
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 태블로 실습
- 머신러닝
- 데이터 시각화
- 태블로
- object detection
- VGG
- 장학프로그램
- ResNet
- SRCNN
- 파이썬 구현
- Data Augmentation
- kt희망나눔재단
- cnn
- 딥러닝
- Semantic Segmentation
- 데이터 분석
- sparse coding
- 데이터과학
- kt디지털인재
- 데이터 증강
- 개 vs 고양이
- VGG16
- Tableau
- Deep Learning
- 논문 리뷰
- Computer Vision
- 논문리뷰
- k-fold cross validation
- super resolution
- data analysis
- Today
- Total
기억의 기록(나의 기기)
[Data Augmentation] 강아지, 고양이, MNIST 예시를 통한 설명 본문
Data Augmentation
안녕하세요, 데이터과학 공부하고 있는 황경하입니다.
오늘은 데이터 증강 기법을 이용한 강아지, 고양이 분류 문제를 다뤄보겠습니다.
코드: https://colab.research.google.com/drive/1lZdegtB7uyrTXlzVxLr8dXl38yC_1bYl?usp=sharing
[Data Augmentation] 강아지, 고양이, MNIST 예시를 통한 설명
Colab notebook
colab.research.google.com
서론
몇 년 전까지만 해도 강아지와 고양이를 분류하는 문제는 인공지능 분야에서 매우 어려운 일이었습니다. 왜냐하면, 강아지와 고양이를 구분하는 유일한 특징이 없을뿐더러, 있다고 하더라도 모든 견종에 포함되는 것은 아니기 때문이죠. 예를 들어, "고양이는 볼에 수염이 있다."라는 규칙으로 분류한다고 하면, 아래 사진과 같은 스핑크스 고양이는 강아지로 분류될 것입니다. 이처럼 유일한 특징을 찾기 어려워 불가능할 것이라고 예측했지만, 오늘날은 학부생 수준에서 배우고 있네요 ㅎㅎ (새삼 인공지능이 빠르게 발전하고 있다는 것이 느껴집니다.)

데이터 증강? Why?
이미지 분류 문제에서 매우 많이 활용되는 CNN을 통해 강아지와 고양이를 분류한다고 합시다. 그러면, 이 인공신경망의 정확도를 높이기 위해서는 은닉층을 많이 생성하여 층을 깊게 쌓거나 혹은 뉴런수를 늘리는 작업을 수행합니다. 그러나, 이 작업이 성공적으로 수행되려면 훈련 데이터가 충분해야 합니다. 만약, 훈련 데이터가 충분하지 않다면 Overfitting이 일어날 확률이 매우 높아지겠죠. 따라서, 인공신경망의 층을 깊이 쌓아 정확도를 올리는 일은 데이터의 수에 의존하게 됩니다. 하지만, 실제로 데이터를 취득하는 과정은 매우 어려운 작업 중 하나입니다. 따라서, 우리는 이미 가지고 있는 데이터를 약간 회전시키거나 반전시켜서 인공신경망에게 새로운 사진인 척 속이는 작업을 하는 것이죠. 글로 읽었을 때는 장난치는 것 같지만, 실제로는 약 10% 정도의 정확도 개선을 불러옵니다.
(정확도 향상 효과는 다음 포스팅에서 다루었으니 관심 있으시다면, 보시는 걸 추천드립니다.)
본론
지금부터는 직접 코드를 살펴보며, 데이터 증강 작업을 Sequential API로 구현해 보겠습니다.
해당 코드는 Google Colab 환경에서 작업하였습니다.
Data Load & Description
강아지와 고양이 사진이 들어있는 파일을 zip파일로 다운로드하고 unzip 해줍니다.
|
!pip install --upgrade --no-cache-dir gdown
import gdown
import zipfile
import os
if not os.path.isdir('cats_vs_dogs_small'):
gdown.download(id='1z2WPTBUI-_Q2jZtcRtQL0Vxigh-z6dyW', output='cats_vs_dogs_small.zip')
cats_vs_dogs_small = zipfile.ZipFile('cats_vs_dogs_small.zip')
cats_vs_dogs_small.extractall()
cats_vs_dogs_small.close()
|
데이터를 다운로드 했으니 테스트 삼아 훈련데이터에 존재하는 고양이 사진 25장을 출력해 보겠습니다.
|
import matplotlib.pyplot as plt
import matplotlib.image as image
plt.figure(figsize=(15,15))
for i in range(25):
plt.subplot(5,5,i+1)
img_path = f'./cats_vs_dogs_small/train/cat/cat.{i}.jpg'
img = image.imread(img_path)
plt.imshow(img)
plt.xticks([])
plt.yticks([])
plt.show()
|
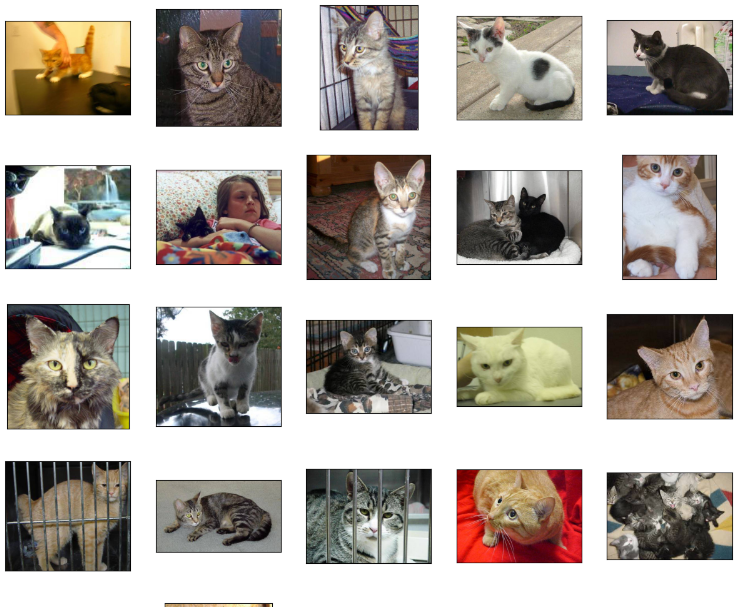
매우 귀여운 고양이 사진들이 출력됐습니다. 그러나, 왼쪽 위 2번째 줄의 2번째 사진을 보면, 사람과 같이 찍힌 이미지도 존재합니다. 우리에겐 noise로 작용하겠죠. 또한, 각 이미지의 해상도도 다릅니다.
Create Dataset
뒤에서 만들 Data Augmentation Layer에 이미지 데이터를 넣을 때에는 모든 이미지가 다 같은 해상도가 가져야 합니다. 따라서 모든 이미지가 같은 해상도를 가지게 만들고 훈련 데이터셋, 검증 데이터셋, 테스트 데이터셋을 만들어보겠습니다.
|
import pathlib
from tensorflow.keras.utils import image_dataset_from_directory
base_dir = pathlib.Path("cats_vs_dogs_small")
train_dataset = image_dataset_from_directory(
base_dir / "train",
image_size=(180, 180),
batch_size=32)
validation_dataset = image_dataset_from_directory(
base_dir / "validation",
image_size=(180, 180),
batch_size=32)
test_dataset = image_dataset_from_directory(
base_dir / "test",
image_size=(180, 180),
batch_size=32)
|
위 과정에서 image_size = (180,180)이라는 코드를 통해 모든 이미지는 (180,180,3)의 shape을 가지게 됩니다. 또한, batch_size를 지정했기 때문에 미니 배치 처리도 해주었습니다.
|
iterator = iter(train_dataset)
batch_1 = next(iterator)
|
위 코드를 통해 train_dataset을 순환 가능 객체로 만들어줍니다. 이 과정은 train_dataset의 이미지와 라벨을 분리하기 위해 사용됩니다. 우리는 아래에서 이미지를 출력할 것이기 때문에 그냥 train_dataset을 넣으면 아무것도 나오지 않게 되어 이 과정이 필요합니다. batch_1에는 0번째 index에는 이미지, 1번째 index에는 label을 들어있으며 label은 0이 cat, 1이 dog로 되어있습니다. 또한, 위에서 미니 배치 처리를 했기 때문에 batch_1에는 32장의 이미지가 들어있겠죠. 이제 모든 이미지가 다 같은 해상도로 바뀌었는지 출력하여 확인해 볼까요?
|
plt.figure(figsize=(15,30))
for i in range(32):
plt.subplot(8,4,i+1)
plt.imshow(batch_1[0][i]/255)
plt.xticks([])
plt.yticks([])
plt.show()
|
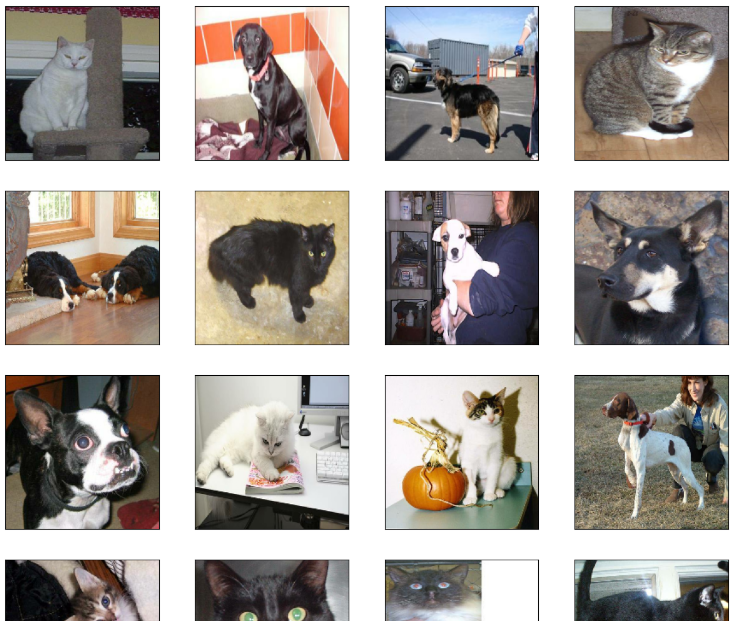
결과를 보니, 모든 해상도가 다 동일하게 잘 바뀌었네요! (위 결과는 dataset을 만들 때에 shuffle = True로 기본 설정되어 있기 때문에 다를 수 있습니다.)
DataAugmentation Layer
이제 모든 전처리가 끝났으니, 본격적으로 데이터 증강을 해보겠습니다.
|
import keras
data_augmentation = keras.Sequential(
[RandomFlip("horizontal"),
RandomRotation(0.1),
RandomZoom(0.2)])
|
Sequential API로 증강층을 구성하였으며, 각 층의 설명은 아래와 같습니다. 모두 랜덤 하게 설정하므로 어떤 이미지는 수행되고 어떤 이미지는 수행되지 않을 수 있습니다. 여기서, RandomFllip을 horizontal로 설정하였는데요, 이는 고양이와 강아지가 좌우로는 반전된 사진이 존재할 수 있지만, 거꾸로 매달려있는 경우는 없기 때문에 좌우로 설정한 것 입니다.
- RandomFlip: 좌우 반전을 원한다면 'horizontal', 상하 반전을 원한다면 'vertical'로 설정합니다.
- RandomRotation(0.1) : 랜덤 하게 -0.1 ×360° ~ 0.1 ×360°만큼 회전시킵니다.
- RandomZoom(0.2) : 랜덤 하게 상하로 -20% ~ 20% 확대
(증강 기법은 이 외에도 다양하게 존재합니다.)
Print Augmented Image
위에서 만든 batch_1의 첫 번째 고양이 이미지를 증강시켜서 출력해 보겠습니다.
원본 이미지를 출력하고 아래에 25장의 증강 이미지를 출력합니다.
|
import numpy as np
plt.imshow(img/255)
plt.xticks([])
plt.yticks([])
plt.show()
plt.figure(figsize=(12, 12))
for i in range(25):
augmented_img = data_augmentation(img[np.newaxis,:,:,:])
plt.subplot(5, 5, i + 1)
plt.imshow(augmented_img[0]/255)
plt.xticks([])
plt.yticks([])
plt.show()
|

위처럼 서로 다른 이미지가 출력됨을 확인할 수 있습니다! 같은 원리로 강아지와 MNIST 예제도 수행하게 되면, 각각 아래와 같이 출력됩니다.

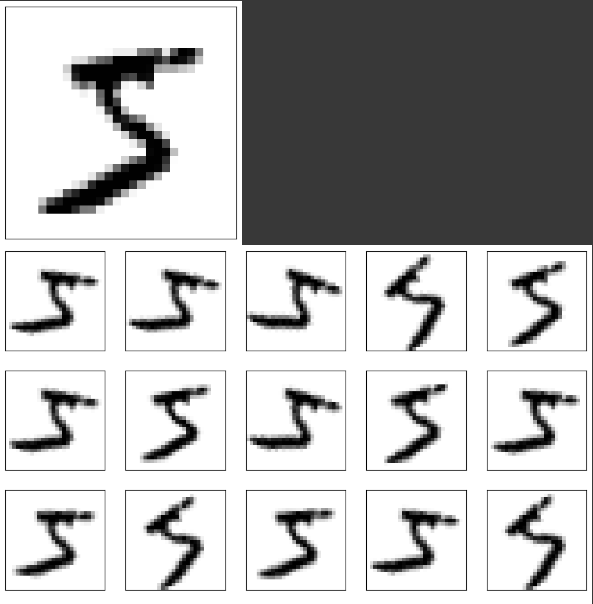
마치며..
오늘은 이렇게 데이터 증강 기법을 배웠습니다. 이 작업의 수행 효과(=정확도 향상)까지 쓰고 싶었는데, 글이 너무 길어질 것 같아 다음 글에 남기겠습니다. 궁금하신 분은 다음 글을 참고해 주세요! 오늘도 읽어주셔서 감사합니다.

'딥러닝' 카테고리의 다른 글
| [Sparse Coding] 희소 코딩 기법에 대한 그림을 통한 쉬운 설명 (0) | 2024.07.12 |
|---|---|
| [Data Preprocessing] Duplicate Cleaner 소개 및 사용법 (1) | 2024.07.03 |
| [ResNet] 예제를 통한 설명 및 함수형 API 구현하기 (1) | 2024.06.25 |
| [VGG16] 예제를 통한 transfer learning, fine-tuning 설명 (0) | 2024.06.24 |
| [Data Augmentation] 예제를 통한 데이터 증강 효과 설명 (0) | 2024.06.24 |



