
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 데이터 증강
- sparse coding
- 태블로 실습
- data analysis
- 장학프로그램
- super resolution
- SRCNN
- Data Augmentation
- VGG16
- 개 vs 고양이
- 태블로
- tcga
- Semantic Segmentation
- Attention
- 딥러닝
- 데이터 분석
- 논문리뷰
- k-fold cross validation
- 데이터 시각화
- 논문 리뷰
- Tableau
- ResNet
- Deep Learning
- Computer Vision
- cnn
- 데이터과학
- kt희망나눔재단
- 머신러닝
- 파이썬 구현
- kt디지털인재
- Today
- Total
기억의 기록(나의 기기)
[Computer Vision] Dice, Jaccard Index 정의 및 차이점 본문
[Computer Vision] Dice, Jaccard Index 정의 및 차이점
안녕하세요, 데이터과학 전공하고 있는 황경하입니다.
오늘은 이전에 Semantic Segmentation 논문 리뷰에서 나왔던 평가 지표인 Dice, Jaccard Index에 대해 이야기해 보겠습니다. 이런 분할 태스크에 정말 많이 사용되는 지표임과 동시에 두 개념이 매우 유사하기에 차이점을 확실히 정리해 두는 것이 필요할 것 같아 블로깅하게 되었습니다.
# 어디에 사용하는데?
우선, Metrics를 공부하기 이전에 어디에 사용되는지를 알아야 적용할 수 있겠죠. Dice, Jaccard Index는 Object Detection, Semantic Segmentation, .. 등 이미지 내에서 특정 영역의 위치를 예측 혹은 분리하는 작업에 사용될 수 있습니다. 예를 들어, 아래 그림과 같이 대장, 소장, 위장의 위치를 분할하는 태스크에 적용할 수 있습니다.

# Dice
Dice Score는 모델의 예측 영역과 GT가 얼마나 겹치는 지를 나타내는 지표입니다. 수식으로 나타낸다면 아래와 같습니다.
식을 보면, F1-Score와 유사하여 오른쪽에 같이 배치하였는데요. Dice 좌표와 F1-Score 모두 조화평균을 이용하며, 0과 1사이의 값을 갖습니다. 이는 Jaccard Index와와 많이 헷갈릴 수 있는데, 아래에 보며 같이 이야기해 봅시다.
# Jaccard Index
IoU는 Jaccard Index와 같은 개념입니다. 우리가 하고자 하는 태스크가 실제 영역을 예측하는 것이죠. 이는 분리하는 태스크와 위치는 찾는 태스크 모두 동일합니다. 우선 위치를 모델이 예측해야 그때부터 분리를 하든, 그 위치의 타겟의 클래스를 예측하든 할 테니까요.
그렇다면, 위에서 TP, FP, FN, TN 등의 개념은 모델이 "여기에 있어!"라고 예측한 것을 P(Positive), "여기엔 없어!"라고 예측한 것을 N(Negative)라고 볼 수 있으며, 예측 영역이 실제로 타겟 영역이냐 아니냐를 통해 True와 False가 결정됩니다.
IoU를 보면, A를 예측 영역, B를 타겟영역이라고 가정해보겠습니다. 이는 예측 영역과 타겟 영역이 얼마나 겹치는 지의 비율로 볼 수 있습니다. 즉, IoU가 크다는 것은 타겟을 얼마나 잘 예측하였느냐로 볼 수 있는 것이죠. 따라서, 많은 Object Detection, Segmentation 영역에 사용하는 Metrics 이기도 합니다.
# 차이점
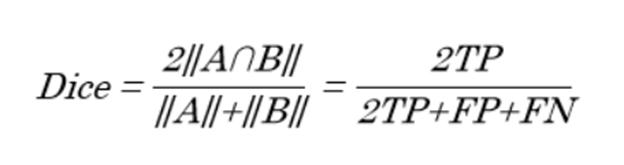
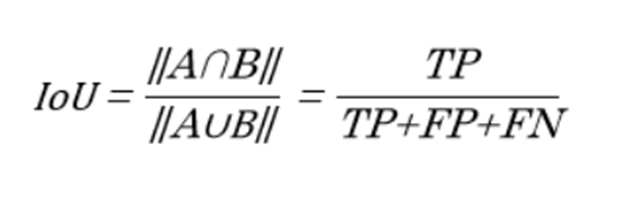
두 식을 나란히 놓고 보면, 차이점은 Dice에는 TP에 2를 곱해준다는 점입니다. 이는 TP를 다른 값보다 2배 더 중요하게 본다는 것이죠. 이 말이 무슨 뜻이냐면, 모델이 타겟 영역을 정확히 맞췄을 때에 더 많은 점수를 주겠다는 것입니다. Segmentation 태스크에서는 물체와 배경이 매우 밀접하게 붙어있기에 정확히 타겟과 배경을 분리하는 것이 쉽지 않은 일입니다. 그렇기에 틀릴 확률이 훨씬 더 높죠. 따라서, 맞춘 것에 더 많은 중점을 두는 것입니다.
예를 들어, 수능 수학에서도 어려운 문제 (킬러 문제)는 배점이 더 높은 것과 같습니다. 쉬운 문제를 두 개 틀려도 어려운 문제 하나를 맞추면 점수가 같죠. 이는 어려운 태스크를 해결한다면, 더 높은 점수를 주겠다는 말입니다.
마치며...
오늘은 이렇게 Dice와 Jaccard Index에 대해 정리해 보았습니다. 사실 공식들을 하나씩 뜯어보면, 되게 어려울 것 같지만 당연한 것일 수 있겠다는 생각도 듭니다. 그 얘기는 수학자들이 그만큼 공식을 잘 만들었고, 쉬우면서도 의미를 많이 압축했다는 뜻이겠죠. Metrics가 너무나 많습니다. 각 태스크마다 평가 지표가 달라서 헷갈리더라고요. 그래서 오늘은 조금 정리를 해봤습니다.
제 글이 여러분에게 조금이나마 도움이 되었으면 합니다. 읽어주셔서 감사합니다 :)

'딥러닝' 카테고리의 다른 글
| [Sparse Coding] 희소 코딩 기법에 대한 그림을 통한 쉬운 설명 (0) | 2024.07.12 |
|---|---|
| [Data Preprocessing] Duplicate Cleaner 소개 및 사용법 (1) | 2024.07.03 |
| [ResNet] 예제를 통한 설명 및 함수형 API 구현하기 (1) | 2024.06.25 |
| [VGG16] 예제를 통한 transfer learning, fine-tuning 설명 (0) | 2024.06.24 |
| [Data Augmentation] 예제를 통한 데이터 증강 효과 설명 (0) | 2024.06.24 |



