
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Deep Learning
- Data Augmentation
- ResNet
- SRCNN
- Tableau
- VGG16
- 파이썬 구현
- kt디지털인재
- data analysis
- kt희망나눔재단
- 논문 리뷰
- 데이터과학
- cnn
- 데이터 분석
- 머신러닝
- VGG
- 논문리뷰
- object detection
- 장학프로그램
- Computer Vision
- super resolution
- 태블로 실습
- Semantic Segmentation
- 데이터 증강
- 딥러닝
- sparse coding
- 태블로
- 데이터 시각화
- 개 vs 고양이
- k-fold cross validation
- Today
- Total
기억의 기록(나의 기기)
[pycaret] 예제를 통한 사용법 소개 및 설명 본문
머신러닝 - Pycaret 소개
안녕하세요, 데이터과학을 전공하고 있는 황경하입니다.
최근에 프로젝트를 진행하며 모델 생성, 하이퍼파라미터 튜닝, 모델 성능 비교까지 한 번에 가능한 라이브러리를 새로 알게 되었는데요, 한 번 경험해 보고 너무 놀라서 바로 이렇게 블로깅을 하게 되었습니다. 그 라이브러리는 바로 Pycaret입니다! 바로 가시죠!
Pycaret이란?
Pycaret 공식 홈페이지에서는 "PyCaret은 본질적으로 scikit-learn, XGBoost, LightGBM, CatBoost, spaCy, Optuna, Hyperopt, Ray 등과 같은 여러 기계 학습 라이브러리 및 프레임워크를 둘러싼 Python wrapper입니다."라고 설명합니다. 이를 좀 더 쉽게 설명해 보겠습니다. 만약, 우리가 어떠한 데이터에 대한 여러 모델의 성능을 비교해보고 싶다고 합시다. 그러면, 사용하고자 하는 모델들을 하나하나 직접 구현하고 튜닝을 거쳐 최종 성능을 측정합니다. 그리고, 그 성능을 비교하여 최종 모델을 선택하겠죠. 이를 코드로 구현한다면, 수 십 줄의 코드가 나올 것입니다. 이 과정을 간단히 해주는 프레임워크가 바로 Pycaret입니다. 실습 코드를 보며 정말 그런지 확인해 보겠습니다.
실습 코드
실습 코드에서는 비교적 간단한 데이터를 이용하기 위해 유명한 Boston 데이터를 사용하겠습니다. Boston 데이터는 집 값에 미치는 요소들을 feature로 가지고 있으며, target 변수는 집 값입니다. 우리는 집 값을 예측하는 모델을 만들 것입니다.
1) Library Import
pycaret 라이브러리를 설치해 줍니다. (만약, catboost도 사용하고 싶다면, !pip install pycaret[full] 을 설치해 주세요.)
우리는 집 값을 예측하는 것이 목표이기에 regression 클래스의 method를 모두 불러와줍니다.
ISLP는 Boston 데이터를 불러오기 위해 설치합니다.
|
!pip install pycaret
!pip install ISLP
from pycaret.regression import *
from ISLP import load_data
|
2) Data 확인
Boston 데이터를 출력해 보죠!
|
Boston = load_data('Boston')
Boston |

3) model setup
시행 시마다 같은 결과를 보여주기 위해 seed를 설정합니다. CFG 클래스를 만들 때에 target에는 우리의 목표 변수가 들어가야 합니다. 우리는 집 값이 들어있는 컬럼인 'medv'로 설정해야겠죠?
|
import random
import os
import numpy as np
class CFG:
user_seed = 42
target = 'medv'
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
seed_everything(CFG.user_seed)
|
이다음에는 우리가 사용할 학습 환경을 설정해줍니다. 파라미터들은 굉장히 직관적입니다.
- data: 우리가 사용 할 데이터를 넣어줍니다. (단, 목표 변수를 포함한 데이터여야 합니다.)
- target: 앞서 정의한 CFG 클래스의 target으로 'medv' 변수를 타겟으로 정하겠다는 뜻입니다.
- normalize, normalize_method: 정규화를 진행할 것인지, 그리고 어떤 방법으로 정규화할 것인지를 결정합니다. (zsocre 외에도, minmax, maxabs, robust 방법이 존재합니다.)
- transformation: 데이터가 정규분포를 따르도록 변환합니다.
- ignore_features: 모델에 사용하지 않을 컬럼을 설정합니다.
- numeric_features: 연속형 데이터를 나열합니다.
- categorical_features: 범주형 데이터를 나열합니다. (우리 데이터는 rad, chas가 범주형 데이터입니다.)
- fold: k-fold CV 방법을 사용하기 때문에 fold를 지정해 줍니다. (최소 숫자는 2이며, fold는 반드시 설정해야 합니다.) K-fold CV에 대한 자세한 설명은 이곳을 참고해 주세요.
이 외에 더 자세한 설명은 공식홈페이지를 참고해 주세요!
|
my_model = setup(data=Boston,
target=CFG.target,
normalize=True, normalize_method='zscore',
transformation=False,
ignore_features = None,
numeric_features = ['crim', 'zn', 'indus', 'nox', 'rm', 'age', 'dis', 'tax', 'ptratio', 'lstat'],
categorical_features = ['rad', 'chas'],
fold = 5)
|
모델을 설정하면, 이와 같은 결과가 출력됩니다. 우리가 봐야 할 건, Target type이 Regression이 맞는지 확인해야 합니다.
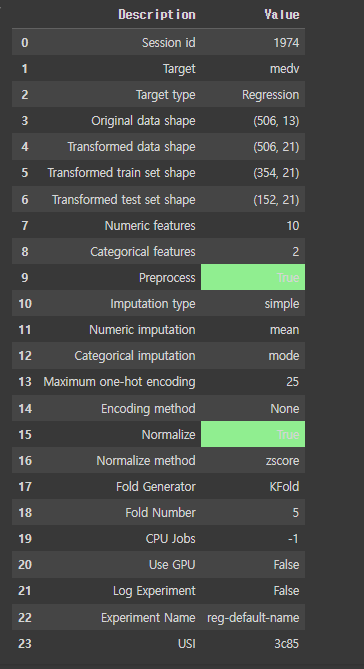
4) Compare model
model setup이 끝났다면, 본격적인 모델링이 가능해집니다. 우선, 여러 모델의 성능을 비교해 보죠!
단순히 코드 한 줄이면 됩니다.
|
compare_models()
|

이처럼 단 한 줄만에 여러 모델의 성능이 비교가 끝났습니다. 보시다시피, Gradient Boosting Regressor, Extra Trees Regressor, Random Forest Regressor, Extreme Gradient Boosting, Light Gradient Boosting Machine 이 5개의 모델이 가장 좋은 성능을 보입니다. 이미 낮은 MAE값을 보이지만, 이걸로 만족할 순 없습니다. 우리는 아직 하이퍼파라미터 튜닝을 거치지 않았으니까요. 여러 모델의 결과를 다 보여드리면, 글이 너무 길어질 것 같아 가장 성능이 좋은 gbr 모델로 예를 들어보겠습니다.
5) Create model
gbr 모델을 직접 생성해 보면, fold별 MAE 값들을 보여주며 최종적인 결과를 볼 수 있습니다. 이는 위에 compare_model을 진행했을 때 값과 동일합니다.
|
model_gbr = create_model('gbr')
|

이 외에도 이를 이용하여 시각화를 진행할 수 있습니다. 가장 성능이 좋은 gbr 모델을 plot 해보죠.


6) hyper parameter tunning
위 모델을 튜닝해 보겠습니다. 이 역시, 단 한 줄로 끝납니다.

하지만, 지금 보시다시피 오히려 성능이 떨어질 때도 존재합니다. 즉, 튜닝을 한다고 해서 늘 성능이 개선되는 것은 아니라는 거죠. 그럼 이 경우엔 어떻게 해야 할까요? tune_model에는 여러 파라미터가 존재합니다. 이 중 search_library 파라미터에 tune-sklearn , optuna, scikit-optimize가 존재하는데 이는 어떤 방법으로 하이퍼파라미터를 찾을지를 선택하는 것으로 이를 바꿔가며 시도해 보는 방법이 있습니다. 이외에도 직접 파라미터 탐색 범위를 지정하여 튜닝을 할 수도 있죠.
|
params = {"max_depth": np.random.randint(1, (len(boston.columns)*.85),20),
"max_features": np.random.randint(1, len(boston.columns),20),
"min_samples_leaf": [2,3,4,5,6]}
# tune model
tuned_dt = tune_model(dt, custom_grid = params)
|
이 예시처럼요!
|
print(model_tuned_gbr)
|
이 코드 실행 시 튜닝된 하이퍼파라미터를 확인할 수 있습니다.
7) Blending
튜닝을 해도 결과가 별로라면, 여러 모델을 혼합하여 사용할 수도 있습니다. 이를 Blending이라고 하는데요.
이 역시 코드가 굉장히 간단합니다. 우선, 가장 성능이 좋았던 두 모델을 Blending 해보겠습니다.
|
gbr = create_model('gbr')
et = create_model('et')
blender = blend_models(estimator_list = [gbr, et])
|

보시다시피, 성능이 더 개선되었습니다. Blending 효과가 있네요!
|
best_model = compare_models(n_select=5)
blender_5 = blend_models(best_model)
|
이런 방법도 가능합니다. compare_models를 통해 나온 모델별 성능 중 상위 5개를 선택하여 blending을 해주는 것이죠.

상위 5개 모델을 blending 한 결과, 모델을 하나만 사용했을 때보다 성능은 개선되었지만, 상위 2개를 blending 했을 때보다 성능이 좋지 않음을 알 수 있습니다. 이를 통해, 무조건 모델을 많이 blending 한다고 해서 성능이 올라가는 것은 아님을 직접 확인하였습니다.
마치며..
쓰다 보니, 글이 길어진 것 같습니다. 오늘은 DACON에 공유된 코드들을 살펴보다 새롭게 알게 된 pycaret에 대해서 포스팅해 봤습니다. 저는 처음 사용했을 때, 너무 충격을 받아서 바로 포스팅해야겠다는 생각을 했습니다. 다음에는 더 흥미로운 주제로 돌아오겠습니다. 읽어주셔서 감사합니다.

'머신러닝' 카테고리의 다른 글
| [K-fold cross validation] 기법 설명 및 활용 (0) | 2024.05.10 |
|---|
