡아주면, 파이썬 결과와 완전히 동일해질 것 같습니다.
텍스트를 추가하여 머리글을 만들어주고, 범례를 부동으로 바꾸어서 옮겨주었습니다.
이렇게 실습 1을 마치겠습니다.
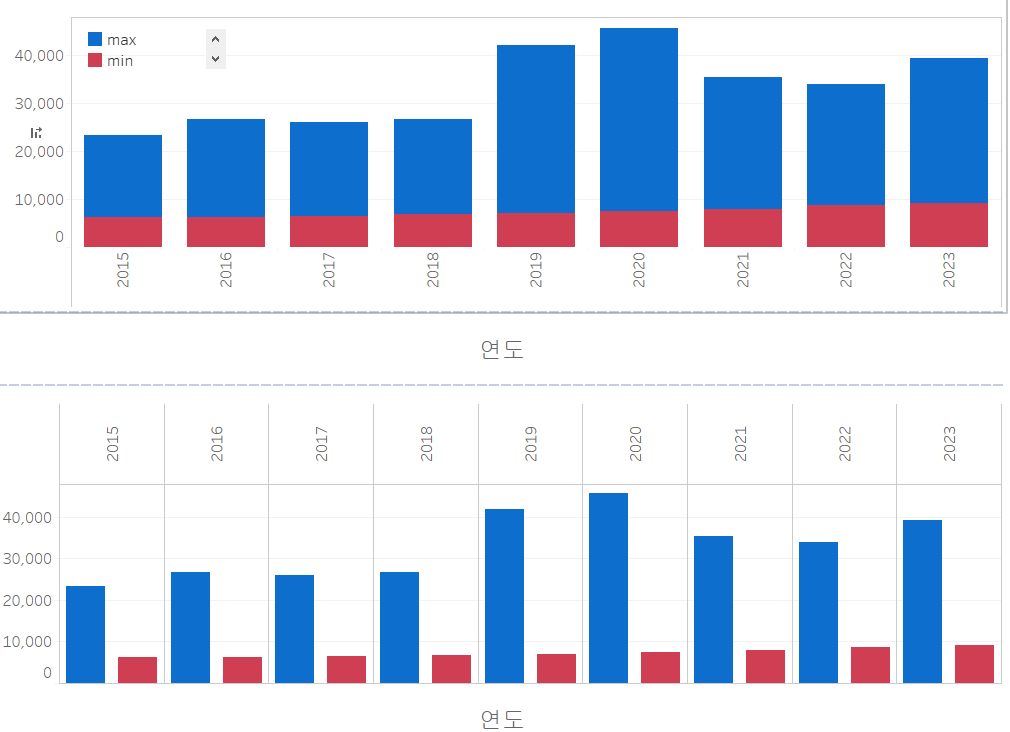
실습 2
- 지역별 평당 분양가격의 최솟값을 구하시오 (mn)
- 지역별 평당 분양가격의 최댓값을 구하시오 (mx)
- mn, mx를 이용하여 ax1, ax2에 아래와 같이 그림을 그리시오
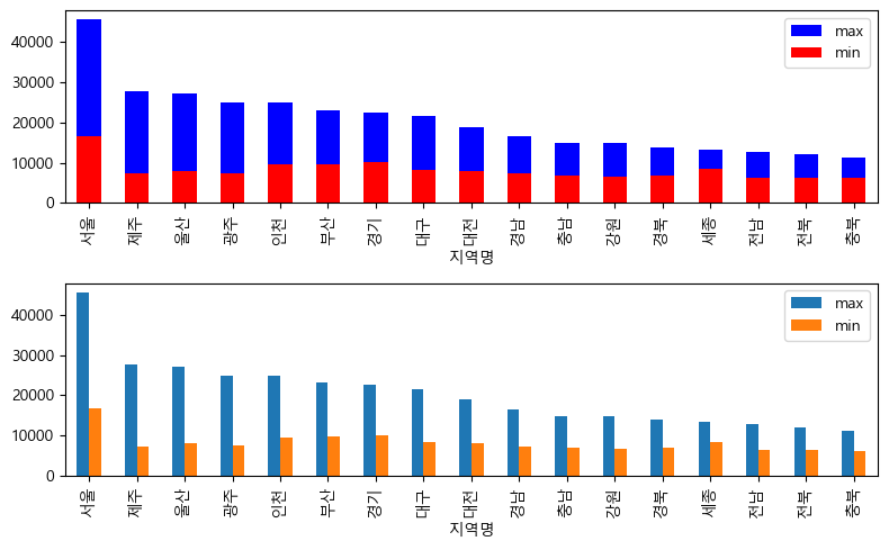
실습 2번은 단순히 실습 1번의 결과를 연도별 → 지역별로 바꾼 것 밖에 없기 때문에 매우 간단합니다.
실습 1번에서 만들었던 워크시트를 복제한 후에 열 선반에 "연도" 필드를 "지역명" 필드로 바꿔줍시다.
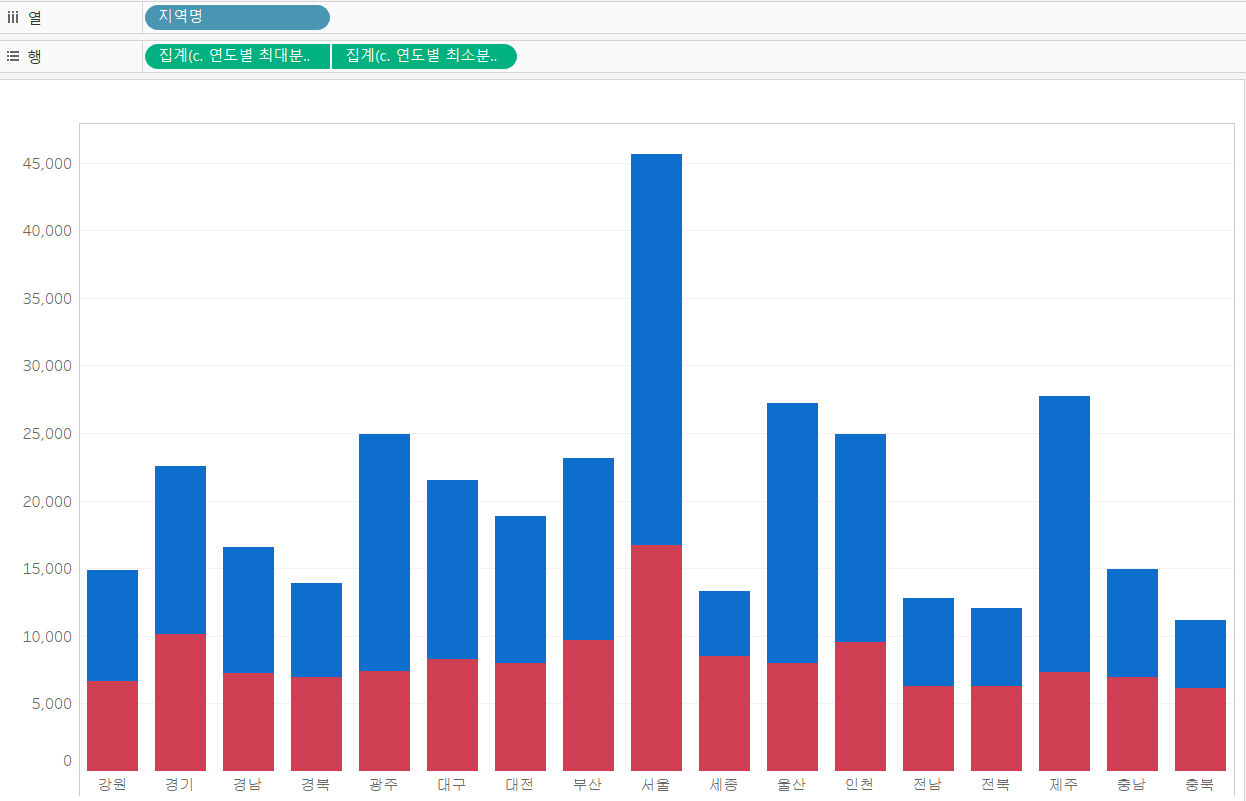
위 결과에서 파이썬과 같은 결과를 만들기 위해 내림차순 정렬해 줍시다.
- 빨간색 동그라미 클릭
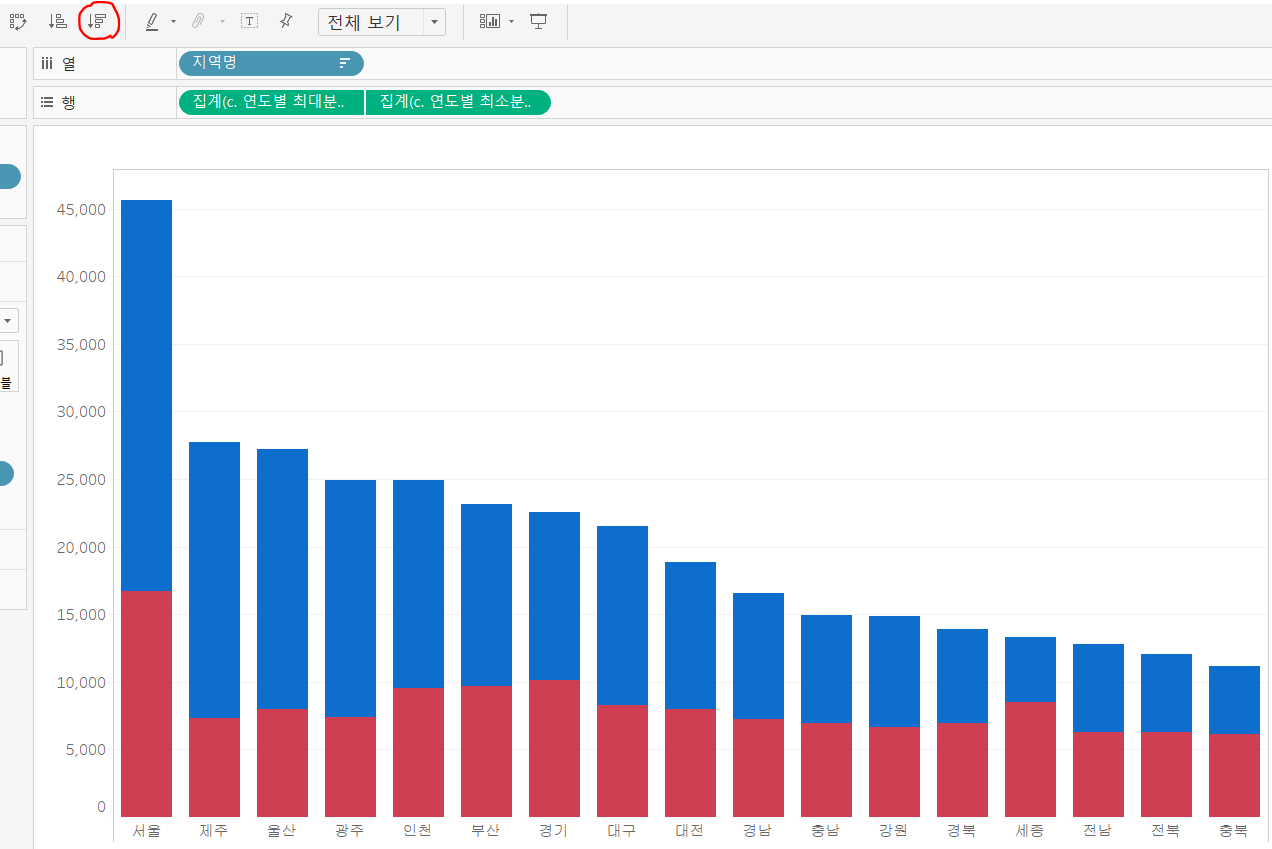
두 번째 axis 그림도 그려보죠. 마찬가지로 실습 1번에서 만들었던 두 번째 워크시트를 복제한 후 열 선반에 "연도" 필드를 "지역명" 필드로 변경합시다.
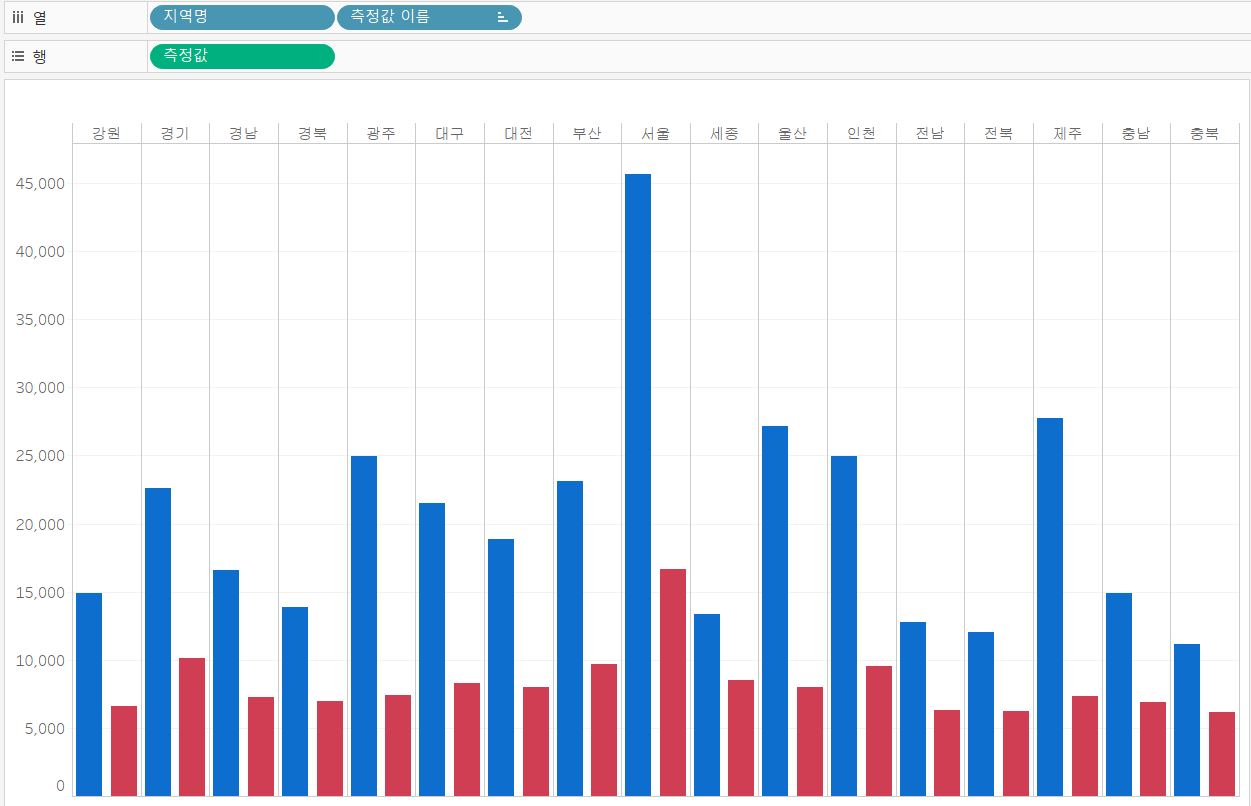
이번에는 첫 번째 axis 그림과 달리 내림차순 정렬을 하면, 필드 별로 적용되기 때문에 같은 지역 내의 막대그래프가 정렬됩니다. 따라서, 지역명 필드 자체에 정렬 순서를 지정해줘야 합니다. 우리는 연도별 최대분양가를 기준으로 정렬해 줄 것이기 때문에, 연도별 최대분양가 필드를 기준으로 정렬해 줍니다.
- 열 선반의 지역명 필드 선택 - 마우스 오른쪽 클릭 - 정렬 - 정렬 기준을 필드로 선택 - 내림차순
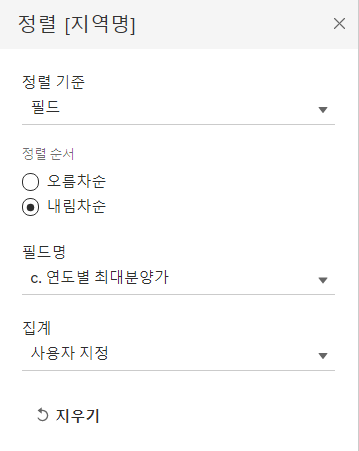
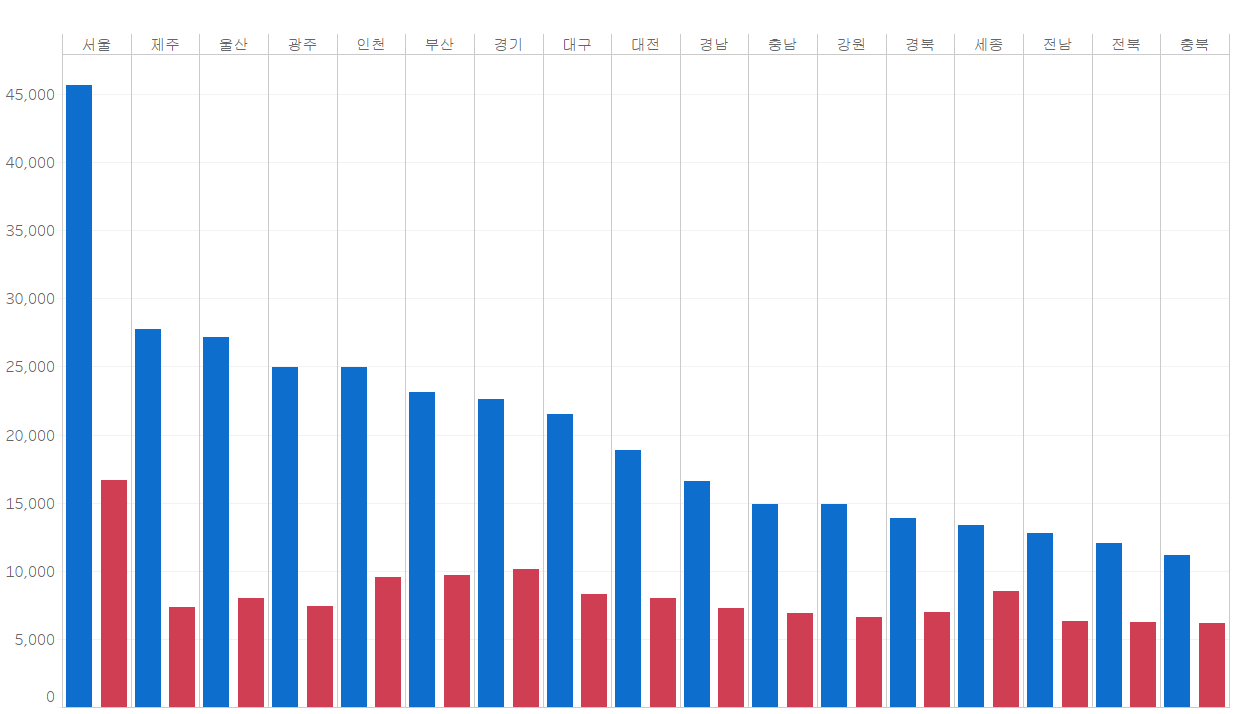
이렇게 두 번째 axis 그림까지 완성했으니 대시보드를 이용하여 하나의 그림으로 표현해 줍니다. 실습 1번과 동일하게 진행하면, 아래와 같은 그림이 나옵니다.
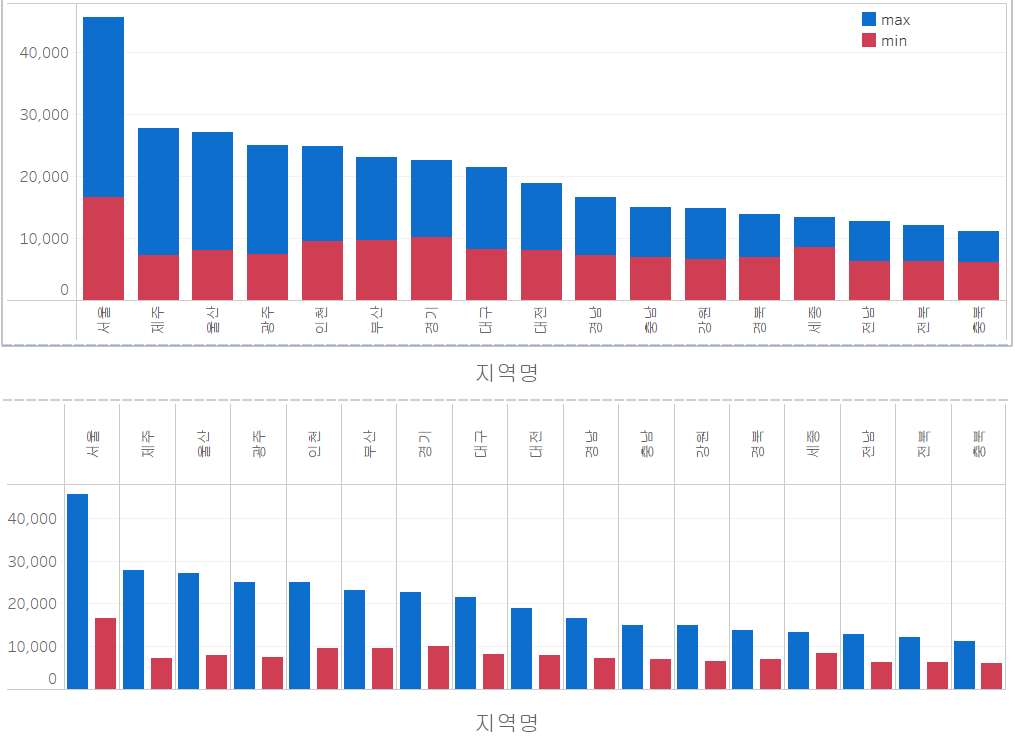
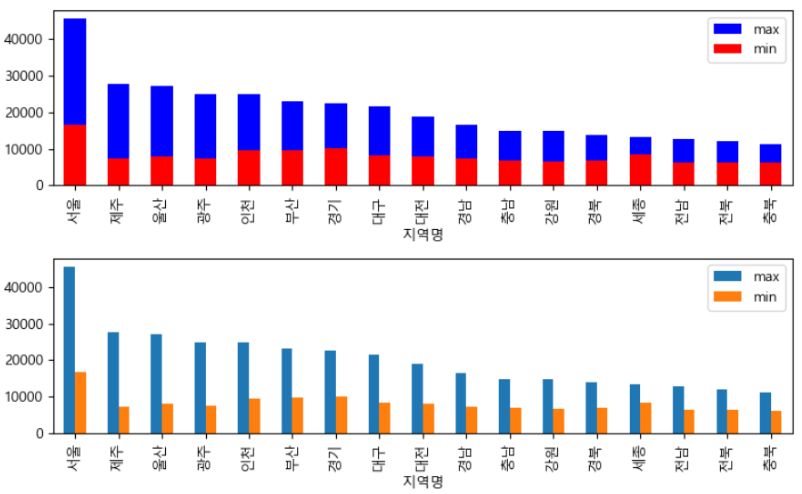
실습 3
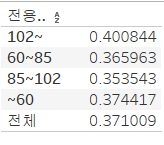
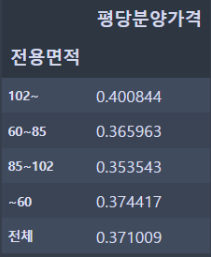
- 전용면적별로 평당 분양가격의 평균을 구하고, 전용면적별로 그 평균보다 높은 값들의 비율을 구하시오
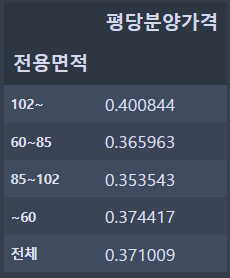
이번에는 데이터프레임처럼 표로 값을 채워줘야 합니다. 먼저, 전용면적별 평당 분양가격의 평균 필드를 만들어준 후에, 그 값보다 높은 값의 비율을 구해보겠습니다.
- 새로운 필드 만들기 - 이름 설정 - 조건 입력
이번에는, LOD라는 식을 사용해 보겠습니다. LOD는 태블로 공식 홈페이지에서 "세부 수준식"이라고도 이야기를 하는데요, 전체적인 값이 아닌 특정 필드에 대한 값을 구하고 싶을 때에 사용합니다. 예를 들어, 평당 분양가격의 평균을 구하고 싶을 때에 모든 평당 분양가격의 평균을 구한다면, 그저 스칼라값 하나가 나오겠지만, 세부 수준을 "전용면적"으로 정한다면, 전용면적별 평당분양가격의 평균이 나오게 되는 것이죠. 식을 만드는 방법은 매우 간단합니다.
- {Fixed [세부 수준] : 계산식}
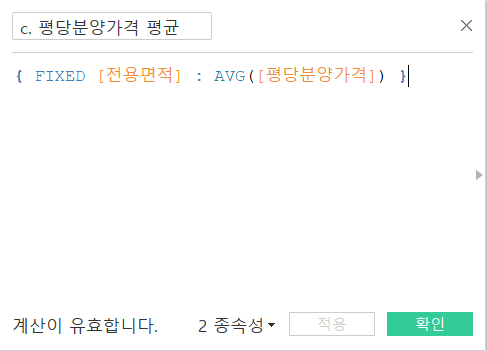
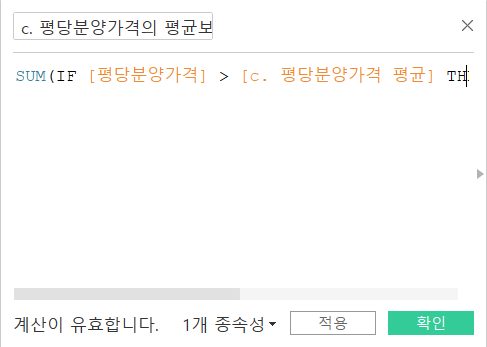
이렇게 하면, 전용면적별 평당분양가격의평당 분양가격의 평균이 구해지고, 이제는 전용면적별 평당 분양가격의 평균보다 높은 평당분양가격의 비율을 구해보겠습니다. 간단히 생각해보면, (해당 전용면적의 평당분양가격의 평균보다 높은 평당분양가격의 개수) / (해당 전용면적의 평당분양가격 개수)로 구할 수 있겠네요. 이를 식으로 표현한다면, 아래와 같습니다.
- SUM(IF [평당 분양가격] > [c. 평당 분양가격 평균] THEN 1 ELSE 0 END) / COUNT([평당 분양가격])
IF문을 이용하여 평당 분양가격이 평균보다 크다면 1을 반환하고, 아니면 0을 반환하도록 합니다. 그리고 SUM을 해주면, 조건에 해당하는 평당 분양가격의 개수가 세어지겠죠. 그리고, 평당분양가격 전체의 개수로 나누어주면 조건에 해당하는 비율을 계산할 수 있습니다.
이제, 측정값을 만들었으니 표를 만들어보죠. 행 선반에 "전용면적" 필드를 넣어주고, 만든 측정값을 더블 클릭해 줍니다.
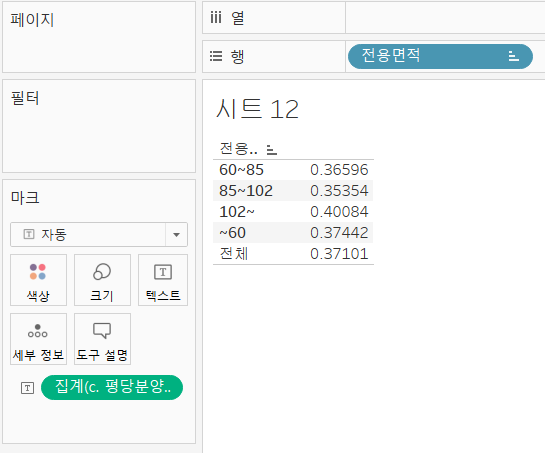
값은 맞는 것 같은데, 전용면적의 정렬 순서가 다르네요. 맞게 정렬해 줍시다.
- 행 선반에 전용면적 선택 - 정렬 - 정렬 기준을 사전순으로 설정 - 오름차순
실습 4
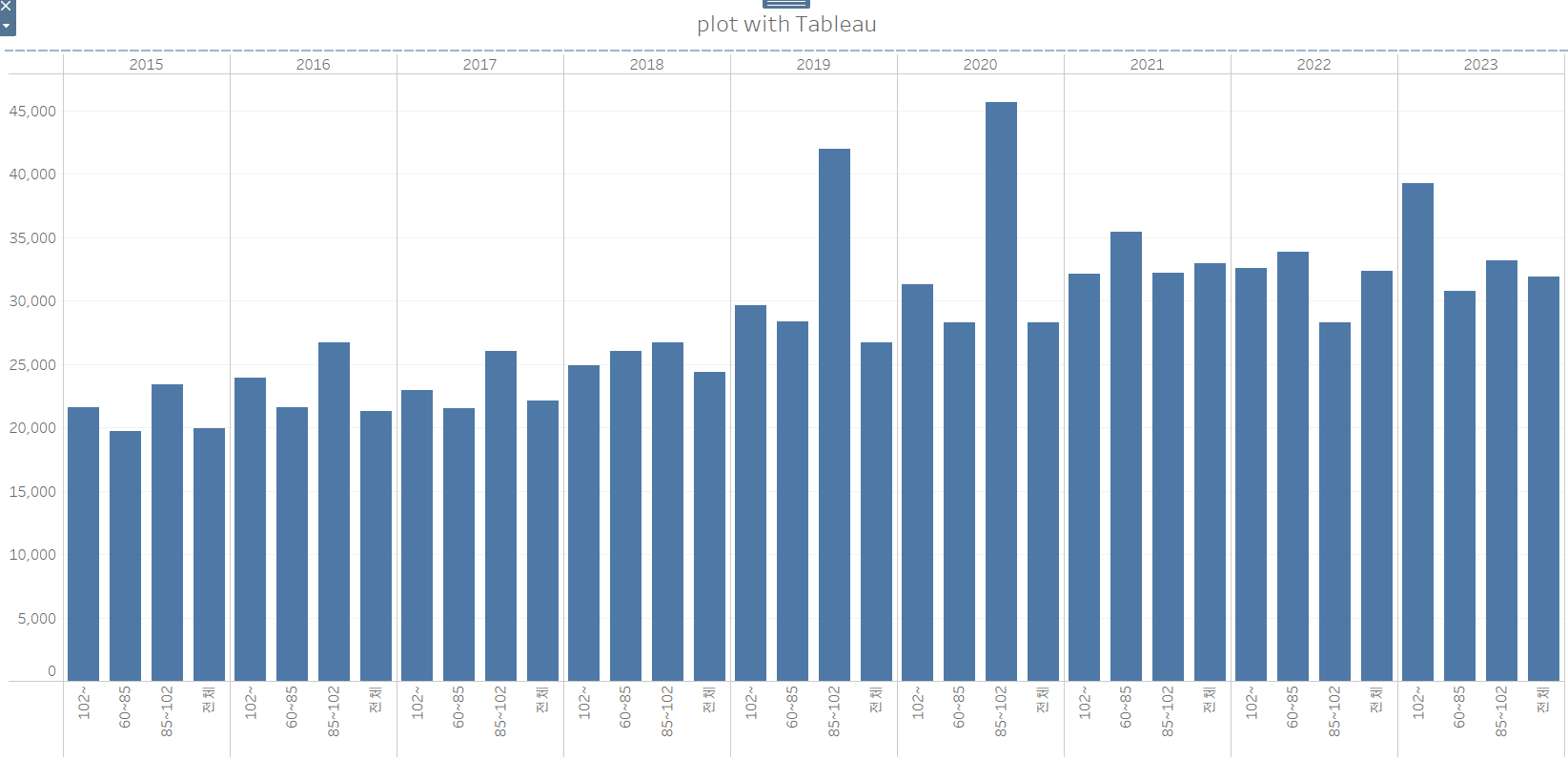
- 연도별, 전용면적별 최댓값을 아래와 같이 시각화하시오

연도별, 전용면적별 평당 분양가격의 최댓값을 구할 수 있어야겠네요.
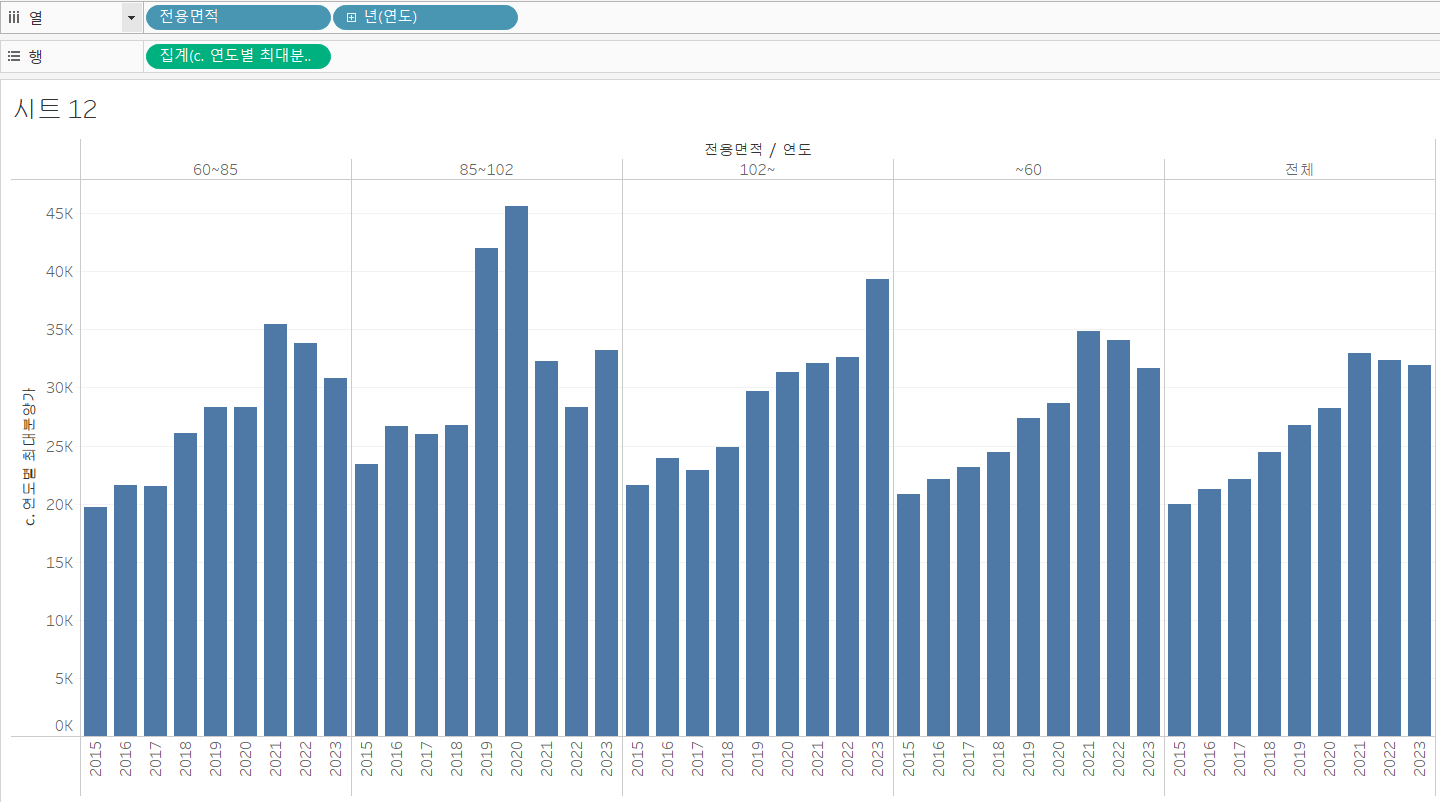
이전에, [c. 연도별 최대분양가] 필드를 만들 때에 식이 연도에만 국한된 것은 아니었습니다. 그저 최대분양가격을 구하는 것이었죠. 따라서, 열 선반에 "연도" 필드와 "전용 면적" 필드를 올려주고, 행 선반에 [c. 연도별 최대분양가] 필드를 올려주면, 연도별 전용면적별 최대분양가가 계산될 것입니다.
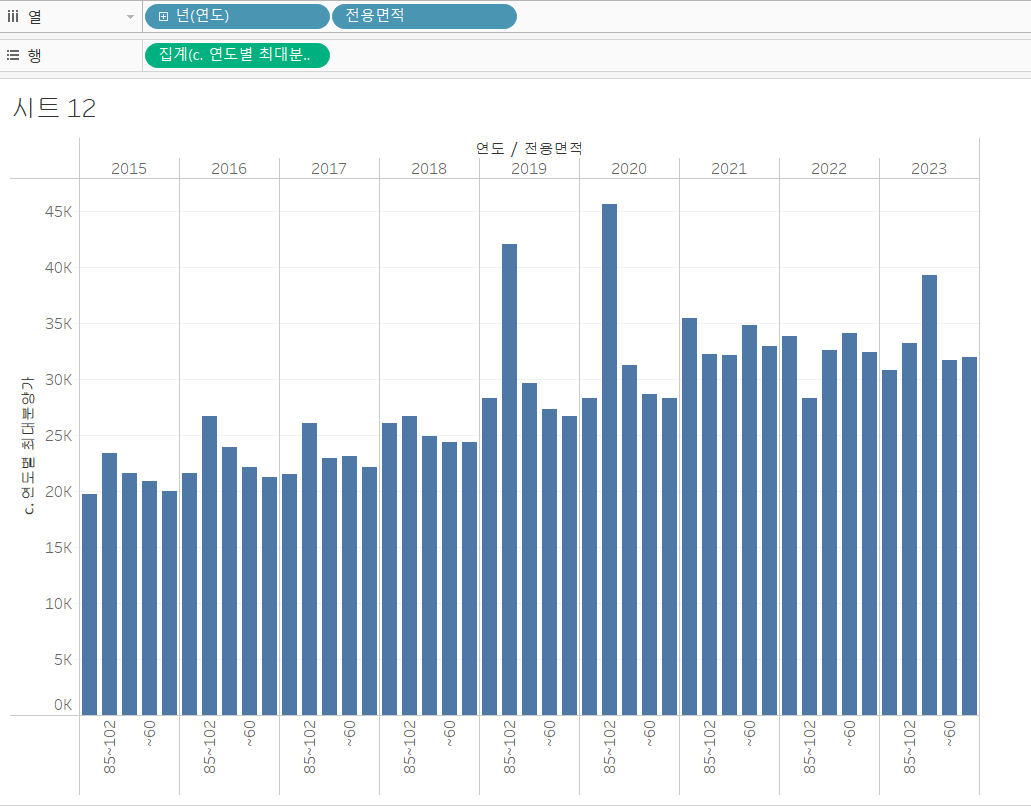
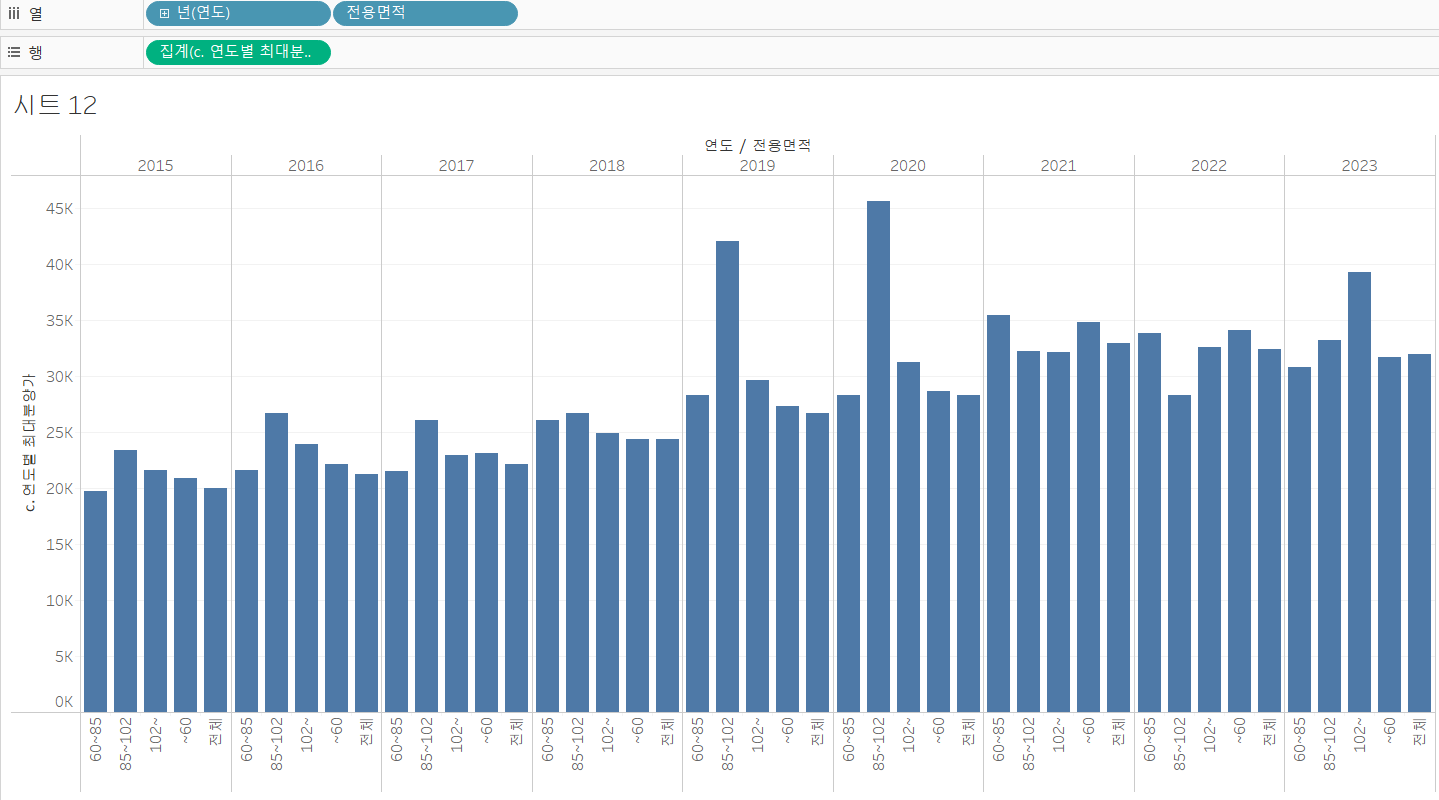
이미 그림은 어느 정도 그려졌습니다. 다만, 전용면적의 순서가 다르네요. 파이썬의 결과에 맞게 정렬해 줍시다.
- 열 선반에 전용면적 선택 - 마우스 오른쪽 클릭 - 정렬 - 정렬 기준을 사전순으로 선택 - 오름차순
그리고, 머리글 같은 디테일한 부분만 좀 잡아주면, 아래와 같이 비슷한 결과가 나오게 됩니다.

실습 5
- 연도별, 전용면적별 최댓값을 아래와 같이 시각화하시오
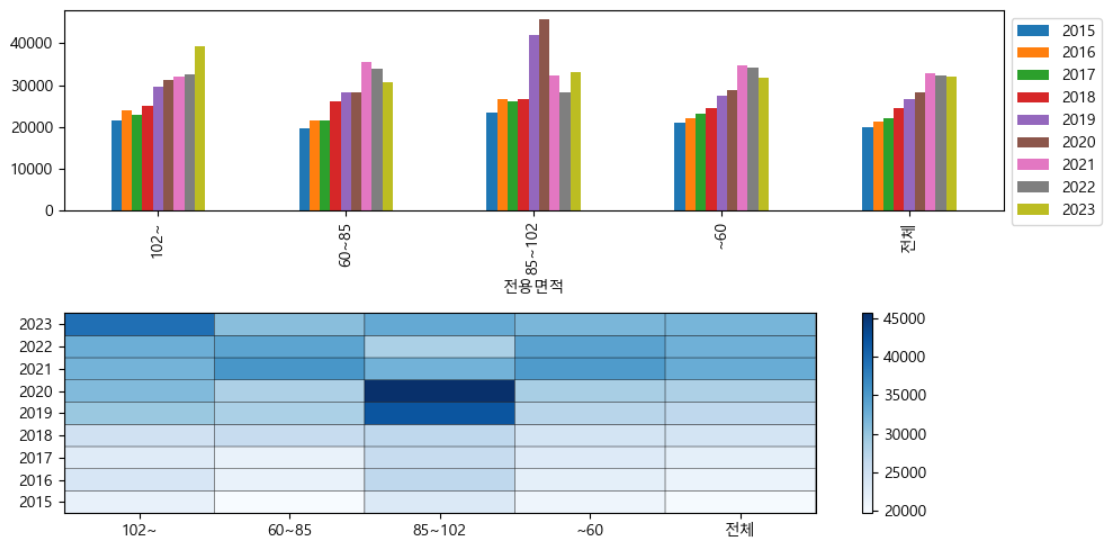
이번에는 같은 값을 구하는데, 순서만 다르게 했을 뿐이네요. 열 선반에 순서를 바꾸어주면 됩니다.
위 결과에서 디테일한 부분을 잡아줍시다. 전용면적의 순서를 다시 정렬해 주고, 연도별로 다른 색상을 입혀줘야겠네요. 필드 순서 정렬은 이전에 많이 다뤘으니 생략하겠습니다. 연도별 다른 색상을 설정하는 것은 간단합니다.
- 마크 - 색상 - 연도 입력
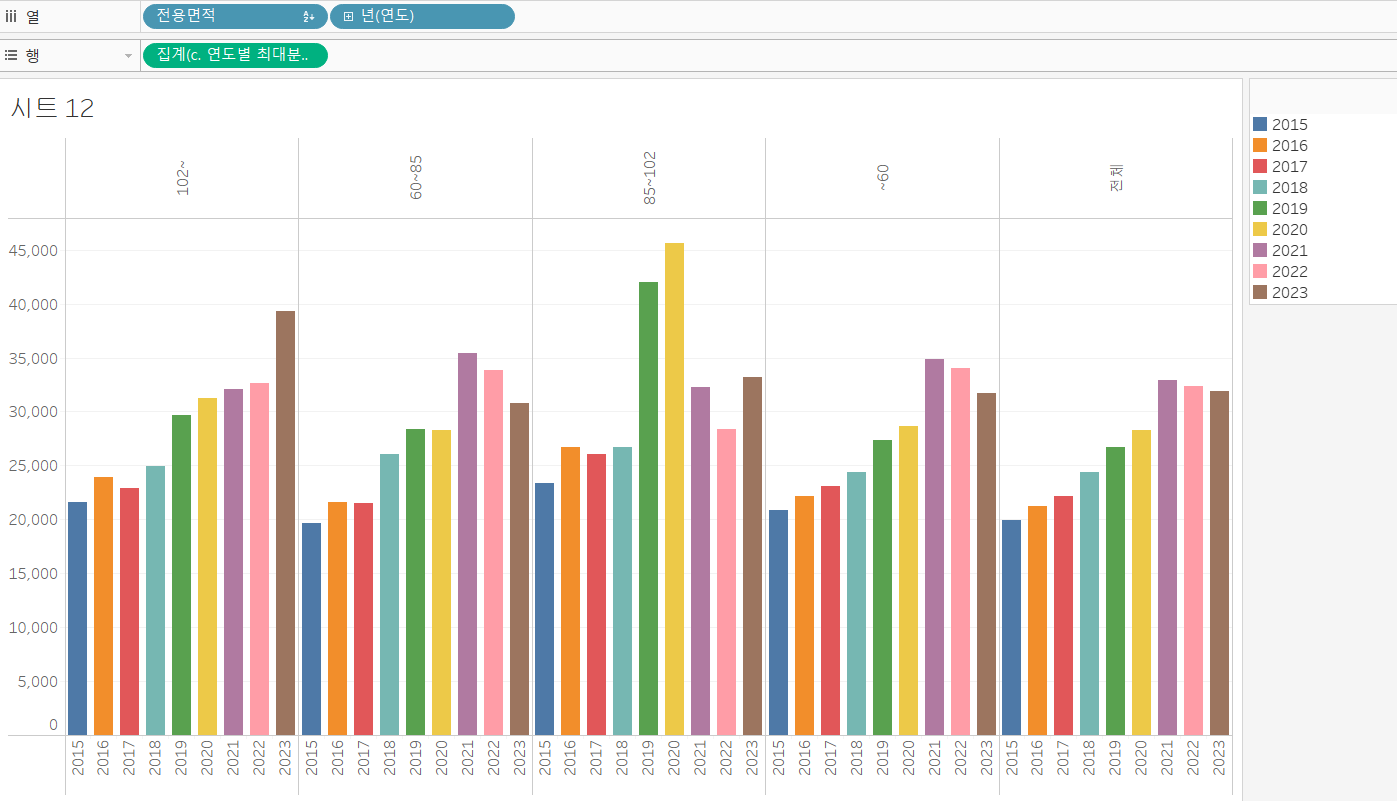
첫 번째 axis 그림은 완성되었습니다.
두 번째 axis 그림은 파이썬에서 pcolor라는 메서드를 사용한 그림인데, 값이 커질수록 색상이 진해집니다. 태블로에서는 pcolor는 없지만 유사한 표현방식은 존재해서, 그걸로 대체해 그려보겠습니다. 먼저 들어갈 값은 동일하기 때문에 지금 작업한 워크 시트를 복제해서 사용해 줍시다.
- 표현 방식 클릭 - 빨간색 동그라미 클릭
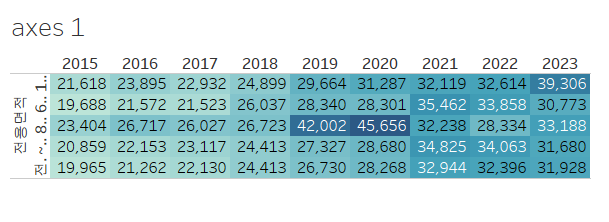
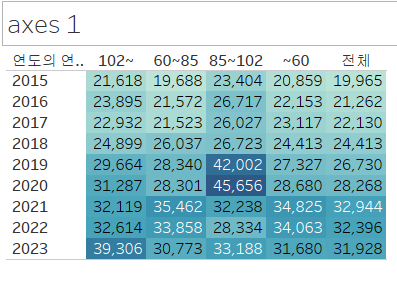
우리가 그리고자 했던 그림과 정확히 행과 열만 뒤집힌 상태네요. 행과 열 선반에 있는 필드를 바꿔줍시다. 그리고, 파이썬 결과와 최대한 비슷하게 바꾸기 위해서 색상과 연도의 순서를 정렬해 줄게요.
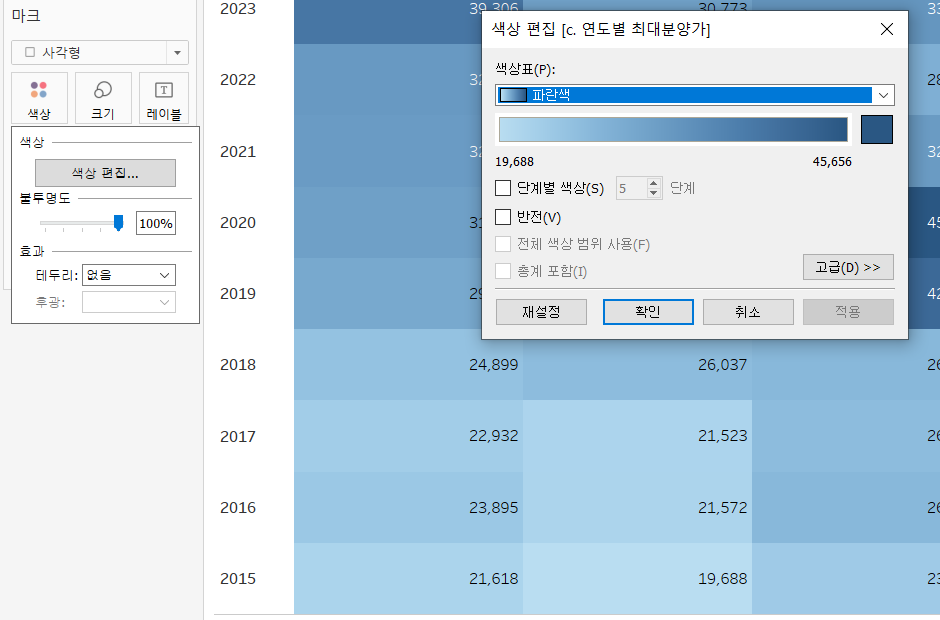
테두리만 추가해 주면, 완벽히 같은 그림이 될 것 같습니다.
- 패널 선택 - 마우스 오른쪽 클릭 - 서식 - 테두리 서식 - 기본값 - 셀을 실선으로 설정 - 색상을 블랙으로 변경
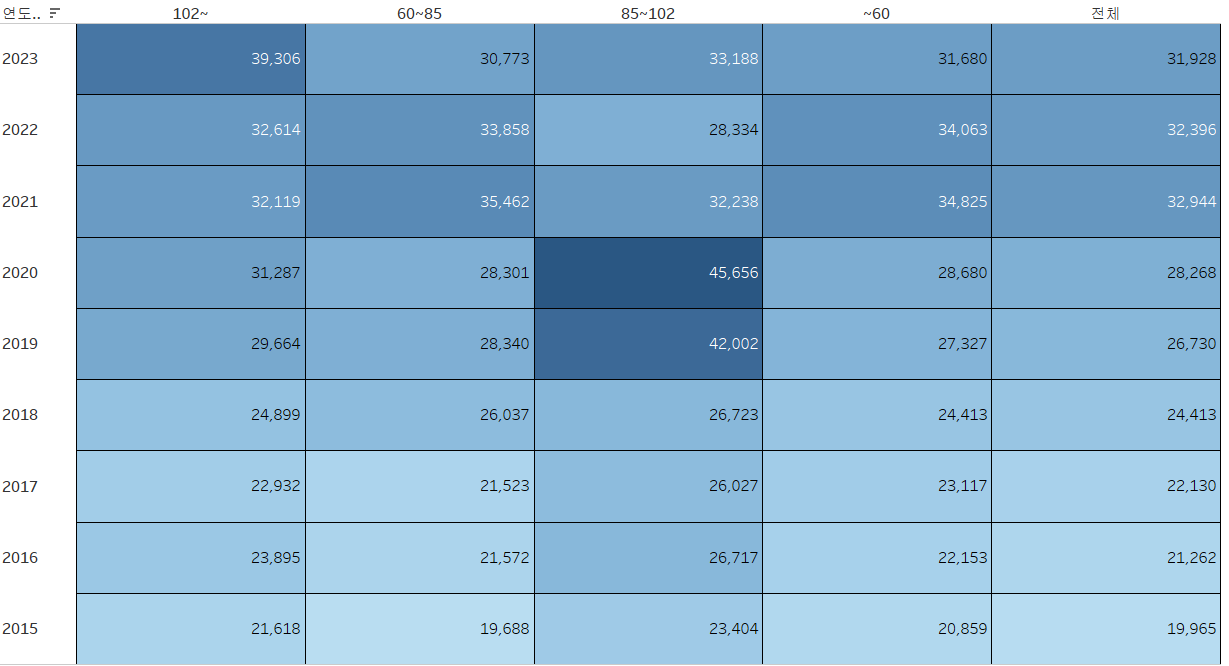
이제 대시보드에 ax1과 ax2를 합쳐서 나타내어 마무리하겠습니다.
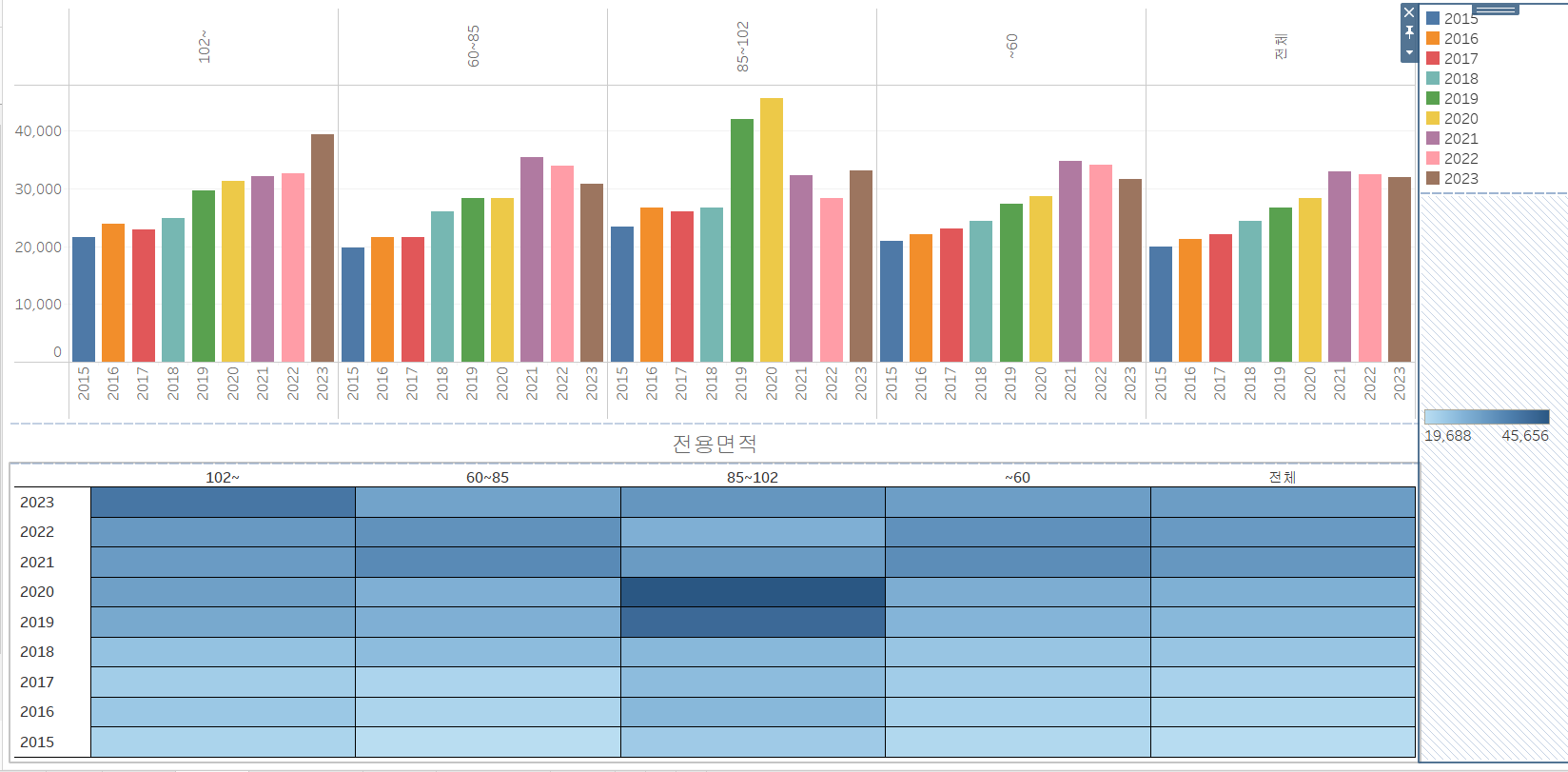
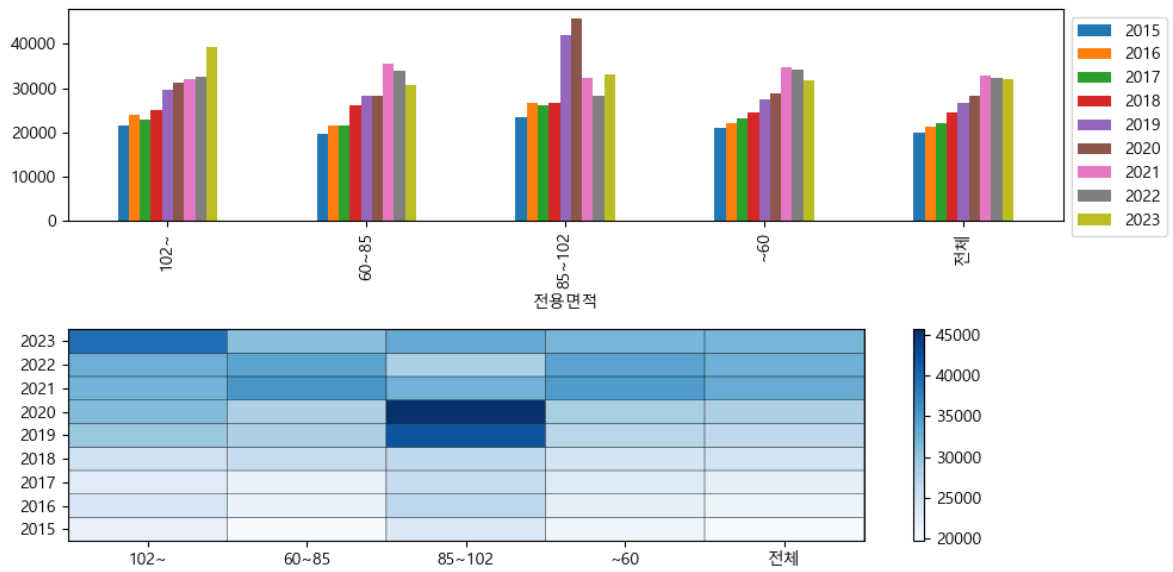
실습 6
- 연도별, 지역별 평균값을 아래와 같이 시각화하시오.
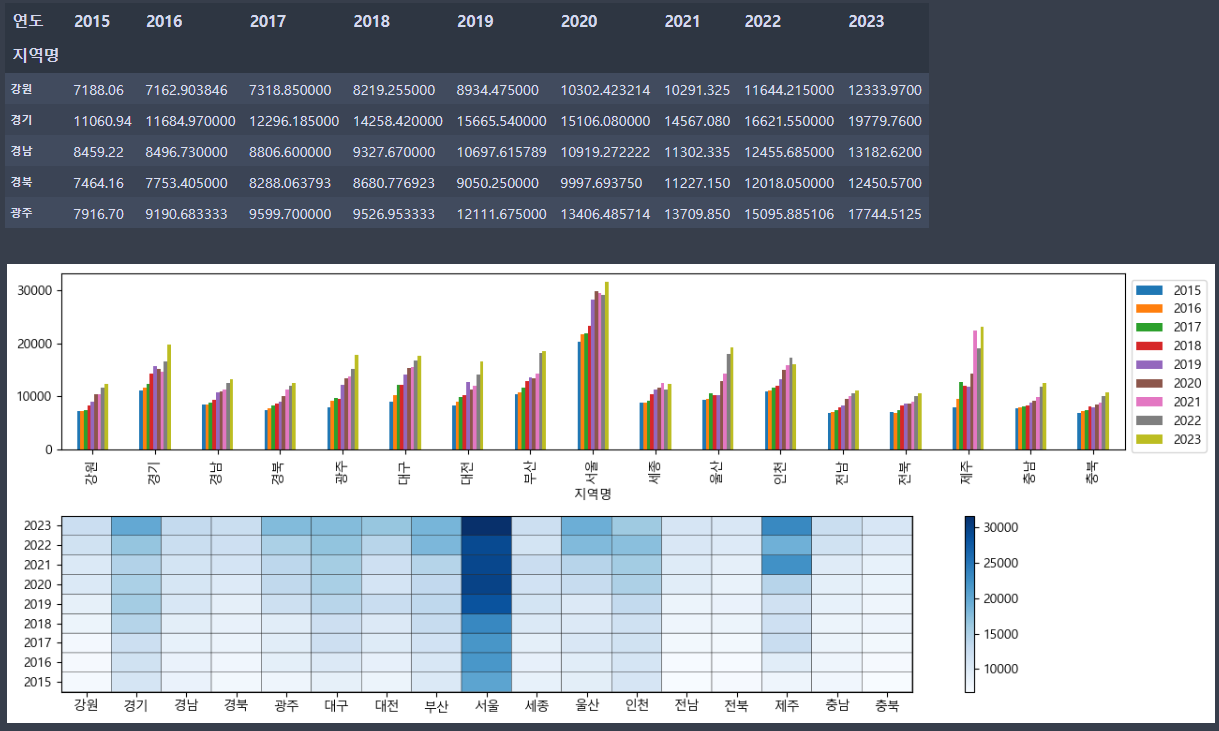
실습 6번은 지금까지의 실습 문제들을 섞어서 모아둔 것 같습니다. 풀이를 보기 전에, 어떻게 풀면 될지 먼저 생각해 보시는 시간을 갖고, 보시면 더 이해에 도움이 될 것입니다.
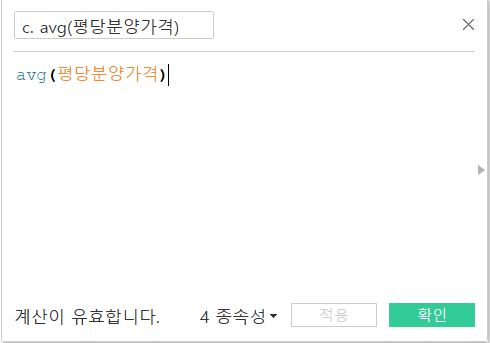
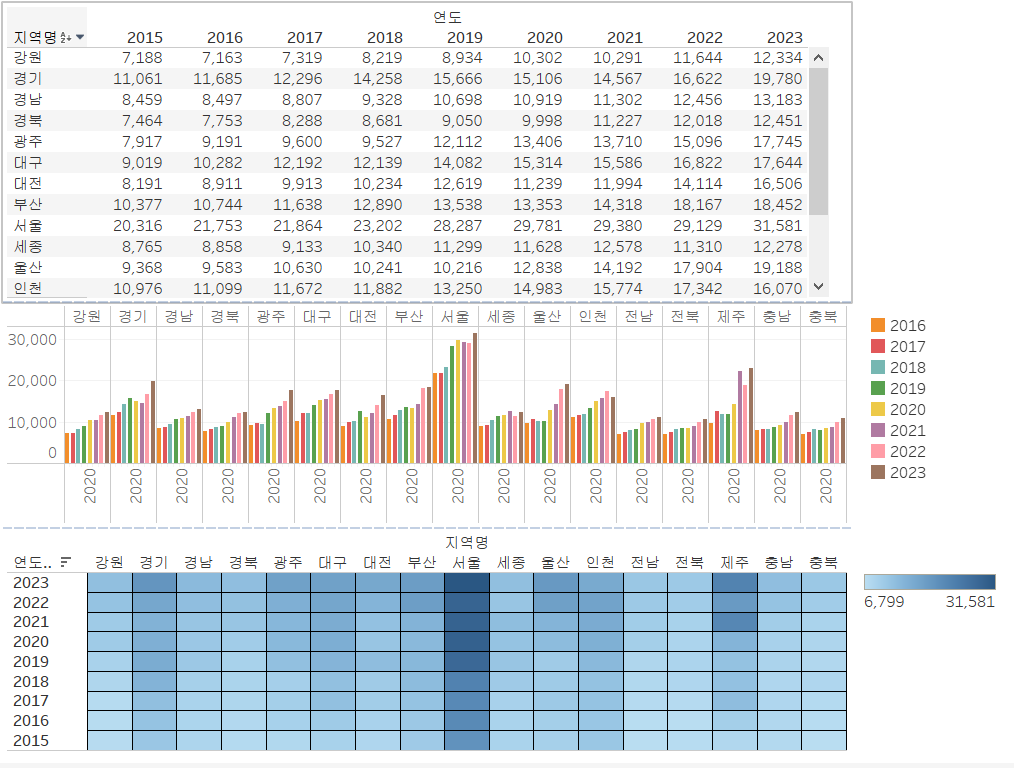
먼저, 평균 평당 분양가격 필드를 만들어주겠습니다. 그리고, 연도별 지역별 평균값을 살펴보죠.
- 새로운 필드 만들기 - 계산식 입력
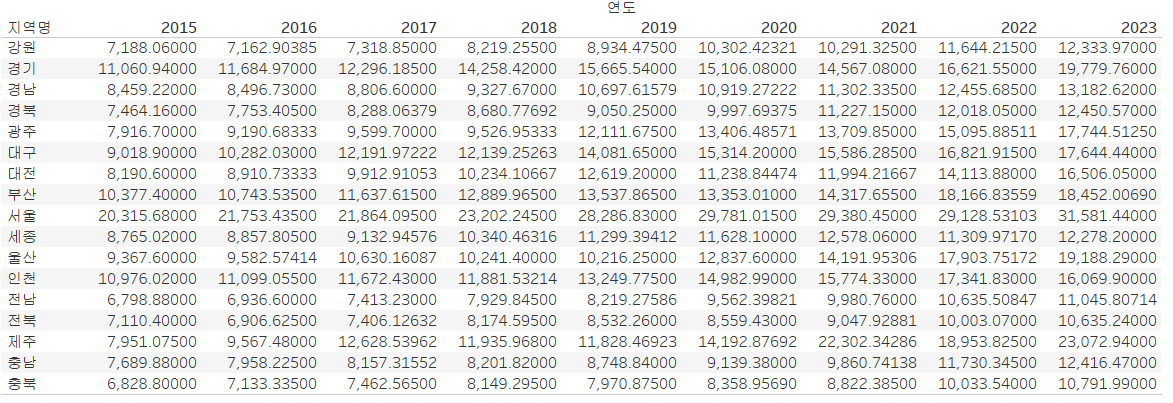
새로 만든 필드를 이용해서 값을 나타낼 건데, 결과를 보니 행에 지역명이 있고, 열에 연도가 있네요.
그대로 행 선반에 "지역명" 필드를 넣고, 열 선반에 "연도" 필드를 넣습니다.
그리고 측정값으로는 만든 필드를 넣어줄게요. 파이썬 결과는 head 함수를 이용해서 처음 5가지 지역의 결과만 보여주었는데, 저희는 모든 지역을 표시하겠습니다.
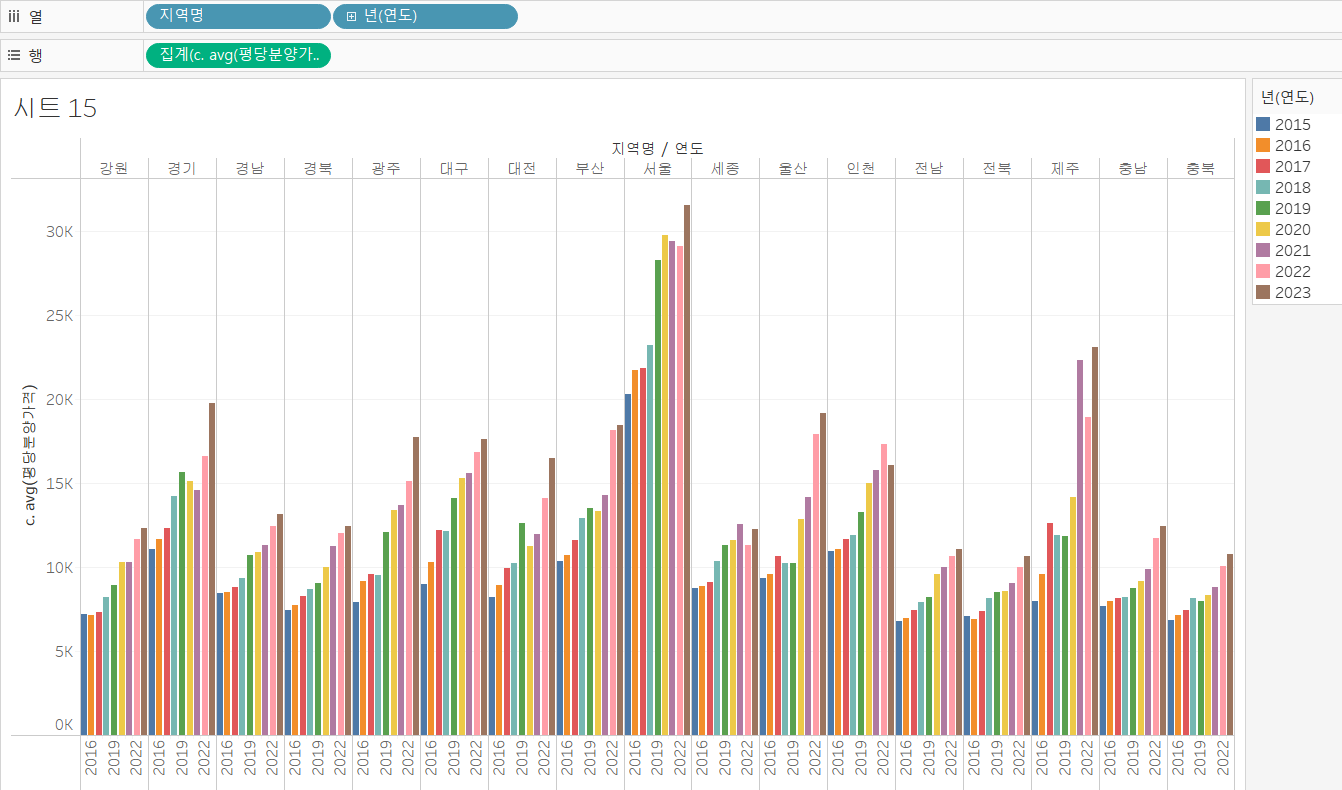
이제 두 번째 axis 그림을 그려보죠. 실습 5번의 첫 번째 axis 그림에서 필드만 바뀐 것에 불과합니다.
열 선반에 "지역명", "연도" 필드를 넣고, 행 선반에 평균 분양가격 필드를 넣어주고, 표현 방식을 막대로 변경하죠.
세 번째 axis 그림도 실습 5번의 두 번째 axis 그림과 동일합니다.
행 선반에 "연도" 필드를 넣고, 열 선반에 "지역명" 필드를 넣은 후, 측정값으로 평균 분양가격 필드를 넣습니다. 마지막으로, 표현 방식을 하이라이트 테이블로 변경해 주면 완성입니다.
마지막으로, 디테일을 좀 잡아주고 대시보드에 합쳐주면 완성입니다.

Insight
: 태블로를 이용한 시각화가 파이썬보다 더 쉬울 줄 알았다. 하지만, 아직은 파이썬을 사용했던 시간이 월등히 길어서 그런지 쉽지만은 않았다. 또한, 결과도 90%는 유사하지만 완벽히 똑같이 만들어내진 못했다. 아직 어떠한 표현 방식을 사용해야 내가 원하는 그림이 될지, 여기서 어떤 필드를 만들고 그걸 이용해서 필터링 등의 작업을 해야하는지를 명확히 구분하지 못하고 있는 것 같다. 강의를 반복해서 들으며 숙달하는 시간을 가질 필요성을 느꼈다.
마치며..
오늘은 이렇게 태블로를 수업 내용을 이용하여 파이썬의 아웃풋을 태블로로 구현하는 연습을 해봤습니다. 총 6문제를 풀었는데, 생각보다 길어졌네요. 파이썬은 익숙해서 시각화를 수월하게 수행했는데, 태블로는 아직 숙달이 필요한 것 같습니다. 앞으로도 계속 실습 문제를 가져와 풀 계획인데, 여러분들에게도 도움이 되었으면 좋겠습니다.
오늘도 읽어주셔서 감사합니다 :)

'스터디' 카테고리의 다른 글
| [Data Analysis] 데이터 시각화를 위한 태블로 - 4주차 (0) | 2024.07.27 |
|---|---|
| [Data Analysis] 데이터 시각화를 위한 태블로 - 2주차 (1) | 2024.07.11 |
| [Data Analysis] 데이터 시각화를 위한 태블로 - 1주차 (0) | 2024.06.30 |


